

#14674 closed bug (fixed)
StyledEdit Misreads UTF-8 Files as Something Else
| Reported by: | AGMS | Owned by: | nobody |
|---|---|---|---|
| Priority: | normal | Milestone: | R1/beta2 |
| Component: | Applications/StyledEdit | Version: | R1/Development |
| Keywords: | Encoding | Cc: | agmsmith@… |
| Blocked By: | Blocking: | ||
| Platform: | All |
Description
When reading the BeShare BeShareDocs.txt file, which is UTF-8 and reads fine in BeOS and Linux, StyledEdit mangles accented characters. Is it picking the wrong encoding? Or is it something else going on?
By the way, the Encoding menu in the open file panel doesn't let you pick UTF-8, you get the default option which maybe autodetects. Perhaps have a separate "auto" menu item so you can force it to use UTF-8.
Attachments (5)
{kind=link}
{kind=link}
Change History (23)
by , 6 years ago
| Attachment: | BeShareDocs.txt added |
|---|
by , 6 years ago
| Attachment: | StyledEditEncodingBug.png added |
|---|
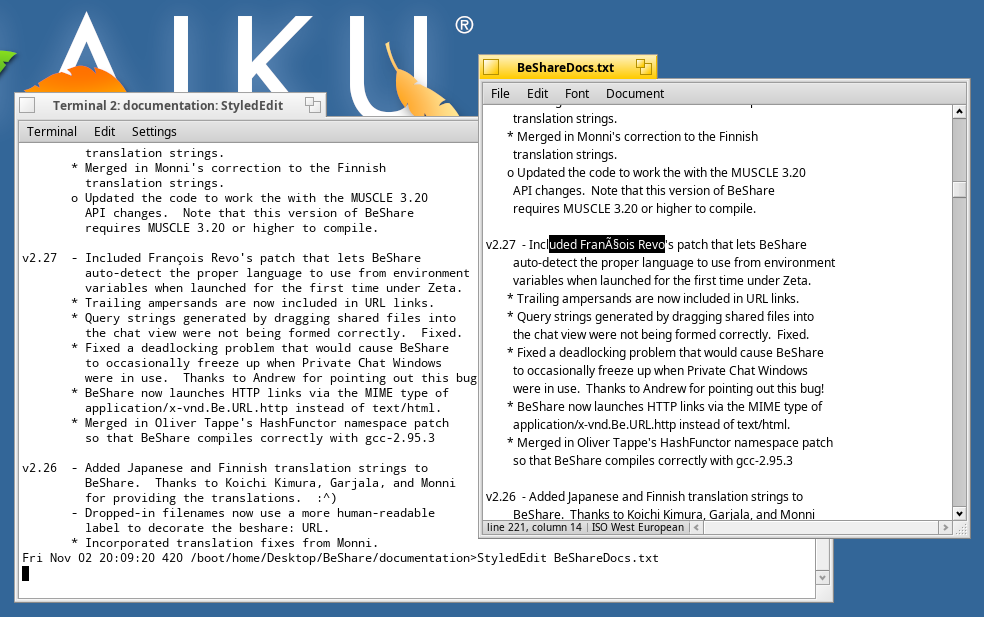
Screen shot comparing output in Terminal of the file (it's fine) with StyledEdit after loading the same file, which gets mangled (highlighted in inverse video).
comment:1 by , 6 years ago
Further investigation by Pete shows something funny is also happening with the be:encoding attribute. It is sometimes an int32 set to 65535, at other times it is a text string naming the ISO encoding.
comment:2 by , 6 years ago
Some more observations:
If you create a new text file, StyledEdit doesn't give you any encoding choice (all greyed out). When you save it, it gets tagged with the '65535' encoding -- which apparently equates to UTF-8.
If you load that or any other file back into StyledEdit, the encoding menu list is enabled, but trying to select anything but the already-selected choice doesn't work!
If a file already has a valid be:encoding attribute (as text rather than integer!) that will become StyledEdit's choice You can use addattr to set the attribute, and StyledEdit will accept it.
This all seems rather useless... (:-/) If you're creating a text it might well be for some purpose that requires, say, ISO-8859 encoding. So you should be given that initial choice. Conversely, if a file happens to have acquired the wrong encoding (as BeShareDocs.txt had, sokmehow), you need to be able to fix it!
comment:3 by , 6 years ago
The encoding to use when saving a file can be selected in the save filepanel. Likewise when opening a file. Which makes me wonder what's the point of having an encoding menu in the main window in the first place.
To keep things manageable, the internal encoding should always be utf-8 (or some other unicode representation), encoding is a file io operation, unless we want to restrict which characters can be entered to make sure a file can be faithfully represented in a given encoding. Also, loading then saving a file should of course preserve the existing encoding. I think these are the reason why StyledEdit keeps an internal notion of encoding even when not doing file IO.
I had a look through the sourcecode and I didn't find any place where we make an attempt to guess the encoding. Either I missed it (this involves BTextView, BTranslationUtils, and a bunch of other things), or it's missing altogether and should be added. I'm not sure how we end up deciding on ISO_8859, if in doubt, i'd say we should rather assume UTF-8 these days.
by , 6 years ago
| Attachment: | Windows.txt added |
|---|
Similar characters to the UTF-8 file, but saved as Windows-1252 (equiv to ISO-8859-1)
comment:4 by , 6 years ago
It turns out I was confused by using two different revs of StyledEdit. My work partition is about 4 years old, but I initially tested in my latest hrev51670 from last December. The differences weren't obvious, but I think I have them sorted now.
