

#15952 closed bug (fixed)
Kdl when running openssl tests
| Reported by: | pulkomandy | Owned by: | ambroff |
|---|---|---|---|
| Priority: | normal | Milestone: | R1/beta2 |
| Component: | Network & Internet/TCP | Version: | R1/Development |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | #11349 | |
| Platform: | All |
Description (last modified by )
Haikuporter --test openssl-1.1.1g crashes. Screenshot attached. Seems reproductible.
Attachments (2)
{kind=link}
{kind=link}
Change History (20)
by , 4 years ago
| Attachment: | DSC_1878.JPG added |
|---|
comment:1 by , 4 years ago
| Description: | modified (diff) |
|---|
comment:2 by , 4 years ago
comment:3 by , 4 years ago
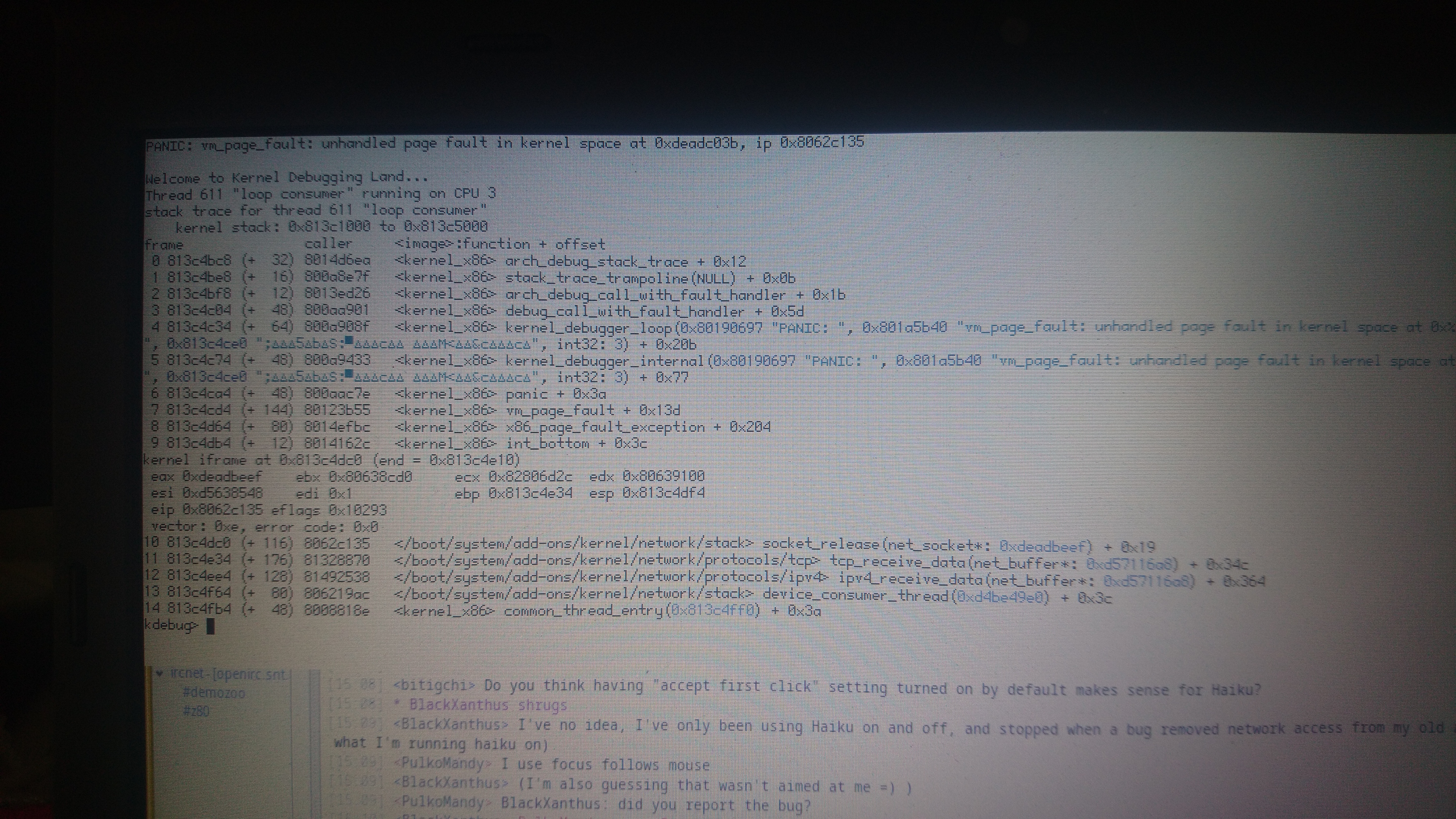
I don't see anything too suspicious in it. In this case, the socket is deleted while still in the hash map. Which raises the question of when a socket is deleted, I'd expect this to happen shortly after the application close()s it (there is no other call after close to free the memory), maybe after some TCP cleanup or something. So, is it safe to reuse a socket as 13927 now allows? Or do we end up operating on a freed socket?
