

Opened 6 years ago
Last modified 8 months ago
#14979 new bug
High ICI latency bogging down scheduler on VirtualBox
| Reported by: | ambroff | Owned by: | nobody |
|---|---|---|---|
| Priority: | normal | Milestone: | Unscheduled |
| Component: | System/Kernel | Version: | R1/Development |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | #18936 | |
| Platform: | x86-64 |
Description
tl;dr: I found that the CPU scheduler has scalability issues on a x86_64 system with a large number of CPU cores, and narrowed it down to arch_smp_send_ici(int32)
Detailed summary: I recently bought a new development workstation with a 12 Core (24 thread) CPU (Ryzen Threadripper 1920x). It's Linux for a while and has been great.
I decided recently to try Haiku on this computer to see if there were any interesting hardware issues to debug. So I grabbed R1 Beta1 and tried booting it up.
It booted, but it took *ages* to get to the livecd language prompt. Something like 20 minutes. The system was completely unusable. Extremely unresponsive to the point where I could barely move the mouse or select the "Boot to Desktop" button.
I decided to investigate, thinking it might be a userspace performance issue. I found that I could reproduce this easily in Virtual Box configuring a virtual machine with 12 cores (which I regularly do for Linux and Windows virtual machines on this system, which has always been fine). I tried booting with different CPU configurations from 1 core to 12 cores, and anecdotally, I noticed that the system felt slower with more cores.
I found the system profiler by looking through the code and tried collecting some samples with 2 cores and 12 cores to compare them (which was painful because the system was so unbearably slow with 12 cores). This ended up not being very useful, since whatever was causing the system to feel so slow wasn't being instrumented by the profiler.
After this I found the scheduler profiler, and that's where things started to click into place.
reschedule(int32) is something like 35x slower with 12 cores than it is with 2 cores on average. The bulk of the cost seems to be in enqueue(Thread*, bool).
Disabling CPUs at runtime, even though it's painful, makes the system more and more responsive. Once I had disabled all but 4 or 6 cpus the system was much more responsive. I also noticed that when I changed the scheduler mode to powersave mode the system was fairly responsive, even with all 12 cores enabled.
That lead me to compare the powersave and low_latency modes to understand why powersave mode was so much more responsive. Since powersave mode tries to avoid rebalancing unless load on the current CPU is high, I assume that rebalancing itself is where the scaling issues are hidden.
I decided to check whether more CPUs lead to a higher thread migration rate, meaning how often rebalance leads to a thread being scheduled on a different CPUs run queue. So I added some quick hacky stats to get some idea. Comparing the average thread migration count with two CPUs and twelve CPUs didn't show that there is any real difference in the number of times threads migrate between CPU cores.
Looking at enqueue(Thread*, bool), one of the only part that isn't really instrumented is this:
int32 heapPriority = do_get_heap_priority(targetCPU);
if (threadPriority > heapPriority
|| (threadPriority == heapPriority && rescheduleNeeded)) {
if (targetCPU->ID() == smp_get_current_cpu())
gCPU[targetCPU->ID()].invoke_scheduler = true;
else {
smp_send_ici(targetCPU->ID(), SMP_MSG_RESCHEDULE, 0, 0, 0,
NULL, SMP_MSG_FLAG_ASYNC);
}
}
So if it has been decided by the rebalance() strategy to enqueue this in another thread's run queue, then we write a message into its smp message queue and send a ICI message via APIC.
After instrumenting this code it definitely seems that smp_send_ici() is the [hottest function](https://imgur.com/a/L90TEQz).
I added some additional hacky stats to see which part of smp_send_ici() is slow. I suspected that we may have contention in the compare-and-set adding the smp message to the target CPUs queue, or waiting for the interrupt was slow.
After adding a quick and dirty hack to get an understanding of how many CAS attempts are required, and how long arch_smp_send_ici(int32) took, I got some interesting results.
- CAS attempts: avg=1, max=1
- Send ICI Latency: avg=3611233ns, max=10557740ns
Average 3ms, max 10ms! So it doesn't seem like there is any contention for the SMP message queue, but waiting for the interrupt takes forever.
Note that the performance is not NUMA related, as VirtualBox reports a single NUMA node to the guest OS, and I've been running other operating systems for work with 12 cores for several months with no issue.
I'm unsure as to whether this is a problem on other platforms, since I only have x86_64 machines with this many CPUs that I can test with.
