

Opened 8 years ago
Last modified 2 weeks ago
#13554 assigned enhancement
Switch system allocator
| Reported by: | waddlesplash | Owned by: | waddlesplash |
|---|---|---|---|
| Priority: | high | Milestone: | Unscheduled |
| Component: | System/libroot.so | Version: | R1/Development |
| Keywords: | Cc: | ||
| Blocked By: | #15264 | Blocking: | #15996, #16626, #16861, #17226, #18451, #18603, #19419 |
| Platform: | All |
Description (last modified by )
We presently use an old version of the Hoard allocator, which is licensed under the LGPLv2. Newer versions are GPL or commercial license only, which is obviously not acceptable.
Benchmarks done by the Lockless group also show that the Hoard allocator has a very worrying performance dropoff for larger allocations, see https://locklessinc.com/benchmarks_allocator.shtml
Attachments (5)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (66)
comment:1 by , 7 years ago
| Description: | modified (diff) |
|---|---|
| Summary: | Investigate switching allocators → Switch system allocator |
comment:2 by , 7 years ago
So, here are the options, collected / condensed:
jemalloc
Homepage: https://github.com/jemalloc/jemalloc
License: BSD 2-clause
Notable users: FreeBSD, NetBSD, Firefox, Rust
Benchmarks: see Lockless page; [0]: https://github.com/ezrosent/allocators-rs/blob/master/info/elfmalloc-performance.md
Pros: Battle-tested, easily tweakable, very fast.
Cons: Bigger memory footprint vs. others, see [1]: http://www.openwall.com/lists/musl/2018/04/23/2 for more details. Appears to be optimized for speed over memory, up to 33% overhead for smaller (~30MB) heaps [2]: https://news.ycombinator.com/item?id=13912639
tcmalloc
Homepage: http://goog-perftools.sourceforge.net/doc/tcmalloc.html & https://github.com/gperftools/gperftools
License: BSD 3-clause
Notable users: Google Chrome
Benchmarks: see Lockless page, and most of the other pages linked here
Pros: ?
Cons: Does not release memory back to the system without very specific orders to do so, i.e., it's optimized for very specific high-performance mostly-constant-or-increasing memory workflows (servers, browsers...), rather than a generalized allocator.
rpmalloc
Homepage: https://github.com/rampantpixels/rpmalloc
License: Public domain or MIT
Notable users: RemObjects, LMMS,
Benchmarks: see [0], [2], [3]: https://github.com/rampantpixels/rpmalloc/blob/master/BENCHMARKS.md
Pros: Very well balanced between speed vs. memory usage, yet still faster than the competition for most workloads. Well-documented and readable code.
Cons: Not used as widely as jemalloc.
others
I've left the following allocators out of this analysis for various reasons:
- nedmalloc. Unmaintained since 2014 and all benchmarks show it underperforming vs. them.
- bmalloc. Significantly worse-performing vs. the options on this list with no apparent advantages.
- hoard3. Now GPL only, which is obviously not acceptable for use as a system library.
- ptmalloc2. glibc default allocator; underperforms vs. all of these.
comment:3 by , 7 years ago
The benchmarks in [0] show that rpmalloc really does have the best memory-performance tradeoff, and even the producer-consumer scenario that rpmalloc lists as a potential worst-case given its design is actually better than most of the competition. Plus, I believe it's already used on Haiku (we have a LMMS port), so there shouldn't be any compatibility issues.
comment:4 by , 7 years ago
A quick read of the rpmalloc readme shows that it avoids fragmentation by using a given 64K page for allocations of the same size (32 bytes, 64 bytes, ...). As a consequence:
- All allocations are rounded to the next power of two size, at least (I think for larger allocations it is even more)
- If you don't do a lot of allocations of the same size, you are left with a largely empty 64K page for that size
As a result, while the memory overhead for the allocator itself is low, the drawback is possibly a lot of unused memory, which is technically free, but only allocatable for specific sizes of allocations. As a result you may have many 64-byte blocks free but end up being unable to do a 32 byte allocation, if the system as a whole runs out of memory space.
