

#18535 closed bug (fixed)
[UNIX datagram sockets] Use-after-free in socket_notify
| Reported by: | kohlschuetter | Owned by: | axeld |
|---|---|---|---|
| Priority: | critical | Milestone: | R1/beta5 |
| Component: | Network & Internet/UDP | Version: | R1/Development |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | ||
| Platform: | All |
Description
While running some AF_UNIX datagram tests, I noticed the kernel sometimes (but not always) fails to acquire a spinlock.
The process locks up, and the tests time out.
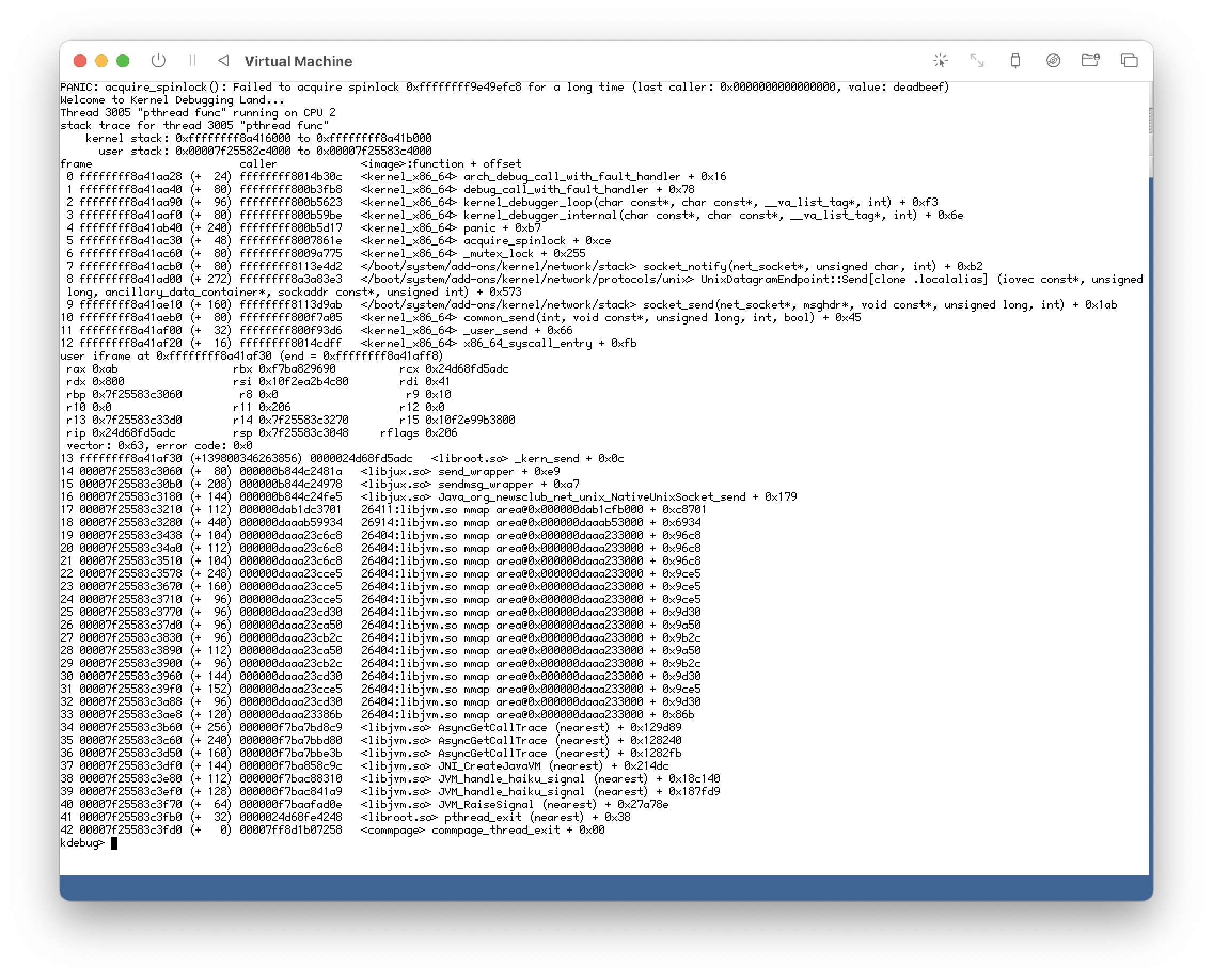
When I "kill -9" the process during that time, I get a kernel panic. Screenshot attached.
