

Opened 4 years ago
Closed 3 months ago
#16159 closed bug (no change required)
PANIC: Invalid concurrent access to page... (start), ... accessed by: -134217729 [bt: file_cache]
| Reported by: | ttcoder | Owned by: | nobody |
|---|---|---|---|
| Priority: | normal | Milestone: | Unscheduled |
| Component: | System/Kernel | Version: | R1/Development |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | ||
| Platform: | All |
Description
One of our beta-testing stations has been getting a string of KDLs when running a backup script (script based on /bin/cp, copying mp3s from one BFS partition to another), here's the latest KDL.
Contrarily to most other tickets like this one, the backtrace mentions file_cache_read
Backtrace, context, similar tickets list, coming up
Attachments (2)
{kind=link}
{kind=link}
{kind=link}
Change History (15)
comment:2 by , 4 years ago
Doing ticket archeology, I see that #5228 #5242 #5544 #5919 have all been closed after VM fixes ; similar message, but different backtrace (vm instead of file_cache) Stuff also happens when Tuneprepper fork()s : #12518 #12408 (but we're no longer selling that app, so could close those tickets as invalid).
Recent active tickets are #13274, and especially #13205 (that latter one is in file_cache_write(), so closest to this ticket?)
Notes to self:
- this occurs with hrev53894.. Upgrade this station (at least) to beta2 when it's out ? I see there's been some fixes done to the file cache recently. And refrain from doing backups in the meantime. Not much longer to wait anyway.
- if this still occurs with beta2, ping this ticket to get it looked into in a few weeks ?
- that stations also has BFS errors reported in syslog, but seems unrelated to the KDL since other KDL tickets listed above don't seem to have BFS errors. Anyway here they are:
bfs: InitCheck:325: Bad data bfs: inode at 2099031 is already deleted! bfs: GetNextMatching:615: Bad data bfs: could not get inode 2099031 in index "size"! bfs: InitCheck:325: Bad data bfs: inode at 2099032 is already deleted! bfs: GetNextMatching:615: Bad data bfs: could not get inode 2099032 in index "size"!
This one is hidden among unrelated logs, spotted it by chance:
2020-05-28 09:43:44 KERN: bfs: volume reports 49876469 used blocks, correct is 49509747
(typical Haiku syslogging : important information written in all-lowercase, hidden in a ocean of noisy informational reporting *g*)
comment:3 by , 4 years ago
Yes, #15912 and its fix may be related here, if the file cache was indeed overwriting pages (or disk structures). It seems unlikely ... but worth a try.
Those messages look like disk corruption. Running a "checkfs" should resolve them (but beware this may unexpectedly delete a lot of files on 32-bit and more rarely on 64-bit, take backups first!)
comment:4 by , 4 years ago
#16175 may also be related here, as it was a random kernel memory corruption that was also just fixed.
comment:5 by , 4 years ago
Touché. Mentionned that to Dane earlier this morning, awaiting answer. The station in question happens to be running an hrev from late Feb (the bug was introduced in early February) indeed. We'll try to revert the station to a late-january style hrev (can't upgrade him to beta2 candidate, since that suffers from a media memory leak regression as discussed in the other ticket).
comment:6 by , 4 years ago
If you are referring to #16031, did you confirm this occurs outside of MediaPlayer?
comment:7 by , 4 years ago
Reverting that station to hrev53855 to dodge the BQuery bullet, since that one reportedly is part of their stability problems. We'll see if this closes this ticket or at least helps with it. However it would be very nice to update to beta2 so when time permits I'll try to gather more data, run leak_analyser.sh on the now traditional ten-liner BMediaFile test.