I didn't investigate the openssl tests, it would be nice to know at least which test is failing so we can see what it's doing.
comment:4 by , 4 years ago
This might indeed be the same kind of bug as #13927. I'm not at my computer now but I can try to reproduce this and investigate this afternoon.
comment:5 by , 4 years ago
Yup I can reproduce this pretty easily. It doesn't happen 100% of the time for me but it is often enough that I can trigger it after a few tries.
The output of the test suite isn't exactly the same every time the KDL happens, but it seems to be happening when the test/recipes/70-* tests are running. I added some tracing and got some better output but I need to spend some more time analyzing it to fully understand what is going on.
I'll try to see if I can figure out which exact test is triggering this while I read through the code some more.
by , 4 years ago
| Attachment: | net_socket-trace.log added |
|---|
syslog with tracing enabled in src/add-ons/kernel/network/stack/net_socket.cpp
comment:6 by , 4 years ago
| Owner: | changed from to |
|---|---|
| Status: | new → in-progress |
comment:7 by , 4 years ago
I've made a little progress on this today.
I don't yet have a minimal repro in the form of a regression test, but this triggers the problem often enough for me (from the test/recipes directory of the openssl build directory).
HARNESS_VERBOSE=1 TOP=$(pwd)/../.. perl -I$(pwd)/../../util/perl 70-test_key_share.t
The scenario that causes the panic is that the remote endpoint is sending an RST/ACK, acknowledging a segment and signaling that the connection should be closed.
source port: 42302 dest port: 43335 sequence: 4264473 ack: 4263475 flags: RST ACK window: 65535 urgent offset: 0 buffer 0xffffffff92057728, size 0, flags 0, stored header 0, interface address 0xffffffff821373e8 source: 127.0.0.1:42302 destination: 127.0.0.1:43335
This is handled by tcp_receive_data(net_buffer*), which looks up the TCPEndpoint for this TCP session and calls TCPEndpoint::SegmentReceive(), and then calls release_socket() on the socket to drop its reference count.
TCPEndpoint* endpoint = endpointManager->FindConnection(
buffer->destination, buffer->source);
if (endpoint != NULL) {
segmentAction = endpoint->SegmentReceived(segment, buffer);
gSocketModule->release_socket(endpoint->socket);
} ...
The problem is that TCPEndpoint::SegmentReceived() also degrements the reference count by calling release_socket().
if ((fFlags & (FLAG_CLOSED | FLAG_DELETE_ON_CLOSE))
== (FLAG_CLOSED | FLAG_DELETE_ON_CLOSE)) {
locker.Unlock();
gSocketModule->release_socket(socket);
}
So TCPEndpoint::SegmentReceive() frees the socket and then the caller tries to access it.
I'm going to try to turn this into a regression test and then clean this up.
comment:8 by , 4 years ago
I guess it's also a good idea to verify that the RST/ACK is getting sent by the other side appropriately.
comment:9 by , 4 years ago
OK I've got a pretty good understanding of this now.
When a TCP session is closed, the socket is put into a TIME_WAIT state for a duration of 2MSL, or, twice the max segment lifetime.
void
TCPEndpoint::_UpdateTimeWait()
{
gStackModule->set_timer(&fTimeWaitTimer, TCP_MAX_SEGMENT_LIFETIME << 1);
T(TimerSet(this, "time-wait", TCP_MAX_SEGMENT_LIFETIME << 1));
}
This is called by TCPEndpoint::_EnterTimeWait, which is called by TCPEndpoint::_Receive() when an appropriate segment flag is received signaling session close, and by TCPEndpoint::Free() which is called when userspace calls close(fd).