I'm running Haiku hrev57177 on amd64 with qemu on an M1 Max MacBook Pro.
Attachments (6)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (42)
by , 16 months ago
| Attachment: | Screenshot 2023-08-03 at 13.39.43.png added |
|---|
by , 16 months ago
| Attachment: | junixsocket-selftest-2.7.0-SNAPSHOT-jar-with-dependencies.jar added |
|---|
custom junixsocket selftest jar, with precompiled JNI library included for Haiku OS x86_64
by , 16 months ago
| Attachment: | Screenshot 2023-08-03 at 15.28.49.png added |
|---|
Effect of kernel spinlock hang before panic
comment:1 by , 16 months ago
Steps to reproduce: (on x86_64, verified with hrev57177)
# Prerequisites: # 1. Install Java: pkgman install openjdk11 # 2. Download attached junixsocket-selftest jar
Run the following command:
/system/lib/openjdk11/bin/java -Dorg.newsclub.net.unix.throughput-test.gracetime.seconds=600 -jar junixsocket-selftest-2.7.0-SNAPSHOT-jar-with-dependencies.jar
This will run several selftests for the "junixsocket" Java/JNI library. The tests may (not always) hang at ThroughputTest.testDatagramChannel or ThroughputTest.testDatagramChannelNonBlocking.
If this occurs, screen redrawing may fail (see attached screenshot), eventually leading to a kernel panic. "kill -9" on the process may or may not fail or immediately trigger a kernel panic.
Moreover, once the kernel panic is encountered, trying to "reboot" from the kernel debugger does not work.
comment:3 by , 16 months ago
| Keywords: | panic removed |
|---|---|
| Priority: | critical → high |
comment:4 by , 16 months ago
FWIW I cannot reproduce this problem in VMware on Windows (4 virtual cores):
+-- ThroughputTest [OK] | +-- testDatagramChannel() [OK] | +-- testDatagramChannelDirect() [OK] | +-- testDatagramChannelNonBlocking() [OK] | +-- testDatagramChannelNonBlockingDirect() [OK]
I reran the tests multiple times, never hung.
comment:5 by , 16 months ago
"Failed to acquire spinlock for a long time" inside mutex_lock should absolutely never occur; if it does this likely either signifies memory corruption or the other core that owns the spinlock has somehow stalled in a place it should not have.