We should see how this affects our use cases, and maybe it's possible to tweak the settings (several things are configurable). In any case, benchmarks in our real life situation will be needed, there can't be a clear winner without that.
comment:5 by , 7 years ago
I have a jemalloc recipe somewhere, lemme check it. Here you go: https://github.com/haikuports/haikuports/pull/1965
comment:6 by , 7 years ago
As a result you may have many 64-byte blocks free but end up being unable to do a 32 byte allocation, if the system as a whole runs out of memory space.
Well, if mmap returns addresses already aligned properly (or we create an API that does -- actually I think create_area can do what we want here?) then the wastage will be for size classes instead of alignment. And in that case, as the README says:
Super spans (spans a multiple > 1 of the span size) can be subdivided into smaller spans to fulfull a need to map a new span of memory. By default the allocator will greedily grab and break any larger span from the available caches before mapping new virtual memory.
So we only need to worry about wasting memory to get proper alignment.
But indeed, benchmarks are needed.
comment:7 by , 6 years ago
| Blocking: | 7420 added |
|---|
comment:8 by , 6 years ago
| Blocking: | 7420 removed |
|---|
comment:9 by , 6 years ago
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
We've switched to rpmalloc in hrev53136.
comment:11 by , 6 years ago
Current master branch + a handful of tweaks so it builds as C++ (besides the HAIKU changes.)
comment:12 by , 6 years ago
That fails to answer the question ("current master" will be useless and outdated information in 3... 2... 1...)
The commit that was used is (I guess): https://github.com/rampantpixels/rpmalloc/commit/387ebac92fc85e5acd77e5717c04737ddb5f20ed
comment:13 by , 5 years ago
| Resolution: | fixed |
|---|---|
| Status: | closed → reopened |
comment:14 by , 5 years ago
I would like to add https://github.com/plasma-umass/Mesh as something to keep in mind, even if it won't be used itself i think it still offers some interesting ideas.
comment:15 by , 5 years ago
Taken mostly from my comment in #15495:
So, rpmalloc kind of assumes that virtual address space use != physical memory reservation, which of course Haiku does so assume, and with good reason. It also seems to be designed for "high-performance", i.e. 64-bit only where lots of virtual address space waste is fine, and Haiku needs to support 32-bit for a while more (and on non-x86, eventually..)
musl, it seems, is in the process of writing a new allocator, which may be a better fit for us: https://github.com/richfelker/mallocng-draft
Original mailing list post: https://www.openwall.com/lists/musl/2019/11/28/1
More comments on the design: https://www.openwall.com/lists/musl/2019/11/29/2 -- note "- compatibility with 32-bit address space", and "- elimination of heap size explosion in multithreaded apps", which are problems that most modern allocators, rpmalloc included, seem to have.
comment:16 by , 5 years ago
| Milestone: | R2 → Unscheduled |
|---|
comment:17 by , 5 years ago
| Blocking: | 15996 added |
|---|
comment:18 by , 5 years ago
| Owner: | changed from to |
|---|---|
| Status: | reopened → assigned |
musl's next-gen allocator is looking like a very good fit, I've been following their progress closely. Once they have deployed it in a production system, I will take a look at switching us to it.
follow-up: 33 comment:20 by , 5 years ago
It was not mentionned here, but hoard3 has noticed that GPL was a bad idea and they are now using the Apache License. So, simply updating to the latest version of Hoard may be an interesting option again.
Some benchmarks here: http://ithare.com/testing-memory-allocators-ptmalloc2-tcmalloc-hoard-jemalloc-while-trying-to-simulate-real-world-loads/ (which I trust a little more than the lockless ones, which are probably biased to show the cases where their allocator works best). But given our experience with rpmalloc, we know there are a few extra things to check:
- Use of virtual address space, especially on 32-bit systems this is an important factor for us and not something usually benchmarked in modern times.
- Support for "super aligned" allocations (4K, 16K or more) to implement posix_memalign and similar functions (example use cases: Ruby, WebKit).