comment:8 by , 4 years ago
They've got a second KDL this morning, turns out the hrev "downgrade" did not work, from what I gather the wrong hpkg's were written to the wrong location, hmmm. We're going to look at an easier way to get them out of this pinch, most likely updating them to beta2 or to the latest nightly. We'll take our chances with the media leak, it can't be as bad as a KDL :-)
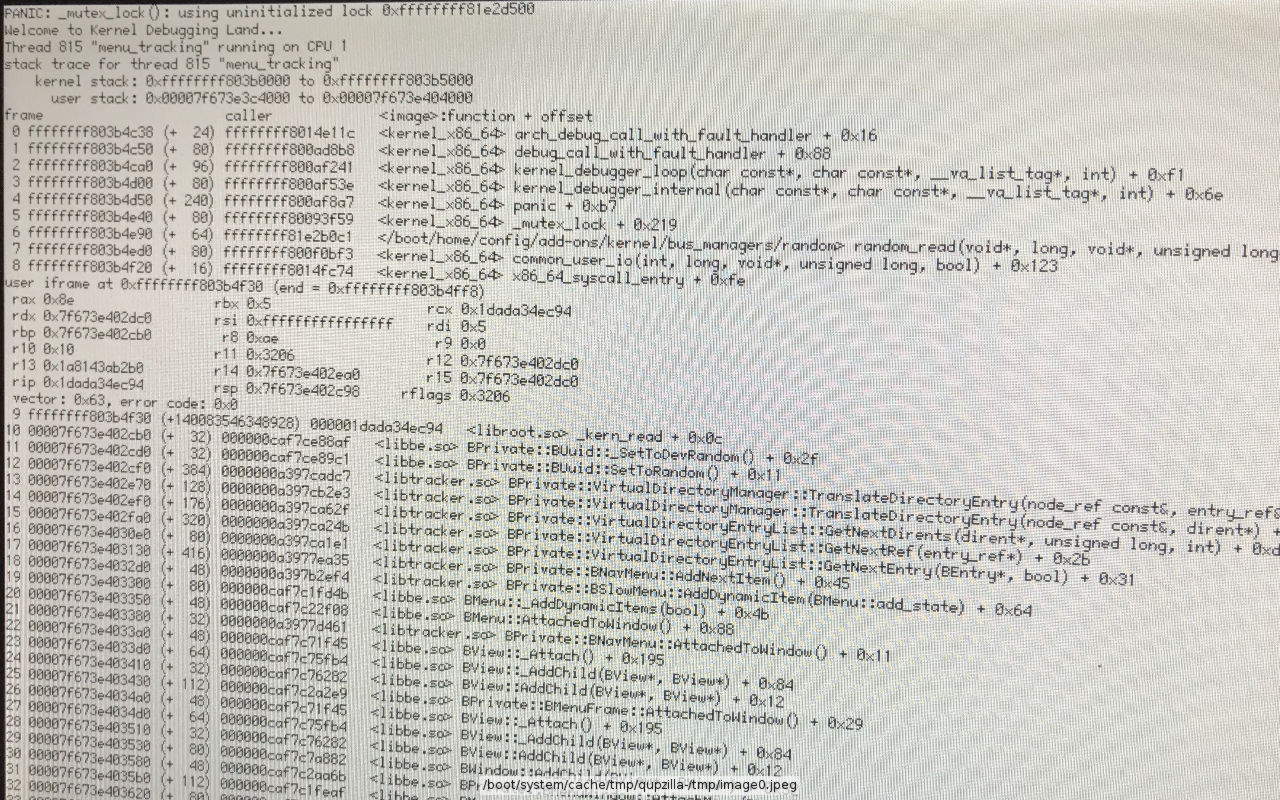
(for the curious: attached the KDL above, this one is in mutex_lock())
comment:9 by , 4 years ago
It appears you have a "random" driver lying around inside /boot/home. Why and how is that? Did you put the .hpkg's there? We changed mutex ABI recently, so, that would explain the KDL; easy fix: just remove the system packages from ~/config/packages.
When downgrading, you can just run "pkgman install haiku...hpkg" and it will prompt you to downgrade (and of course you can include other packages on that command line.)
comment:10 by , 4 years ago
Good catch, indeed inspecting the machine on remote I see they've somehow installed a recent nightly "haiku....hpkg" file into ~/config/packages (!) along with a dozen others. Transmitting the above info to help them straighten things out..... My preference would be to format/initialize anyway, in order to also get rid of the BFS corruptions in one fell swoop. Hopefully this saga will reach an end soon...