It may be possible to get KDL backtraces of the other cores to see where they're at. If one of them looks like they might own this spinlock, then determining why that core holds it for so long is the next step.
by , 16 months ago
| Attachment: | Screenshot 2023-08-03 at 18.00.03.png added |
|---|
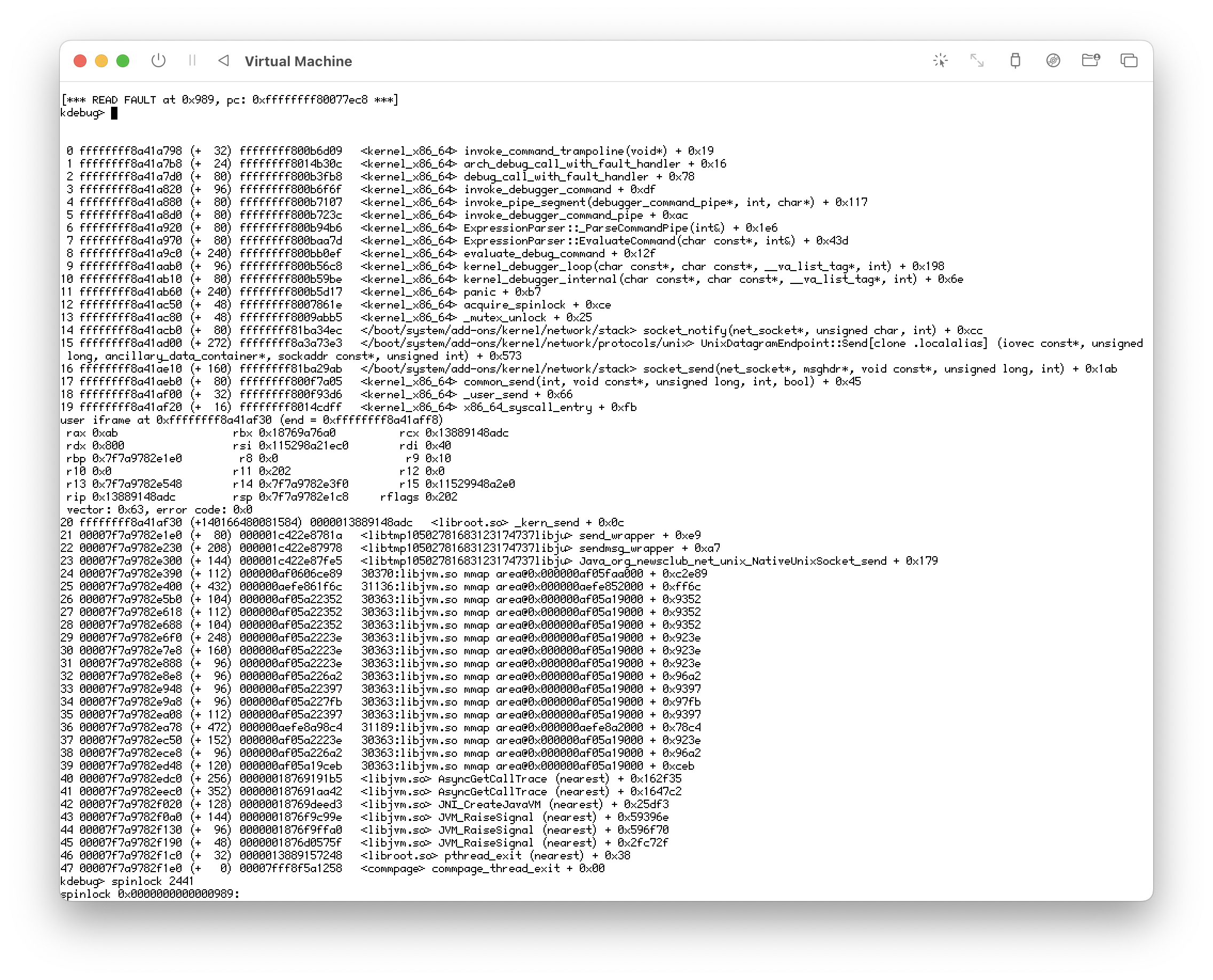
calling "spinlock" on blocked thread in kernel debugger
comment:6 by , 16 months ago
The "spinlock" command must be run on a pointer, not a thread. Furthermore the interesting part will be the backtrace of whatever the threads running on other cores are doing. And if this is a QEMU VM, you can get KDL output via serial, and upload as text instead of screenshots.
comment:7 by , 16 months ago
I can reproduce this issue relatively easily with my setup right now (using qemu-x86_64-softmmu from UTM 4.2.5), will try with single-threaded in a moment.
Here is some more information from the kernel debugger.
After typing "where" to show the crash info, note the Thread ID (e.g., 2441). Type "spinlock 2441" (replace with actual thread ID)
result is "READ FAULT at 0x96b".
Does this help clarify what's going on?
Is there anything else I should type in the debugger? How can I find the other thread making use of the lock?
comment:8 by , 16 months ago
@waddlesplash: When running the java code, did you encounter a line near the end saying "AF_UNIX datagram support is buggy" ... (important: "datagram")? If so, then the code caught the bug. This line should not occur.
What strikes me as odd is that it only fails on AF_UNIX datagrams, not sockets. Since that code is quite fresh, I wonder if eyeballing the changes around UnixDatagramEndpoint would reveal anything suspicious ... ?
comment:9 by , 16 months ago
I see this:
IMPORTANT: AF_UNIX support is buggy in this HaikuOS release; see https://dev.haiku-os.org/ticket/18534 IMPORTANT: "With issues": Please carefully check the output above; the software may not be able to do what you want.
but it doesn't say "datagram".
I am running hrev57188, just before the fix for #18534. I'm going to build the latest master in a moment and see what happens then.
(Also, the OS is called "Haiku" not "HaikuOS".)
comment:10 by , 16 months ago
That line is for the other bug I reported. Can you try running Haiku from within qemu? Maybe we're hitting a qemu-specific issue?