Another one to maybe consider: https://microsoft.github.io/mimalloc/index.html
by , 5 years ago
| Attachment: | 0001-mimalloc-building-on-Haiku.patch added |
|---|
comment:21 by , 5 years ago
Attached a patch that gets mimalloc to compile (with gcc8, it relies on modern C or C++ features so this won't go with gcc2). However it crashes when I run the provided "stress" test so I have probably missed something.
Note that it normally needs static TLS, so we should look into implementing that, probably. Dynamic TLS is possible but slower accoding to their documentation.
comment:22 by , 5 years ago
I tested mimalloc with patch. It do not release memory to system. It also crash if out of system memory.
comment:23 by , 5 years ago
Memory is released to system if following options are enabled:
mi_option_set_enabled(mi_option_segment_reset, true); mi_option_set_enabled(mi_option_reset_decommits, true);
comment:24 by , 5 years ago
Yes, this is why allocators not designed for use as a system allocator just do not work, they often are designed for specific use-cases and do not function well in the general case; you have to enable non-default options that are not as tested. I would rather we use an allocator actually in use as a system malloc somewhere.
musl's new allocator was designed to work well even in 32-bit address spaces, and from what I have heard, it still performs very well even when used as Firefox's memory allocator.
comment:25 by , 5 years ago
We need to do benchmarks, and see what works for us. musl is designed with Linux apps in mind, a lot of apps are running single threaded there, where we have a minimum of 2 threads and usually a lot more. So "system allocator" isn't all there is to it. We also have a lot of producer-consumer type of interactions between the threads because of BMessages (allocated in the sender thread, freed in the receiver thread), which mimalloc does handle reasonably. And because we are mainly C++, there can also be different patterns of allications than what musl would optimize for.
We need to experiment, benchmark, see what works and what doesn't. So yes, musl is a good candidate, but so are mimalloc and jemalloc. We need to compare them in real-world and see how they behave. Then we can decide which one we want to use. We may even end up making different choices for the 32 and 64bit versions of Haiku, if we find that the performance/overhead compromise is indeed very different between the two.
And of course we need to configure the allocator to match our use case, when there are things available to configure.
comment:26 by , 5 years ago
No, I've talked with the musl developers, they are absolutely testing with heavily multi-threaded applications (like Firefox, or database servers, etc. etc.)
jemalloc is a terrible idea for all the reasons I've mentioned (and the musl developers mentioned): it is even more aggressive than rpmalloc at mapping in and not releasing memory. So if rpmalloc causes git gc to have pathological memory usage, so will jemalloc (and reading about hoard3 leads me to believe the same thing is true there.)
It's also worth noting that there is a kind of "allocation cache" for BMessages already in the Application Kit which alleviates some of the cross-thread allocation problems, I think.
comment:27 by , 5 years ago
mimalloc is working fine on 32 bits when system memory allocation fails, crash occurs only on 64 bit. It is hard to debug crash because it is not possible to run programs while all memory is allocated by test program.
comment:28 by , 5 years ago
Here's the lead musl developer's analysis of mimalloc: https://www.openwall.com/lists/musl/2019/11/30/3
comment:29 by , 5 years ago
(Allocating 2MB "spans" and breaking them up is also what rpmalloc did. It looks like mimalloc is very similar to rpmalloc in a lot of ways, actually, so I would expect it to have similar memory usage problems to rpmalloc with git gc and the like.)
comment:30 by , 5 years ago
I'm just saying we should benchmark a few different options and see how they behave. musl may be the best choice, but we should still check how it behaves, know what to expect, and compare it to other options before we make a definitive choice. I'm not arguing in favor of mimalloc or any implementation in particular. Let's do some benchmarks and see what fits our workloads best.
It's not like it's a very complicated thing to do, either, it took me less than two hours to get mimalloc compiling and I think any other allocator would be ported just as easily. So it's worth doing the experiments and then we can decide. There is no point in arguing on the compared selling points of various allocators if we don't put them through our own tests.
