

#14646 closed bug (fixed)
KDL on poweroff while network load over iprowifi4965 [patch]
| Reported by: | hugeping | Owned by: | waddlesplash |
|---|---|---|---|
| Priority: | normal | Milestone: | R1/beta2 |
| Component: | Drivers/Network/iprowifi4965 | Version: | R1/Development |
| Keywords: | kdl, iprowifi4965 | Cc: | |
| Blocked By: | Blocking: | #15202 | |
| Platform: | All |
Description (last modified by )
While poweroff with networking is active (iprowifi4965) i often got KDL. Here is the trace with DEBUG on:
wlan_control: 9234, 16
->iwn_rx_done begin
->Doing iwn5000_get_rssi
iwn5000_get_rssi: agc 39 rssi 4885 5400 0 result -59
->Doing iwn_hw_stop
->Doing iwn_reset_rx_ring
->doing iwn_reset_tx_ring
Last message repeated 19 times.
->iwn_rx_done: end
iwn_notif_intr: cur=1; qid 4 idx 3 flags 0 type 162(BEACON_MISSED) len 20
iwn_notif_intr: beacons missed 0/0
iwn_notif_intr: cur=2; qid 4 idx 17 flags 0 type 192(RX_PHY) len 68
iwn_rx_phy: received PHY stats
iwn_notif_intr: cur=3; qid c idx 204 flags cc type 204(IWN_CMD_BT_COEX_PRIOTABLE) len 52428
iwn_notif_intr: cur=4; qid 4 idx 19 flags 0 type 157(BEACON_STATS) len 528
->iwn_rx_statistics begin
->iwn_rx_statistics received during calib
iwn_notif_intr: cur=5; qid 9 idx 129 flags 0 type 168(IWN_CMD_SET_SENSITIVITY) len 4
iwn_notif_intr: cur=6; qid 4 idx 27 flags 0 type 192(RX_PHY) len 68
iwn_rx_phy: received PHY stats
iwn_notif_intr: cur=7; qid c idx 204 flags cc type 204(IWN_CMD_BT_COEX_PRIOTABLE) len 52428
iwn_notif_intr: cur=8; qid 4 idx 29 flags 0 type 157(BEACON_STATS) len 528
->iwn_rx_statistics begin
->iwn_rx_statistics received during calib
iwn_notif_intr: cur=9; qid 3 idx 7 flags 0 type 28(TX_DONE) len 44
iwn5000_tx_done: qid 3 idx 7 RTS retries 0 ACK retries 0 nkill 0 rate 420a duration 746 status 201
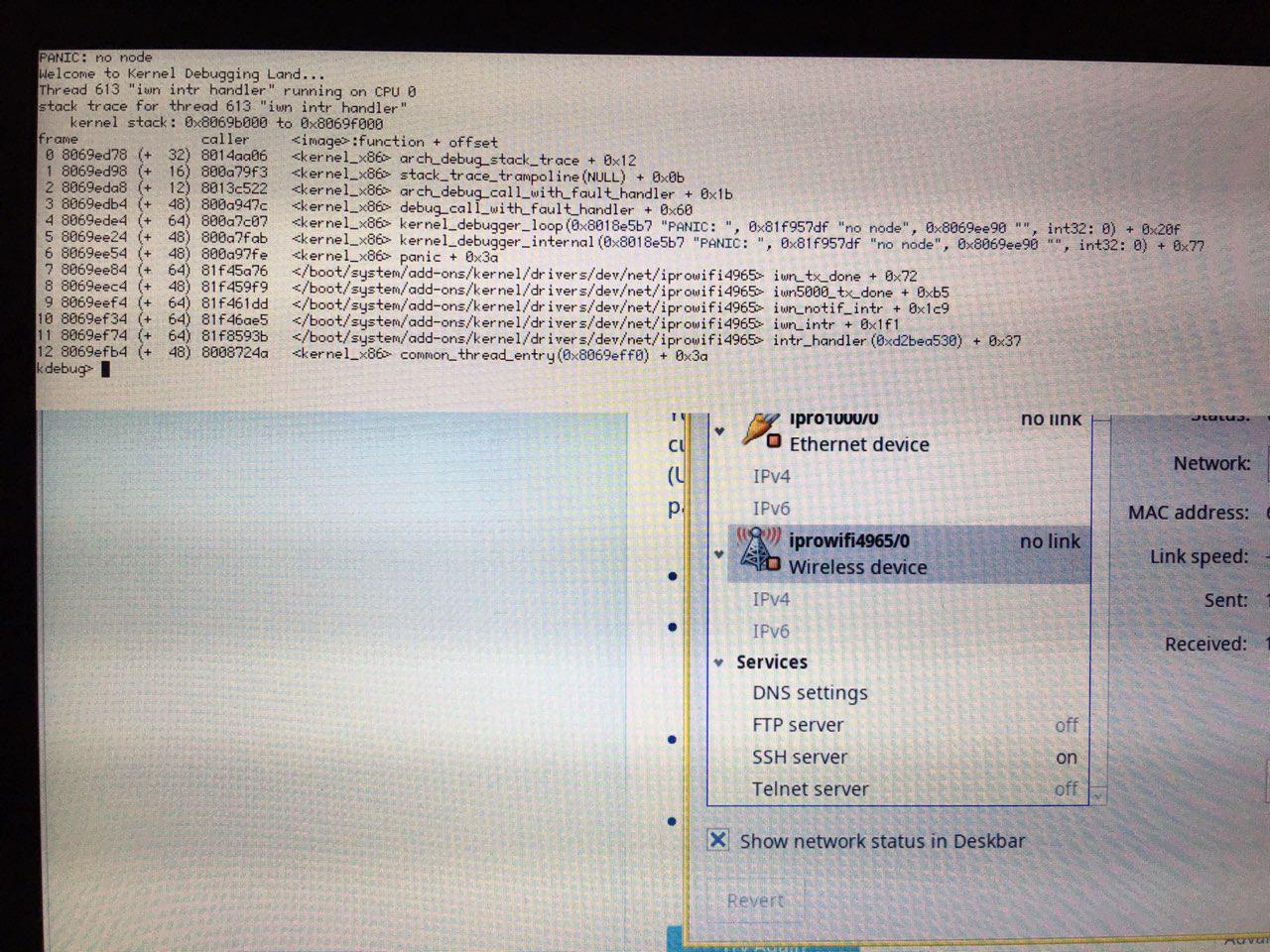
PANIC: no node
Welcome to Kernel Debugging Land...
Thread 759 "iwn intr handler" running on CPU 2