by , 4 years ago
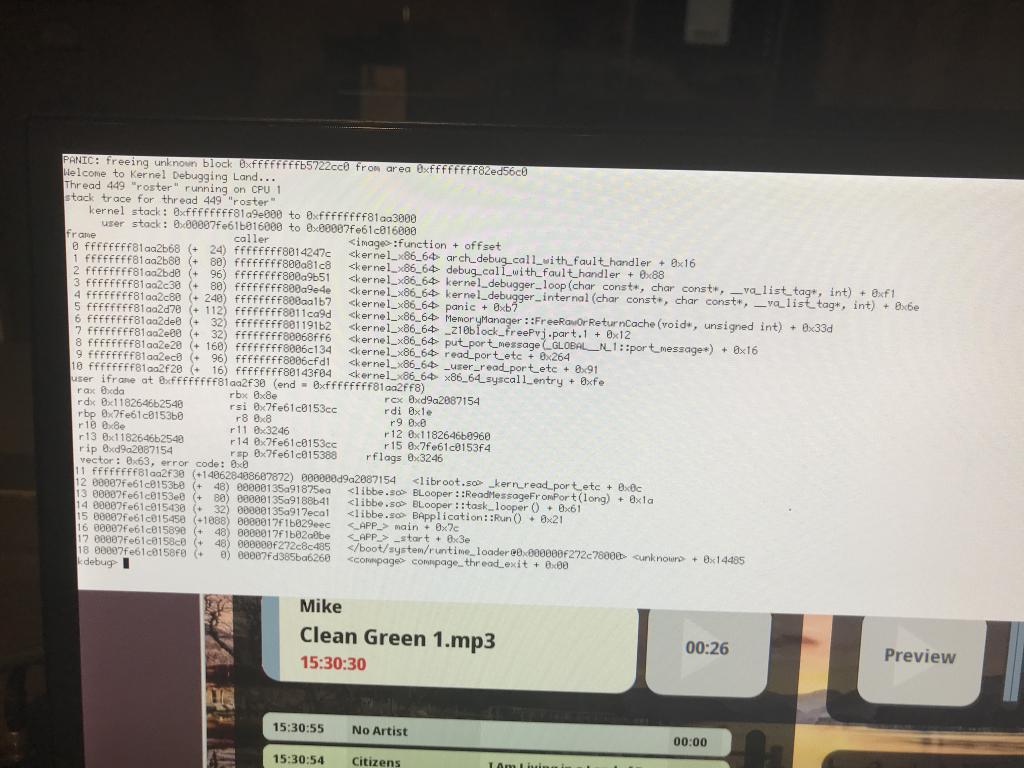
| Attachment: | panic-freeing-unknown-block.jpeg added |
|---|
"panic freeing unknown block.. from area.." (backtrace mentions _kern_read_port(), block_free()..)
comment:11 by , 4 years ago
That station got this today. System seems to be clean now, both the syslog contents and the hierarchy of the home folder, and the new backtrace seems unrelated to the one that started this ticket, so not sure what to make of it... Maybe we should try again to revert him to an older hrev
, block_free()..)")
comment:13 by , 3 months ago
| Resolution: | → no change required |
|---|---|
| Status: | new → closed |
We haven't tried to resume sales or testing on the Be/Hai side of things in years, so no. We might take a look at R1/beta5 when it's out. Closing.