TCP_MAX_SEGMENT_LIFETIME is 60 seconds, so the socket will be put into TIME_WAIT state for 120 seconds, which is a standard amount of time. So far so good.
The TIME_WAIT state is appropriate. If another socket is opened with the same port, and the network then later delivers a delayed segment from the previously closed session that is within the recipients receive window, then that could be lead to problems. So the idea is to prevent that port from being used until it is guaranteed that any delayed segments from the previously closed session will be discarded.
When this timer expires after 120 seconds, assuming that the socket is actually in a closed state, the socket will be freed by dropping its reference count with gSocketModule->release_socket(net_socket*).
TCPEndpoint::_TimeWaitTimer(net_timer* timer, void* _endpoint)
{
TCPEndpoint* endpoint = (TCPEndpoint*)_endpoint;
T(TimerTriggered(endpoint, "time-wait"));
MutexLocker locker(endpoint->fLock);
if (!locker.IsLocked())
return;
if ((endpoint->fFlags & FLAG_CLOSED) == 0) {
endpoint->fFlags |= FLAG_DELETE_ON_CLOSE;
return;
}
locker.Unlock();
gSocketModule->release_socket(endpoint->socket);
}
Now with that background, the comment I made a couple of days ago makes a little more sense. tcp_receive_data is called with a new buffer from the NIC, and this segment has the RST/ACK flags set. So the other side is acknowledging a segment and closing the connection.
The TCPEndpoint for this session address/port is looked up and found. EndpointManager::FindConnection increments the reference count for the socket with gSocketModule->acquire_socket(net_socket*). Then it calls SegmentReceived() on the endpoint and, afterwards, drops the reference count back down with gSocketModule->release_socket(net_socket*).
TCPEndpoint* endpoint = endpointManager->FindConnection(
buffer->destination, buffer->source);
if (endpoint != NULL) {
segmentAction = endpoint->SegmentReceived(segment, buffer);
gSocketModule->release_socket(endpoint->socket);
}
TCPEndpoint::SegmentReceived handles a bunch of different states, such as listening for new connections (accept() called) or receiving segments mid session establishment, or just receiving segments when a session is already established. Here a session is established so it just calls TCPEndpoint::_Receive(tcp_segment_header&, net_buffer*).
This function is super complicated because the TCPEndpoint is a state machine and this function handles many of the state transition. The relevant state starts with fState = FINISH_SENT, meaning that a FIN had been sent to the peer, and the segment being handled is a RST/ACK acknowledging that FIN. The receipt of this RST/ACK transitions this socket into fState = FINISH_ACKNOWLEDGED. Then later in the same invocation of _Receive near the end of the function this state is handled by entering TIME_WAIT state.
if ((segment.flags & TCP_FLAG_FINISH) != 0) {
if (fState != CLOSED && fState != LISTEN && fState != SYNCHRONIZE_SENT) {
...
// other side is closing connection; change states
switch (fState) {
case FINISH_ACKNOWLEDGED:
fState = TIME_WAIT;
T(State(this));
_EnterTimeWait();
break;
...
}
}
}
}
...
Now _EnterTimeWait() is called and the socket is transitioned into TIME_WAIT state for cleanup in 120 seconds. But there are a couple of problems here. At this point we're at tcp_receive_data() -> TCPEndpoint::SegmentReceived() -> TCPEndpoint::_Receive() -> TCPEndpoint::_EnterTimeWait().
void
TCPEndpoint::_EnterTimeWait()
{
TRACE("_EnterTimeWait()");
if (fState == TIME_WAIT) {
_CancelConnectionTimers();
if (IsLocal()) {
// we do not use TIME_WAIT state for local connections
fFlags |= FLAG_DELETE_ON_CLOSE;
return;
}
}
_UpdateTimeWait();
}
So the first interesting thing here is that there is a special branch for TCP sessions over the loopback interface. Since we don't have an unreliable network to worry about, the idea is that we don't have to worry about TIME_WAIT state and can just make the (address, port) available right away. In theory that makes sense, although I'm not sure if other operating systems do this.