stack trace for thread 759 "iwn intr handler"
kernel stack: 0xffffffff91046000 to 0xffffffff9104b000
frame caller <image>:function + offset
0 ffffffff9104abd8 (+ 16) ffffffff8014132d <kernel_x86_64> arch_debug_stack_trace + 0x13
1 ffffffff9104abe8 (+ 16) ffffffff800a7823 <kernel_x86_64> stack_trace_trampoline(void*) + 0x09
2 ffffffff9104abf8 (+ 24) ffffffff8013902c <kernel_x86_64> arch_debug_call_with_fault_handler + 0x16
3 ffffffff9104ac10 (+ 96) ffffffff800a820f <kernel_x86_64> debug_call_with_fault_handler + 0x8b
4 ffffffff9104ac70 (+ 96) ffffffff800a926b <kernel_x86_64> kernel_debugger_loop(char const*, char const*, __va_list_tag*, int) + 0x10a
5 ffffffff9104acd0 (+ 80) ffffffff800a96d4 <kernel_x86_64> kernel_debugger_internal(char const*, char const*, __va_list_tag*, int) + 0x1a2
6 ffffffff9104ad20 (+ 240) ffffffff800a98d3 <kernel_x86_64> panic + 0xba
7 ffffffff9104ae10 (+ 80) ffffffff80617096 </boot/system/non-packaged/add-ons/kernel/drivers/bin/iprowifi4965> iwn_tx_done + 0x1c6
8 ffffffff9104ae60 (+ 192) ffffffff806257f1 </boot/system/non-packaged/add-ons/kernel/drivers/bin/iprowifi4965> iwn_notif_intr + 0x3c1
9 ffffffff9104af20 (+ 112) ffffffff80627738 </boot/system/non-packaged/add-ons/kernel/drivers/bin/iprowifi4965> iwn_intr + 0x488
10 ffffffff9104af90 (+ 32) ffffffff8065edcd </boot/system/non-packaged/add-ons/kernel/drivers/bin/iprowifi4965> intr_handler(void*) + 0x1d
11 ffffffff9104afb0 (+ 32) ffffffff800858f6 <kernel_x86_64> common_thread_entry(void*) + 0x37
12 ffffffff9104afd0 (+1861963824) ffffffff9104afe0
The iwn_tx_done + 0x1c6 is KASSERT line in if_iwn.c (iwn_tx_done()):
KASSERT(data->ni != NULL, ("no node"));
So, the problem is in race between iwn_hw_stop and iwn_intr (->iwn_notify_intr-> ... iwn_tx_done)
The race is possible due the fact, that iwn_intr called from thread (freebsd compat glue) and iwn_hw_stop can be
called while iwn_intr is in way and not grab IWN_LOCK yet.
