

Opened 23 months ago
Closed 11 months ago
#18203 closed bug (fixed)
Unstable iperf3 results with strange cpu usage
| Reported by: | zgdump | Owned by: | nobody |
|---|---|---|---|
| Priority: | normal | Milestone: | R1/beta5 |
| Component: | Network & Internet | Version: | R1/beta4 |
| Keywords: | Cc: | ||
| Blocked By: | #12876 | Blocking: | |
| Platform: | All |
Description (last modified by )
On my machines, on any network interface in Haiku, files are downloaded very slowly, and heavy ones cannot be downloaded at all. The speed hardly exceeds 600-700 kilobytes. I was offered to run and test iperf3 over localhost and:
TCP is very unstable. $ iperf3 -c localhost -R -t 100
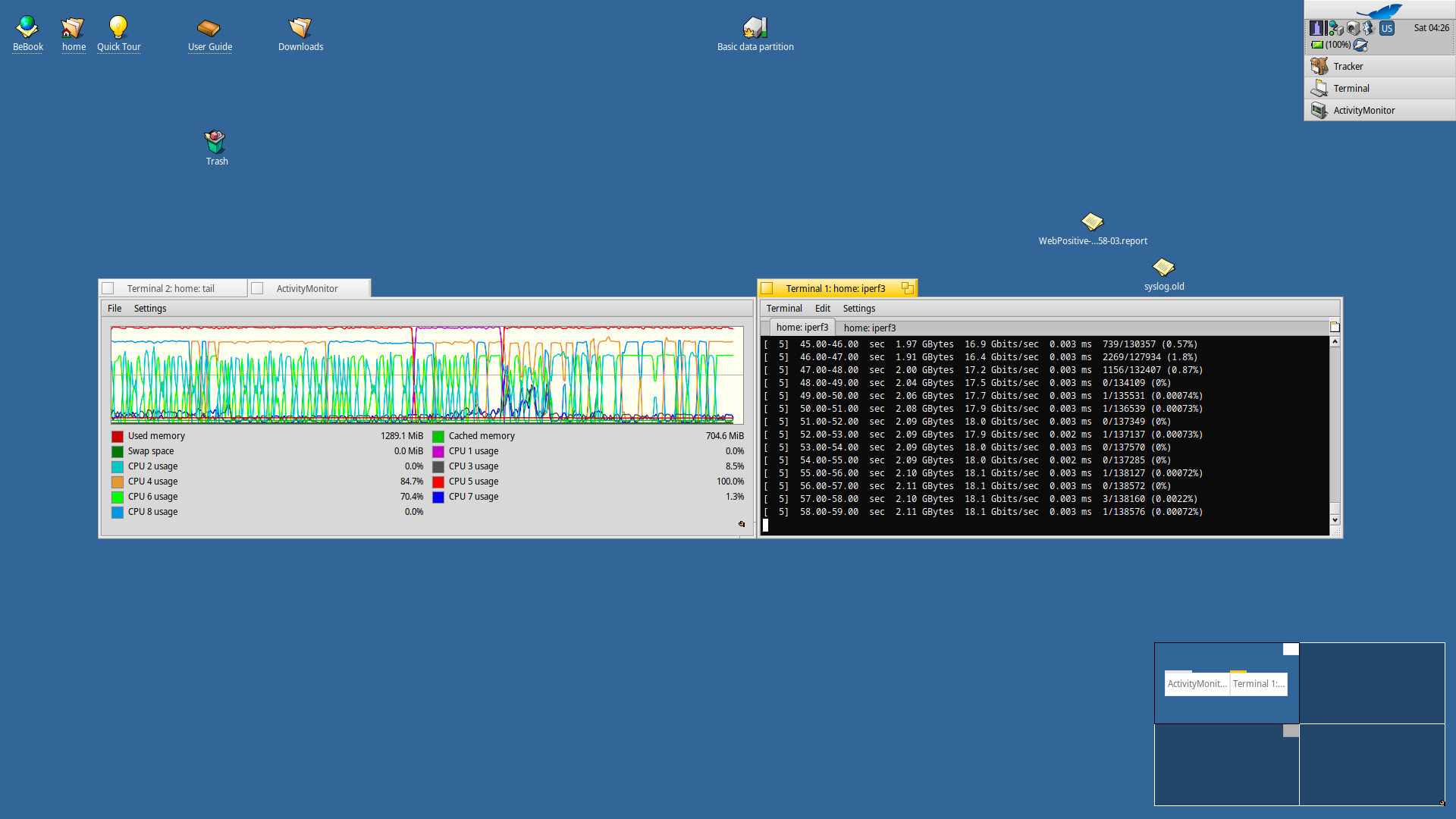
See screenshot_tcp.png and iperf3_and_loop_consumer.mp4
UDP is stable, but consuming too much CPU. $ iperf3 -c localhost -R -t 100 -u -b 0
See screenshot_udp.png
Each screenshot also shows the Activity Monitor.