HaikuOS -> Haiku: renamed in junixsocket main!
comment:11 by , 16 months ago
Now running on latest master. This happens:
Failures (2):
JUnit Jupiter:SocketPairTest:testDatagramPair()
MethodSource [className = 'org.newsclub.net.unix.domain.SocketPairTest', methodName = 'testDatagramPair', methodParameterTypes = '']
=> org.opentest4j.AssertionFailedError: expected: <null> but was: <org.newsclub.net.unix.AFUNIXSocketAddress[path=\x000004a]>
org.newsclub.net.unix.SocketPairTest.testDatagramPair(SocketPairTest.java:148)
java.base/java.lang.reflect.Method.invoke(Method.java:566)
java.base/java.util.ArrayList.forEach(ArrayList.java:1541)
java.base/java.util.ArrayList.forEach(ArrayList.java:1541)
JUnit Jupiter:SocketPairTest:testSocketPair()
MethodSource [className = 'org.newsclub.net.unix.domain.SocketPairTest', methodName = 'testSocketPair', methodParameterTypes = '']
=> org.opentest4j.AssertionFailedError: expected: <null> but was: <org.newsclub.net.unix.AFUNIXSocketAddress[path=\x000004c]>
org.newsclub.net.unix.SocketPairTest.testSocketPair(SocketPairTest.java:95)
java.base/java.lang.reflect.Method.invoke(Method.java:566)
java.base/java.util.ArrayList.forEach(ArrayList.java:1541)
java.base/java.util.ArrayList.forEach(ArrayList.java:1541)
comment:12 by , 16 months ago
Can you try running Haiku from within qemu? Maybe we're hitting a qemu-specific issue?
If anything I wonder if we are hitting a macOS-specific issue (e.g. #15105 and similar issues, which only seemed to happen in Parallels on macOS.) But yes, I can test in QEMU with software emulation.
comment:13 by , 16 months ago
The errors in SocketPairTest can be ignored; they are fallout from #18534. Some assumptions from other platforms still didn't match for Haiku. I'm updating the provided selftest jar to accommodate.
With the new selftest, we can add some more logging to the code.
/system/lib/openjdk11/bin/java -Dselftest.haikuBug18535=dump -jar junixsocket-selftest-2.7.0-SNAPSHOT-jar-with-dependencies.jar
If we hit the bug, a verbose exception stack trace is shown. When we look at the "Cause by:" section, we see that "send" in native code is timing out while trying to send some datagram over AF_UNIX (which matches what we later see with the kernel panic, which we don't always get).
Can you verify this behavior (e.g., by adding some instrumentation around the "send" syscall?)
by , 16 months ago
| Attachment: | junixsocket-selftest-2.7.0-SNAPSHOT-jar-with-dependencies.2.jar added |
|---|
(version 2) custom junixsocket selftest jar, with precompiled JNI library included for Haiku OS x86_64
comment:14 by , 16 months ago
There are no failures running that testsuite for me.
Note that a "send" call timing out is a completely different matter than "failed to acquire spinlock for a long time". The latter will always be a panic; there is no way for this error to percolate upwards and become an ETIMEDOUT/EWOULDBLOCK. That would come from somewhere completely different.
comment:15 by , 16 months ago
The send is not timing out as in "returns an errno != 0". It's just sitting there, hanging, and then unit test code (which runs in a separate thread) decides it's been waiting too long and throws an exception.
comment:16 by , 16 months ago
Again, that doesn't happen here. There are no exceptions or stacktraces.
I actually had a JVM crash (SIGSEGV) occur during one run here while testing in QEMU but it seems to be unrelated to this entirely.
I ran the testsuite on QEMU, it all works fine there (of course it's much slower than in VMware due to software emulation). Here's the output of "time":
real 0m35.989s user 0m50.265s sys 0m8.489s
comment:17 by , 16 months ago
For a bit more explanation of the panic, since this is looking more like some sort of problem in QEMU or macOS: the panic happens when it takes "too long" to acquire a spinlock. In general, spinlocks are supposed to be held for very short periods of time. In particular, the mutex spinlocks are only held during the critical phase of lock wait or unlock; as soon as a "waiter" for a thread has been added to the lock, the thread releases the spinlock and goes into "wait" state. No mutex's spinlock should ever take any serious amount of time to acquire, as a result.
So, there are a few possibilities, to elaborate on what I said above: the spinlock's state could have become corrupted, and it "looks" locked but is not actually held by any other thread (I find this to be rather improbable, since the problem has not manifested on any other system but yours, thus far.) Alternatively, some other core has acquired the lock, and has not released it in a timely fashion. This is more likely: especially if you are using software emulation, and the host thread emulating the guest core has too low of a priority or does not get woken up often enough or whatever else, then that could explain this panic.
comment:18 by , 16 months ago
Also, note that you can continue this panic by running co at the KDL prompt. If continuing (perhaps multiple times) eventually gets things "unstuck" then that supports the latter hypothesis here.
comment:19 by , 16 months ago
Is it an M1/macOS issue or a consequence of crazy slow environment?
qemu here on M1 is extremely slow (real 1m13, user 1m47, sys 0m21).