So, the problem is likely Haiku only (not bug in freebsd code).
I fixed it with patch, i have attached. I just skip interrupts called while iface is not running.
But i am not sure if it ok, and if another drivers affects this too. So, i patched two modules only for example.
Please, check it.
Attachments (4)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (26)
by , 6 years ago
comment:1 by , 6 years ago
| Description: | modified (diff) |
|---|
comment:2 by , 6 years ago
In fact, skipping interrupt handling while iface is not running can be the BAD idea. So, ideas are welcome. :)
comment:3 by , 6 years ago
Yes, this means there actually was a relevant interrupt, despite the node getting destroyed. We need to do something different here; probably we should tear down all devices before rebooting.
comment:4 by , 6 years ago
As i can see, the iwn_hw_stop can be called not only while reboot. :( Looks like this:
- Interrupt scheduled (via mutex release) but iwn lock not grabbed
- Hw Stop (under iwn lock)
3 Release lock, interrupt comes and grabs iwn lock. But it is interrupt that occured before stop
So, it s like that we have cancel interrupt in way procedure or like?
comment:5 by , 6 years ago
As this driver code comes from FreeBSD, we should just do whatever FreeBSD does here.
comment:6 by , 6 years ago
Ok, another idea.
In glue.c
atomic_set((int32*)&sc->sc_intr_status_1, r1); atomic_set((int32*)&sc->sc_intr_status_2, r2);
In iwn_intr there is:
r1 = atomic_get((int32 *)&sc->sc_intr_status_1); r2 = atomic_get((int32 *)&sc->sc_intr_status_2);
Is this appreach necessary? Why not just to read registers from iwn_intr, as it is in FreeBSD code?
It's looks for me, that it can fix the race too In locked iwn_intr we will read *real* state of registers?
comment:7 by , 6 years ago
Is this appreach necessary?
Sry, this in NOT the variant. We must disable interrupts...
comment:8 by , 6 years ago
Yes, this approach is necessary. FreeBSD interrupt handlers run *outside* of the "interrupts disabled" context, and thus have access to mutexes, semaphores, etc. that are not accessible inside it. Our interrupt handlers always run inside the interrupt context, and so we need to bridge the gap here.
The glue code is called from within the main interrupt handler, and if it returns 1, the compat layer will invoke the thread scheduler and run the real interrupt handler. So these two pieces of code should run within microseconds of each other.
comment:9 by , 6 years ago
So, the RIGHT solution might be:
in places where interrupts are disabled we make flag, that it is disabled
In interrupt handler after LOCK we check this flag
This will remove all races, but this patches BSD code (may be such function can be moved to glue layer?)
Dirty example (if_ipw.c):
When disable:
CSR_WRITE_4(sc, IPW_CSR_INTR_MASK, 0); intr_disabled = 1;
When enable:
CSR_WRITE_4(sc, IPW_CSR_INTR_MASK, IPW_INTR_MASK); intr_disabled = 0;
In intr:
IPW_LOCK(sc);
if (intr_disabled)
goto done;
Of course, intr_disabled should changed on some glue function.
Imho, the race beetwin intr thread and other functions is really awful. We must fix it somehow....
comment:11 by , 6 years ago
But that doesn't change the fact that there actually was some interrupt data. Otherwise the registers would have been 0 and the KDL would not have happened. So the real problem is that interrupts were not disabled.
comment:12 by , 6 years ago
Sry for my english, may be i cant describe correctly what i mean.
In FreeBSD there is NO problem, because when code disables interrupts under the lock, there is no interrupt in way. And the interrupt handler in FreeBSD got status register under lock. It is always actual.
In Haiku case, we got interrupt, save status and schedule handler into thread. In that (small!) period of time we call stop (and it grabs LOCK before it does interrupt thread). Then "stop" disables interrupts, free tx and so on... UNLOCK and WE GOT OLD interrupt handler! It is not actual anymore.