We can also uncover other problems, for example, we know that an area-based allocator will end up creating more areas, and we know that our areas have bad performance when you create many of them. So that will be a thing to consider too (and either we'll need to optimize our areas handling, or find a way to not use them too much). We can't handle the allocator as a black box here, and we can't assume anything about our allocation patterns and wether they match an allocator design or not, because we have not measured anything. Going through that will make sure that we identify the limitations of an allocator (or the way it badly interacts with other parts of the OS), and will also reinforce our confidence in whatever choice we make in the end, knowing what we validated against and which things we decided to optimize for. And we will probably find other things to optimize on our side as well.
The problem of releasing memory to the OS is an interesting one. It probably shouldn't be done immediately for performance reasons, you want to keep a few free pages around for some time. So, when should it be done? Every N allocations? Only on request from the low_resource_manager? If so, how is the request forwarded to the allocator? A mix of both strategies, with some automatic release and a more agressive cleanup when the low resource manager asks for it? Is that even possible with each of these allocators?
comment:31 by , 5 years ago
mimalloc on 64 bit crash here: https://github.com/microsoft/mimalloc/blob/master/include/mimalloc-internal.h#L600. Accessed address seems valid, strange...
comment:32 by , 5 years ago
I tried ramdom size allocations in mimalloc and it crashed on free in _mi_segment_page_free.
comment:33 by , 5 years ago
Replying to pulkomandy:
It was not mentionned here, but hoard3 has noticed that GPL was a bad idea and they are now using the Apache License. So, simply updating to the latest version of Hoard may be an interesting option again.
Would it make sense in the mean time to update to the latest revision of hoard3 then?
comment:34 by , 5 years ago
No, we are on hoard2 which is very differently designed than hoard3; it uses a single map region where hoard3 uses individual areas around 2MB in size much like rpmalloc does. musl's mallocng is really the best option, once it is stable and mainlined.
comment:35 by , 3 years ago
| Blocked By: | 15264 added |
|---|
comment:36 by , 6 months ago
It looks like OpenBSD does not have any sort of overcommit, so their malloc() may be a good candidate to test here.
comment:37 by , 6 months ago
| Blocking: | 16861 added |
|---|
follow-up: 39 comment:38 by , 6 months ago
c-raii uses Resource Acquisition Is Initialization or RAII, it is MIT licensed, it can be new system allocator for Haiku:
https://github.com/zelang-dev/c-raii
https://zelang-dev.github.io/c-raii/
I created a topic on the forum to explain better:
https://discuss.haiku-os.org/t/c-raii-as-new-system-allocator-for-haiku/15459
comment:39 by , 6 months ago
Replying to marcoapc:
c-raii uses Resource Acquisition Is Initialization or RAII, it is MIT licensed
It is actually a wrapper over rpmalloc.
comment:40 by , 6 months ago
My mimalloc patch: https://review.haiku-os.org/c/haiku/+/6952. It is confirmed to work well on riscv64, but it currently not ready for 32 bits and low memory conditions (need some extra handling on kernel side).
It is in theory suitable for Haiku use because it is originally designed for Windows that do not use overcommit and it have an option to enable/disable overcommit. It also seems waste less address space compared to other modern memory allocators.