I've found that I can increase the chance of seeing the error if I keep wiggling the Terminal window while the code is running. I can see the window tearing increase with lock contention.
comment:20 by , 16 months ago
The issue isn't speed, it's latency. If all virtual cores are equally slow and are scheduled "fairly", then there's no problem besides things being slow. On the other hand, if some of the virtual cores are (for whatever reason) "faster" than other cores, or some virtual cores run much more often then other cores, then that will lead to this panic.
comment:21 by , 16 months ago
By the way, on VMware (hardware virtualized), here's a typical "time":
real 0m8.796s user 0m4.469s sys 0m1.756s
comment:22 by , 16 months ago
I was now able to trigger the panic again, using
/system/lib/openjdk11/bin/java -Dselftest.haikuBug18535=dump -Dorg.newsclub.net.unix.throughput-test.gracetime.seconds=1 -jar junixsocket-selftest-2.7.0-SNAPSHOT-jar-with-dependencies.jar
send code got stuck in testDatagramChannel, and I "kill -9"'ed the process from another Terminal tab. Kill -9 actually wasn't successful; the process is still alive.
Shortly after that, the kernel debugger appeared with the previously seen stack trace.
I entered "co", and the system returned to the desktop.
However:
- The kernel debugger repeatedly comes back after a while, still in mutex_lock within send_notify+0xb2
- Launching another java VM from another tab fails with "Error occurred during initialization of VM: Could not allocate metaspace: 1073741824 bytes"
comment:23 by , 16 months ago
If the process hasn't actually been killed, the OOM is expected, really. (Haiku does overcommit mmap by default, and I'm not sure our Java port makes use of it.)
comment:24 by , 16 months ago
| Summary: | PANIC: acquire_spinlock(): "Failed to acquire spinlock for a long time" in UnixDatagramEndpoint / socket_notify → [UNIX datagram sockets] Use-after-free in socket_notify |
|---|
Oho, I actually managed to reproduce the problem in VMware with that invocation!
And now that I'm looking at it here, I can clearly see the "value: deadbeef". I see now this is in your screenshots also, but I missed it at first because I didn't scroll far enough to the right.
This indicates a use-after-free of this socket.
comment:25 by , 16 months ago
| Milestone: | Unscheduled → R1/beta5 |
|---|---|
| Priority: | high → critical |
comment:27 by , 16 months ago
I think the lowered gracetime value actually increases the chance of catching the panic. Why? Because we try to forcibly terminate the send before it terminates naturally...
I wouldn't be surprised that calling "shutdown" or "close" on that socketfd from a different thread is triggering this.
comment:28 by , 16 months ago
The problem seems to occur intermittently still with VMware. I changed the "1" to a "0" in the command line, that seems to make it maybe more reliable.
shutdown/close from another thread shouldn't cause this, the send() path acquires references and locks to the other endpoints. I read through the code a bit and added some more asserts to try and catch the problem, no luck yet.
comment:29 by , 16 months ago
If you want to poke around with the native C code side of junixsocket, you can:
git clone https://github.com/kohlschutter/junixsocket cd junixsocket-native/src/main/c # vi send.c gcc -I. -Ijni *.c -shared -o libjunixsocket.so lib=$(pwd)/libjunixsocket.so /system/lib/openjdk11/bin/java -Dselftest.haikuBug18535=dump -Dorg.newsclub.net.unix.throughput-test.gracetime.seconds=1 -Dorg.newsclub.net.unix.library.override.force=$lib -jar path/to/junixsocket-selftest-2.7.0-SNAPSHOT-jar-with-dependencies.jar
Important: for sanity reasons, the path to org.newsclub.net.unix.library.override.force has to be an absolute path
comment:31 by , 16 months ago
(You should be able to update to/past that version after nightly builds run tonight, merely by running pkgman full-sync.)