So, in my opinion, the problem is specific for Haiku. When the FreeBSD code disables interrupts we must discard all interrupts "in way". So, the ugly example with intr_disabled demonstrate it.
comment:13 by , 6 years ago
I may be wrong, in fact. I found now, that in FreeBSD code there is mutexes used. So, i am not sure, if it acts like spinlock in Linux. I must investigate it deeper.
comment:14 by , 6 years ago
Sry, i did not read your comment about freebsd interrupts carefully. So, interrupts in FreeBsd runs in not atomic context. And this race may ocuures in real freebsd code too.. hm?
comment:15 by , 6 years ago
Theoretically, yes. But I'm not convinced that's whats happening here. If the node was already deleted, then all interrupts should already have been disabled. So something is going wrong in another way, I think.
comment:16 by , 6 years ago
Yes, they are disabled on deleting node, but if the old interrupt is not scheduled yet (thread part). It will schedule later. With old state of registers. This is "lost" interrupt call. :)
1) hw interrupt, shedule thread part of interrupt
2) stop (which disables interrupts)
3) thread part of interrupt comes here, after interrupts are disabled at 2.
So, if in BSD interrupt handlers are running in threads (so, that they can use mutexes), it's looks for me that it is problem of BSD driver...
comment:17 by , 6 years ago
New information.
1) It's like that BSD affecting this bug too: https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=192641
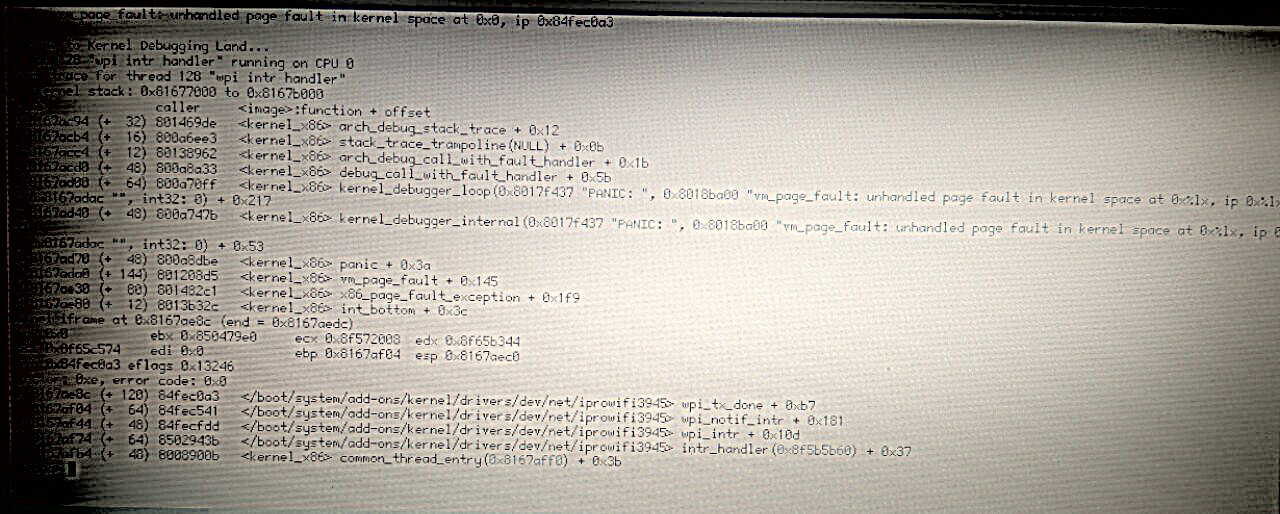
2) I have received another bug report. Bad news: this is another driver iprowifi3945 and this occured while running (not on reboot). I objdumped driver (it is official released beta) and found that it is access to NULL'ed node too. KASSERT is absent in code (because is release?). I will attach screenshot for information.
So, what shall we do? Bugs are still there. They leads to KDL while running wifi (not just reboot). It's likely that it is bugs of BSD drivers (but i am not sure it is a good idea to fix them without BSD running.). The cause of bugs, i belive, is known.
We have the plan? :)
by , 6 years ago
| Attachment: | photo_2018-12-02_21-04-45.jpg added |
|---|
comment:18 by , 6 years ago
I've got similar KDL, please see the photo above.
hrev52612 gcc2
device Network controller [2|80|0]
vendor 8086: Intel Corporation device 0085: Centrino Advanced-N 6205 [Taylor Peak]
comment:20 by , 6 years ago
| Blocking: | 15202 added |
|---|
comment:21 by , 5 years ago
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
No reply, and that merge of upstream commits should have fixed this anyway according to FreeBSD bugtracker.
comment:22 by , 5 years ago
| Milestone: | Unscheduled → R1/beta2 |
|---|
Assign tickets with status=closed and resolution=fixed within the R1/beta2 development window to the R1/beta2 Milestone
patch to fix race iwn_stop vs iwn_tx_done