comment:41 by , 6 months ago
| Blocking: | 16626 added |
|---|
comment:42 by , 6 months ago
| Blocking: | 18603 added |
|---|
comment:43 by , 6 months ago
| Blocking: | 18451 added |
|---|
by , 2 months ago
| Attachment: | DSC_0077.JPG added |
|---|
comment:44 by , 2 months ago
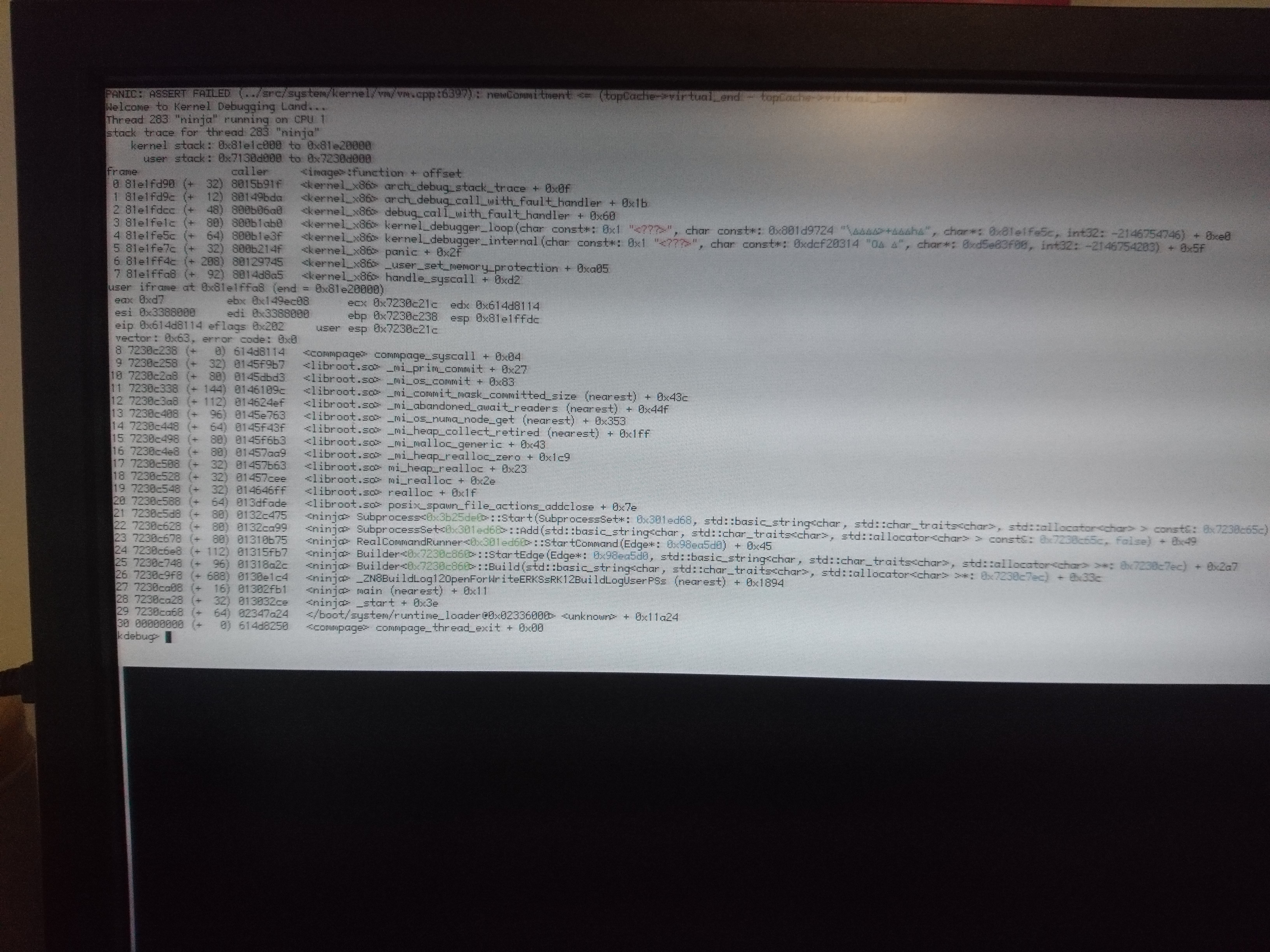
Testing mimalloc on 32 bit x86, I get this panic while trying to build webkit
comment:46 by , 7 weeks ago
| Blocking: | 17226 added |
|---|
comment:47 by , 3 weeks ago
More discussion on the forums about mimalloc: https://discuss.haiku-os.org/t/a-new-malloc-for-haiku-userland-based-around-openbsds-malloc/16377/11
And the OpenBSD malloc integration change: https://review.haiku-os.org/c/haiku/+/8335
This works pretty well including in testing. I will probably merge this sometime in the next day or two barring any "unforseen" problems.
comment:48 by , 3 weeks ago
Seeing as this is a fairly widereaching change please do not commit this without a build switch to build with either malloc.
comment:49 by , 3 weeks ago
The build switch is just commenting/uncommenting which directory is included.