by , 16 months ago
| Attachment: | Screenshot 2023-08-04 at 11.54.56.png added |
|---|
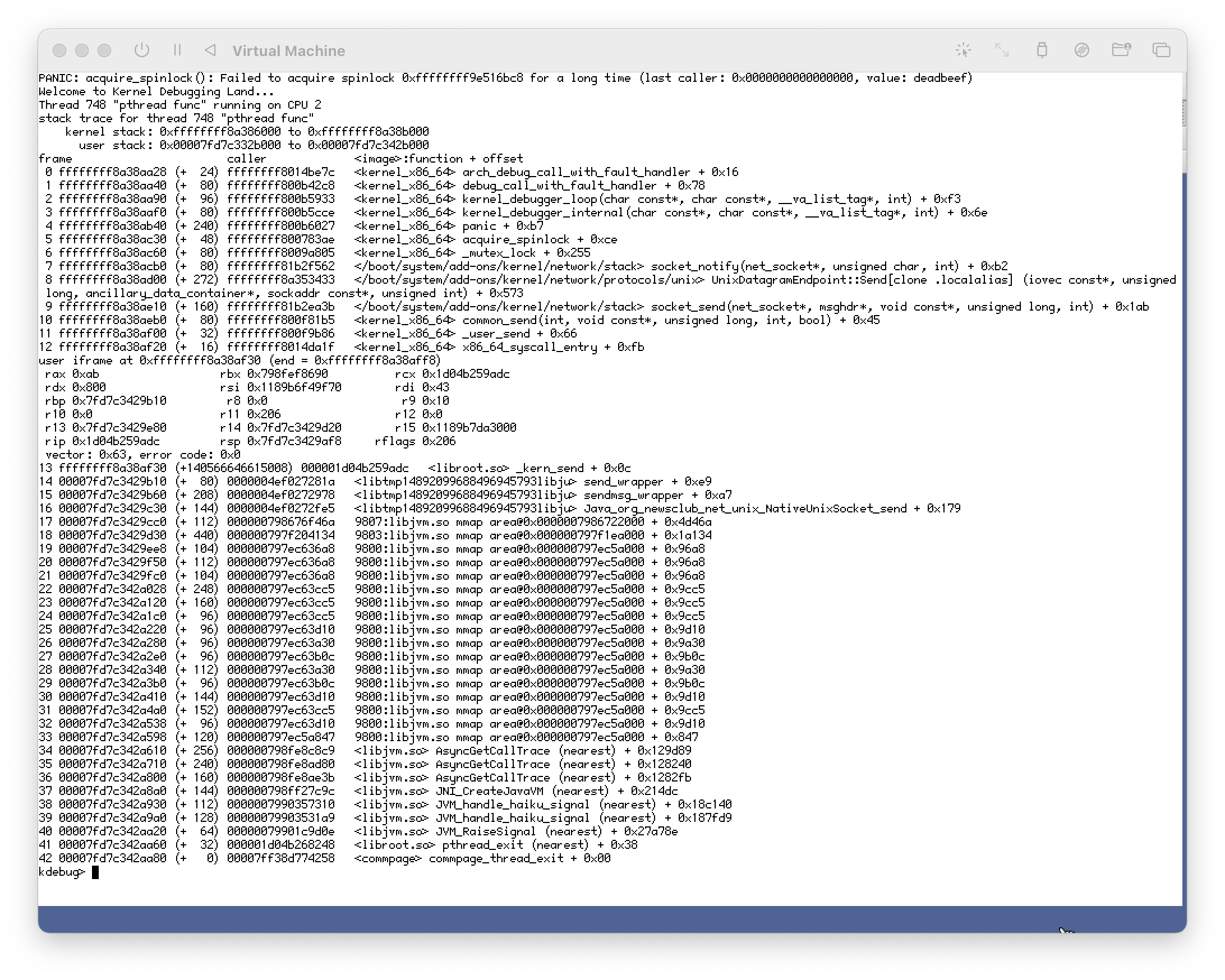
kernel panic on hrev57193
comment:33 by , 16 months ago
There was another oversight I fixed in hrev57194, please check after that.
comment:34 by , 16 months ago
Great, I can no longer trigger the kernel panic. Thank you so much, waddlesplash!
One bug that remains is that the datagram send still hangs. I haven't seen this on other platforms.
I noticed that I can avert this hang by setting a SO_SNDTIMEO of 1 second when creating AF_UNIX SOCK_DGRAM sockets, catching the ETIMEDOUT upon send, and treating it as ENOBUFS. This would be my current, somewhat brittle, workaround.
However, I think we might be able to fix this in the kernel by checking for this situation. What do yo think?
comment:35 by , 16 months ago
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
Excellent!
One bug that remains is that the datagram send still hangs. I haven't seen this on other platforms.
Do you have a minimal testcase for this? I'm not sure what the situation is that causes this problem. Are you really sure it's not just your VM being very slow?
Screenshot of kernel panic