I created some short test files: UTF8.txt, ascii.txt, and Windows.txt (attached). I initially stripped them of all attributes, then loaded them into (both versions of) StyledEdit.
My older version behaves fairly sanely. If I load either UTF8.txt, or ascii.txt, they are displayed correctly. If I quit without re-saving, no encoding attribute is added. If I save, the numeric attribute 65535 gets added.
If I load Windows.txt, with its non-Unicode characters, the attribute gets immediately set to 'iso-8859-1' (no saving required).
The new version is just weird. The attribute is set on loading in all cases (I never re-saved), but totally arbitrarily! Here's what I got with "catattr be:encoding *.txt", immediately after loading each into SE, with no saving:
UTF8.txt : string : UTF-8 Windows.txt : string : ISO-8859-1 ascii.txt : string : ISO-8859-2 BeShareDocs.txt : string : ISO-8859-1
Notice that a) UTF8.txt and BeShareDocs.txt, which have pretty much the same extended characters, get differerent encodings, and b) it thinks ascii.txt -- which has no extended characters -- is East European!! (BTW I did truncate all those strings as displayed by cataddr, because they are not null-terminated and get trailing garbage. Attribute length is correct)
This all seems to show that it is at least trying somehow to decipher the encoding, but it did rather better a few years ago!
I agree that the main window menu seems superfluous -- especially as it's not a selectable menu! (I'd never really noticed the Save Panel one! The one in the Load Panel, BTW, is ignored if be:encoding is set. Not sure if that's correct behaviour.)
How about replacing the main menu with a field in the menubar that displays the encoding used?
follow-up: 6 comment:5 by , 6 years ago
There is already a field that displays the encoding at the bottom next to the scrollbar.
It would help to know the hrev for your "about 4 years old" partition. It's possible the encoding detection was reworked to use ICU, but I don't remember when I did that.
comment:6 by , 6 years ago
Replying to pulkomandy:
There is already a field that displays the encoding at the bottom next to the scrollbar.
Oh, yeah -- I see. It only appears for non-UTF8 text, so it never showed up for me. I'd say the menu should definitely go, then.
It would help to know the hrev for your "about 4 years old" partition. It's possible the encoding detection was reworked to use ICU, but I don't remember when I did that.
It's hrev50180.
comment:7 by , 6 years ago
There were a couple of bugs which might have affected this which were fixed in hrev52522.
comment:10 by , 5 years ago
Problem fixed in https://review.haiku-os.org/c/haiku/+/2628
And I can now remove BeShareDocs.txt from my Desktop, I had it there a reminder about this for a year and a half.
comment:11 by , 5 years ago
I think that StyledEdit should just use UTF-8 by default. Even if text has only ASCII characters, non ASCII characters can be typed.
comment:12 by , 5 years ago
It always has used UTF-8 by default. It just was poor at indicating that fact! Thanks for fixing, Adrien.
comment:14 by , 5 years ago
The "fix" seems entirely arbitrary. When the next bug report comes along where the UTF8 char appears at an offset of 8193, we bump the buffer size to 16k?
comment:15 by , 5 years ago
I agree, but I also don't see a better solution.
We have some things we can do:
- ICU reports a "confidence" on its guess, which we could check, but the documentation says the values are somewhat arbitrary, so some experimentation is needed to decide which value means "ok, I actually detected something"
- What to do when the confidence is low? Default to UTF8? Current version of ICU seems to default to ISO-8859-15 which is a strange choice, this could be fixed in newer ICU versions however (I plan to update ours for gcc8 after beta2 is shipped)
- ICU documentation does mention that their algorithm works better on larger pieces of text. 2 kilobytes is just one screen of 80x25 terminal worth of text, or about half a printed page, that's just not enough for reliable detection. The ICU docs do mention that the algorithm does not work well for short pieces of text, however they give no hint about what "short" means.
- I thought of reading more chunks and feeding them to the detector until the confidence increases, but there doesn't appear to be an API to work with a stream, only a fixed buffer. I also considered trying the detector on multiple 2K blocks until the confidence increases, but there is the risk that an UTF8 character is on the boundaries of 2 blocks and that would break the detection, so extra care is needed (which we can't really do until we know the encoding, to know how to safely break the text). Also, the way the translator is structured makes it more complex because it wants to reuse the same buffer for this detection, and then for the translation, to reduce disk access and not need to re-read the start of the file.
I think whatever we try, there will always be detection errors (and even if there are not, there will be files accidentally mixing multiple encodings). This is why StyledEdit has menus allowing you to override the encoding detection in case it gets it wrong.
comment:16 by , 5 years ago
What to do when the confidence is low? Default to UTF8?
Yes. UTF-8 should be used if another encodings are not detected. Maybe encoding detection should be not used at all.
This is why StyledEdit has menus allowing you to override the encoding detection in case it gets it wrong.
Document > Text encoding menu have no effect. Encoding menu in file open dialog is also not working.
comment:17 by , 5 years ago
Assign tickets with status=closed and resolution=fixed within the R1/beta2 development window to the R1/beta2 Milestone
comment:18 by , 5 years ago
| Milestone: | Unscheduled → R1/beta2 |
|---|
The sample file with accented characters in the credits section. Look at the notes for version 2.27 for example, where François's name gets mangled upon loading.