I don't plan to remove hoard2 (again) until OpenBSD malloc has been used for multiple months without issue.
comment:50 by , 3 weeks ago
Merged in hrev58639. I will wait to close this and dependent tickets until we see how things go.
comment:51 by , 2 weeks ago
I just tried 58639, and I can consistently within 5 seconds get Medo to crash when loading a bunch of video files. See attached crash report (error in memcpy in AvCodecDecoder - part of ffmpeg). With the older version (58583 from Feb 1st), it works fine (no crashes).
Steps to reproduce:
- drag and drop a bunch of video files into the Medo sources window.
- one by one, drag a video file into the timeline view (create new tracks).
On the 3rd video being dragged, Medo will crash in memcpy in AvCodecDecoder.
Medo will cache video frames, and there are quite a number of threads decoding each video so there is plenty of memory contention.
by , 2 weeks ago
| Attachment: | Medo-2131-debug-14-02-2025-09-41-07.report added |
|---|
Crash with allocator on 58639 (Medo)
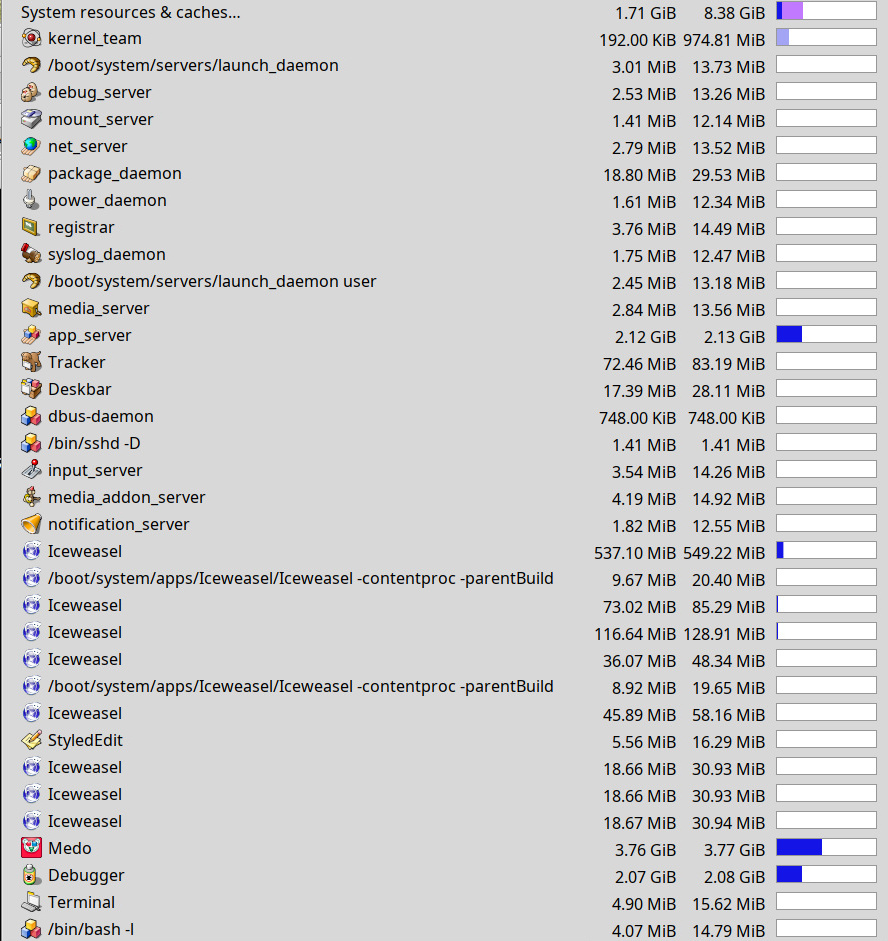
by , 2 weeks ago
| Attachment: | Bitmap Clip.jpg added |
|---|
Plenty of unused memory, so Medo not running out of memory when caching files
comment:52 by , 2 weeks ago
64-bit "movsb" moves bytes from the pointer in RSI to the one in RDI, and the pointer in RDI looks wrong (it has the high bits set, which would indicate a kernel address on Haiku.) Can you test with the guarded heap? (LD_PRELOAD=libroot_debug.so MALLOC_DEBUG=g). I will see about trying to reproduce the problem myself, later.