Problem #1 is that even if this isn't a connection over the loopback interface and we call _UpdateTimeWait(), that should probably increment the reference count of the socket, since the TIME_WAIT timer is assuming ownership of that socket. This happens for TCPEndpoint::Free() which call _EnterTimeWait(), but not TCPEndpoint::_Receive. I'm not convinced that all paths which call _EnterTimeWait() on non-local TCP sessions actually leave the TIME_WAIT timer with its own reference.
Problem #2 is that for the local connection optimization where TIME_WAIT is skipped, the FLAG_DELETE_ON_CLOSE flag is set. We're still in tcp_receive_data() -> TCPEndpoint::SegmentReceived() -> TCPEndpoint::_Receive() -> TCPEndpoint::_EnterTimeWait(), and tcp_receive_data() has incremented the reference count of the socket once.
When _EnterTImeWait() and _Receive() return, there is a special branch in TCPEndpoint::SegmentReceived() for that FLAG_DELETE_ON_CLOSE just before the function returns.
if ((fFlags & (FLAG_CLOSED | FLAG_DELETE_ON_CLOSE))
== (FLAG_CLOSED | FLAG_DELETE_ON_CLOSE)) {
locker.Unlock();
gSocketModule->release_socket(socket);
}
return segmentAction;
So the state set in _EnterTimeWait() triggers a decrement of the socket's reference count further up the call stack. In the case of this KDL, the reference count is now set to 0 by the release_socket(net_socket*) call, which causes the socket to be deleted.
inline bool
WeakPointer::Put()
{
if (atomic_add(&fUseCount, -1) == 1) {
delete fObject;
return true;
}
return false;
}
This returns to the caller, tcp_receive_data(), which immediately calls release_socket(net_socket*) as well, since it incremented the reference count with acquire_socket(net_socket*) by looking up the TCPEndpoint from EndpointManager::FindConnection().
segmentAction = endpoint->SegmentReceived(segment, buffer); gSocketModule->release_socket(endpoint->socket);
And panic.
So there is obviously a missing call to gSocketModule->acquire_socket(endpoint->socket) here. I think it is in TCPEndpoint::_Receive around the code which calls _EnterTimeWait().
Another bit of safety that can be added here is that gSocketModule->release_socket(net_endpoint*) returns true if the call resulted in the socket being deleted. So TCPEndpoint::SegmentReceived can just be modified to return both the segment action *and* whether or not the segment was deleted, so tcp_receive_data() knows whether or not it needs to release its reference.
I have a local change I'm testing to fix this, but getting this wrong means sockets will get leaked, so I'm doing some more careful testing and reading through the code to make sure I didn't make things worse.
comment:10 by , 4 years ago
Would it make more sense to just have a kind of "SocketHolder" class which takes care of acquiring/releasing references as needed, so that we do not have to worry about all these reference-counting bugs? (Does that already exist and is it just not being used here?) That sounds like the cleanest and best solution.
comment:11 by , 4 years ago
That sounds like a great idea. I'm not sure how easy it is to do at the moment without making huge changes to the rest of the API. net_timer() for example doesn't capture any state, but for a SocketHolder RAII class we'd need to change that API to allow capturing some additional state by value.
I'll think about it for a bit.
comment:12 by , 4 years ago
Well, net_timer passes in a void* data which points to a TCPEndpoint, yes? So wouldn't we be using the TCPEndpoint's SocketHolder?
comment:13 by , 4 years ago
Ah yup you're right. I actually meant to say set_timer but I hadn't looked at the rest of the timer API yet. I see it now.
Good idea.
comment:14 by , 4 years ago
| Blocking: | 11349 added |
|---|
comment:15 by , 4 years ago
I finally had more Haiku time yesterday and spent some time trying to prototype this. I'm still working on it, but I think in the mean time we can push a simpler change that would fix this kernel panic and is safer to include in r1beta2, and that is to just get rid of the special branch to skip TIME_WAIT for local sockets.
I don't actually see any precedent for skipping TIME_WAIT and other operating systems don't do it from what I can tell, and I'm not even certain its safe. Getting rid of that will get rid of the problem for now while we make bigger changes in a more careful manner.
I'm about to submit a patch that I've been stress testing since last night and it seems to be holding up just fine.
comment:18 by , 4 years ago
| Milestone: | Unscheduled → R1/beta2 |
|---|
Assign tickets with status=closed and resolution=fixed within the R1/beta2 development window to the R1/beta2 Milestone
(final time)
#13927 which was fixed in January may be somehow relevant here?