Attachments (2)
{kind=link}
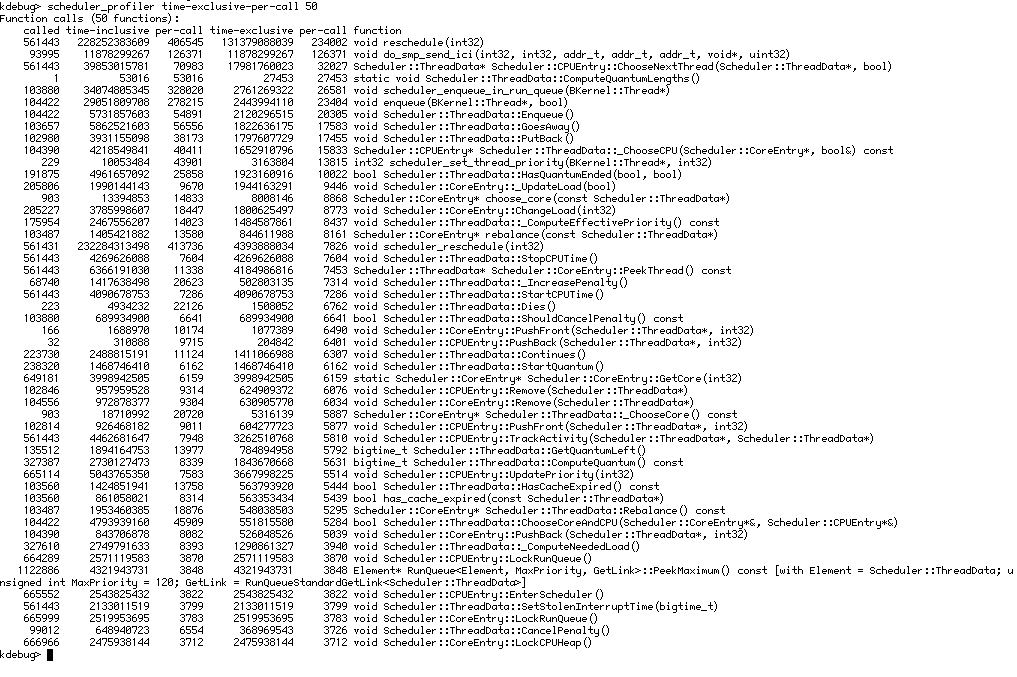{kind=link}
{kind=link}
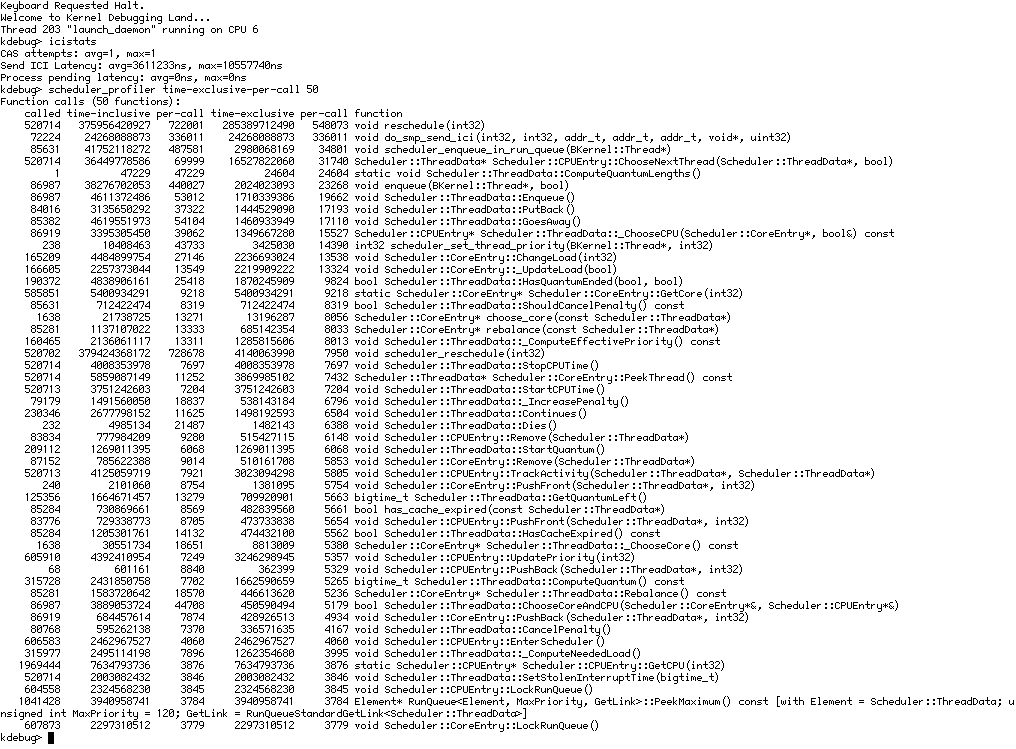{kind=link}
Change History (18)
by , 6 years ago
| Attachment: | 20190322_12-cores-with-more-instrumentation.png added |
|---|
by , 6 years ago
| Attachment: | 20190323_12-core_icistats.png added |
|---|
Stats collected to see which part of smp_send_ici() is slow on my system.
comment:1 by , 6 years ago
At this point I need to do some research to understand how APIC and IPI are supposed to work. I see one of two possibilities here:
- The interrupt is being done in such a way that is unnecessarily costly.