comment:53 by , 2 weeks ago
Hi Augustin. LD_PRELOAD=libroot_debug.so MALLOC_DEBUG=g will crash really quick in ff_h264_decode_picture_paramter_set, way before I can do my drag drop test. Reproducable crash with guarded malloc, same location.
comment:54 by , 2 weeks ago
Then this isn't a bug in the allocator.
Does the guarded heap tell you where the allocation that's being written past was made? I.e. did you allocate the buffer in Medo, or did the Media Kit mess something up? So we know where to open a ticket.
by , 2 weeks ago
| Attachment: | Medo-1110-debug-14-02-2025-18-10-02.report added |
|---|
ff_h264_decode_picture_parameter_set
comment:55 by , 2 weeks ago
With GDB, here is the backtrace:
#0 0x00000000248fccc9 in ff_h264_decode_picture_parameter_set () from /boot/system/lib/libavcodec.so.60.31.102
#1 0x00000000248f5f53 in decode_extradata_ps () from /boot/system/lib/libavcodec.so.60.31.102
#2 0x00000000248f7492 in ff_h264_decode_extradata () from /boot/system/lib/libavcodec.so.60.31.102
#3 0x0000000024611290 in h264_decode_init () from /boot/system/lib/libavcodec.so.60.31.102
#4 0x000000002462e50e in ff_frame_thread_init[cold] () from /boot/system/lib/libavcodec.so.60.31.102
#5 0x00000000247169d4 in avcodec_open2 () from /boot/system/lib/libavcodec.so.60.31.102
#6 0x00000000242b97c7 in AVCodecDecoder::_NegotiateVideoOutputFormat(media_format*) () from / boot/system/add-ons/media/plugins/ffmpeg
#7 0x00000000242b9a85 in AVCodecDecoder::NegotiateOutputFormat(media_format*) () from /boot/ system/add-ons/media/plugins/ffmpeg
#8 0x0000000000e953c3 in BMediaTrack::DecodedFormat(media_format*, unsigned int) () from /boot/ system/lib/libmedia.so
#9 0x00000000007bf891 in MediaSource::SetVideoTrack (this=0x3e021f60, path=0x3e01ffd0 "/boot/home/Desktop/Media/MediaTest/IMG_2895.MOV", track=0x3f352cd0, format=0x7f0001ce99e0)
at Editor/MediaSource.cpp:190
#10 0x00000000007bf2ee in MediaSource::MediaSource (this=0x3e021f60, filename=0x3e01ffd0 "/boot/home/Desktop/Media/MediaTest/IMG_2895.MOV") at Editor/MediaSource.cpp:96
comment:56 by , 2 weeks ago
Does the same problem happen with the same file in MediaPlayer and/or ffplay?
comment:57 by , 2 weeks ago
The source file which triggered the issue (IMG_2895.MOV) works fine in MediaPlayer.
The difference is that I drag/drop 10 video files at once into the Medo source window, so ffmpeg is processing 10 files (x16 threads per file), so it stresses the system a bit more than loading one file at a time.
I could theoretically load / parse one file at a time, but this was working in the past (hrev 58583 from Feb 1st 2025) where I could parse many files at once.
I do not know if ffmpeg has also been updated since 1st Feb.
comment:58 by , 2 weeks ago
But does it work fine in MediaPlayer and/or ffplay with the guarded heap?
comment:61 by , 2 weeks ago
| Blocking: | 19419 added |
|---|
I've opened #19419 to track turning on more safety features in the new malloc.
PulkoMandy has some (slightly old) notes in #7420. He also links to lockless' allocator benchmark page.
One of the musl libc developers has a more comprehensive analysis of the problems with jemalloc here: http://www.openwall.com/lists/musl/2018/04/23/2 -- so it looks like it's not the best choice for us.