The KDL got saved in "previous_syslog".. First time I ever see that happen. The bt mentions
file_cache_readandfree_cached_page. The negative thread number looks incorrect, like in similar tickets of this type.PANIC: Invalid concurrent access to page 0xffffffff883c49e0 (start), currently accessed by: -134217729 Welcome to Kernel Debugging Land... Thread 1409 "cp" running on CPU 0 stack trace for thread 1409 "cp" kernel stack: 0xffffffff81aa6000 to 0xffffffff81aab000 user stack: 0x00007fd4c085d000 to 0x00007fd4c185d000 frame caller <image>:function + offset 0 ffffffff81aaaa78 (+ 24) ffffffff8014e1bc <kernel_x86_64> arch_debug_call_with_fault_handler + 0x16 1 ffffffff81aaaa90 (+ 80) ffffffff800ad8b8 <kernel_x86_64> debug_call_with_fault_handler + 0x88 2 ffffffff81aaaae0 (+ 96) ffffffff800af241 <kernel_x86_64> kernel_debugger_loop(char const*, char const*, __va_list_tag*, int) + 0xf1 3 ffffffff81aaab40 (+ 80) ffffffff800af53e <kernel_x86_64> kernel_debugger_internal(char const*, char const*, __va_list_tag*, int) + 0x6e 4 ffffffff81aaab90 (+ 240) ffffffff800af8a7 <kernel_x86_64> panic + 0xb7 5 ffffffff81aaac80 (+ 64) ffffffff8013abc3 <kernel_x86_64> free_cached_page(vm_page*, bool) + 0x103 6 ffffffff81aaacc0 (+ 160) ffffffff8013af4c <kernel_x86_64> free_cached_pages(unsigned int, bool) + 0x22c 7 ffffffff81aaad60 (+ 128) ffffffff8013b51b <kernel_x86_64> reserve_pages(unsigned int, int, bool) + 0x21b 8 ffffffff81aaade0 (+ 176) ffffffff800517e7 <kernel_x86_64> cache_io(void*, void*, long, unsigned long, unsigned long*, bool) + 0x77 9 ffffffff81aaae90 (+ 64) ffffffff80052ac6 <kernel_x86_64> file_cache_read + 0x46 10 ffffffff81aaaed0 (+ 80) ffffffff800f0bf3 <kernel_x86_64> common_user_io(int, long, void*, unsigned long, bool) + 0x123 11 ffffffff81aaaf20 (+ 16) ffffffff8014fd14 <kernel_x86_64> x86_64_syscall_entry + 0xfe user iframe at 0xffffffff81aaaf30 (end = 0xffffffff81aaaff8) rax 0x8e rbx 0x0 rcx 0x129e5984c94 rdx 0x16e2c5ab000 rsi 0xffffffffffffffff rdi 0x3 rbp 0x7fd4c185b090 r8 0x0 r9 0x0 r10 0x20000 r11 0x3202 r12 0x20000 r13 0x16e2c5cb000 r14 0x0 r15 0x0 rip 0x129e5984c94 rsp 0x7fd4c185b078 rflags 0x3202 vector: 0x63, error code: 0x0 12 ffffffff81aaaf30 (+140553876078944) 00000129e5984c94 <libroot.so> _kern_read + 0x0c 13 00007fd4c185b090 (+ 176) 0000005faa9720a7 <cp> usage (nearest) + 0xf27 14 00007fd4c185b140 (+ 896) 0000005faa9753ff <cp> cached_umask (nearest) + 0x2aef 15 00007fd4c185b4c0 (+ 944) 0000005faa9743e8 <cp> cached_umask (nearest) + 0x1ad8 16 00007fd4c185b870 (+ 944) 0000005faa9743e8 <cp> cached_umask (nearest) + 0x1ad8 17 00007fd4c185bc20 (+ 944) 0000005faa9743e8 <cp> cached_umask (nearest) + 0x1ad8 18 00007fd4c185bfd0 (+ 64) 0000005faa97661d <cp> copy + 0x7d 19 00007fd4c185c010 (+ 336) 0000005faa97183b <cp> usage (nearest) + 0x6bb 20 00007fd4c185c160 (+ 336) 0000005faa97042b <cp> main + 0x6eb 21 00007fd4c185c2b0 (+ 48) 0000005faa970701 <cp> _start + 0x51 22 00007fd4c185c2e0 (+ 48) 00000180db16f485 </boot/system/runtime_loader@0x00000180db15b000> <unknown> + 0x14485 23 00007fd4c185c310 (+ 0) 00007fff277da260 <commpage> commpage_thread_exit + 0x00 initial commands: page -m 0xffffffff883c49e0; sc -134217729; cache _cache PAGE: 0xffffffff883c49e0 queue_next,prev: 0xffffffff81aaace0, 0x0000000000000000 physical_number: 0x125b86 cache: 0xffffffffbecf0628 cache_offset: 5006 cache_next: 0xffffffff883c4a30 state: cached wired_count: 0 usage_count: 0 busy: 0 busy_writing: 0 accessed: 0 modified: 0 accessor: -134217729 area mappings: all mappings: aspace 1, area 1: 0xffffff0125b86000 (rw modified accessed)