- OR the scheduler needs to behave differently with a large number of CPUs.
If it turns out that this is already implemented correctly, then I think it's worth exploring whether it makes sense to change the scheduler to group CPU cores together into smaller groups, and try to avoid migrating threads between those groups.
I'm curious to see if you guys can find any bugs in my analysis so far.
comment:2 by , 6 years ago
ICIs taking 10ms is unbelievably ridiculous and should not occur. I know kallisti5 runs Haiku on his Ryzen and does not have these problems, and the same is true for other people running Haiku on 16 core+ systems. So the real problem is probably that the ICIs are taking so long.
Have you tried this on master? There were some IDT issues that may actually be related here which were fixed since the beta. Those seemed to substantially improve performance even on multicore systems that worked already.
comment:3 by , 6 years ago
Yeah I have been working off of master. The performance problem is definitely still there.
Does kallisti5 have a Threadripper CPU or a Ryzen 3/5/7?
I'm going to spend some time looking around to see if there is something special about this hardware.
comment:4 by , 6 years ago
I think he has a Ryzen 7.
If those benchmark numbers came from VirtualBox, I wouldn't trust them; their APIC implementation has atrocious performance. Try using KVM instead if you can.
comment:5 by , 6 years ago
This looks potentially relevant: https://github.com/freebsd/freebsd/commit/568f89709482fc5c1c8e55c1ecbfe27033d9d85d
If the sleep mode we are using by default is somehow broken on Ryzen/Threadripper under certain scenarios, then perhaps interrupts will not wake us out of it, explaining the unbelievable latency.
comment:6 by , 6 years ago
We use "mwait" in the "intel_cstates" power module. So, blacklisting that and seeing if performance improves will be key here.
comment:7 by , 6 years ago
I haven't had time to work on this since Saturday, but I'll collect more info tomorrow or Wednesday.
My plan is:
- To try to reproduce with kvm
- To try reproducing with bare metal again now that I have more instrumentation (I didn't have scheduler profiler in the build at all when I first saw this)
- Try blacklisting intel_cstates
- Look into the lead waddlesplash found in the freebsd repo.
comment:8 by , 6 years ago
I haven't had much time to spend on this but I do have an update.
- I could not reproduce this with kvm.
- I ran into some other issue that's preventing me from booting on bare metal.
- Blacklisting intel_cstates when running in VirtualBox doesn't seem to make a difference.
I tested kvm with the following command and couldn't reproduce this problem. ICI latency is on the order of 6-10μs.
qemu-system-x86_64 -m 1024 -cdrom haiku-anyboot.iso -enable-kvm -smp 12
So since I'm not currently able to boot to the desktop on bare metal, I need to spend some time debugging to figure out why it isn't working. It's possible that before I started deep diving on this, I mistook some other hardware issue for the same thing I was observing in VirtualBox.
This may turn out to be a VirtualBox only problem. It may be a bug in VirtualBox, but I routinely run Linux and Windows guests with the same configuration for work without issue.
I'll have lots of time this weekend to spend on this.
comment:9 by , 6 years ago
Yes, that's much more sane. VirtualBox has always had some really nasty bug with their ICI implementation...
Please find me on IRC this weekend and I can help you tackle this, then :)
comment:10 by , 6 years ago
| Summary: | CPU scheduler has scalability issues on SMP systems with 10+ CPUs → High ICI latency bogging down scheduler on VirtualBox |
|---|
comment:11 by , 3 years ago
FreeBSD's apparently equivalent code: https://xref.landonf.org/source/xref/freebsd-current/sys/x86/x86/local_apic.c#2050
Despite different naming, looks pretty similar to what we have to my eyes at least.
comment:12 by , 3 years ago
I notice our send_ici implementation calls cpu_pause unconditionally. Maybe that incurs some substantial overhead in VirtualBox.
comment:13 by , 3 years ago
Ah, rereading your ticket description I see you already eliminated that as a possibility.
I wonder, does your VirtualBox machine have X2APIC enabled? The documentation says it is by default, but maybe it isn't for older VMs (or "Unknown" ones.) This can have a pretty big impact on ICI delivery. According to the documentation it can be enabled with VBoxManage modifyvm "name" --x2apic on.
comment:14 by , 17 months ago
| Component: | - General → System/Kernel |
|---|
comment:16 by , 8 months ago
| Blocking: | 18936 added |
|---|
Scheduler profile after instrumenting smp_send_ici().