Ifconfig and About are also included
Attachments (13)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (41)
by , 23 months ago
| Attachment: | screenshot_udp.png added |
|---|
by , 23 months ago
| Attachment: | screenshot_tcp.png added |
|---|
by , 23 months ago
| Attachment: | ifconfig.jpg added |
|---|
by , 23 months ago
by , 23 months ago
| Attachment: | iperf3_and_loop_consumer.mp4 added |
|---|
comment:1 by , 23 months ago
| Description: | modified (diff) |
|---|
comment:2 by , 23 months ago
| Component: | - General → Network & Internet |
|---|
comment:3 by , 23 months ago
comment:5 by , 23 months ago
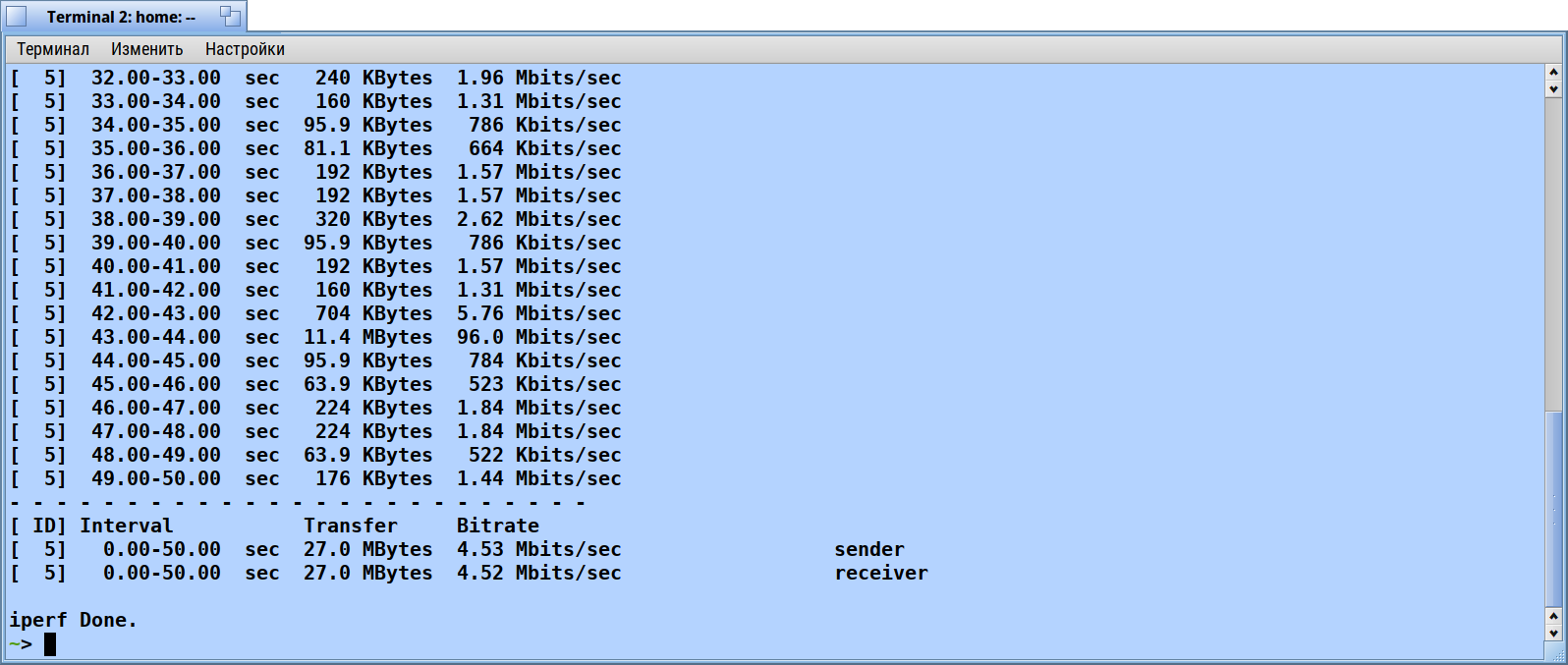
After experimenting in the Russian chat, we came to the conclusion that the situation is better on AMD. But problems with stability and speed were repeated for a many people on different processors
comment:6 by , 23 months ago
Please attach a syslog.
This seems pretty strange because I get much better speeds than 600-700KB/s even when downloading from the internet. And I just ran a test with iperf on localhost in a 2-core VMware VM, and I got much better results than are shown here:
[ 1] local 127.0.0.1 port 40145 connected with 127.0.0.1 port 5001 [ ID] Interval Transfer Bandwidth [ 1] 0.00-10.36 sec 274 MBytes 222 Mbits/sec
Something else must be going on to cause the high CPU usage and low throughput. Can you boot with ACPI disabled? If so, can you rerun the test and see what happens? Blocklisting the "power" drivers (CPU idle, etc.) is the next thing to be tried after that.
comment:7 by , 23 months ago
Uh, running it again gave wildly different results:
[ 1] 0.00-10.04 sec 13.5 MBytes 11.3 Mbits/sec
and after that:
[ 1] 0.00-20.14 sec 7.50 MBytes 3.12 Mbits/sec
So, that's pretty bad! But my CPU usage remained low the whole time, though, so there's still something fishy going on.
comment:9 by , 23 months ago
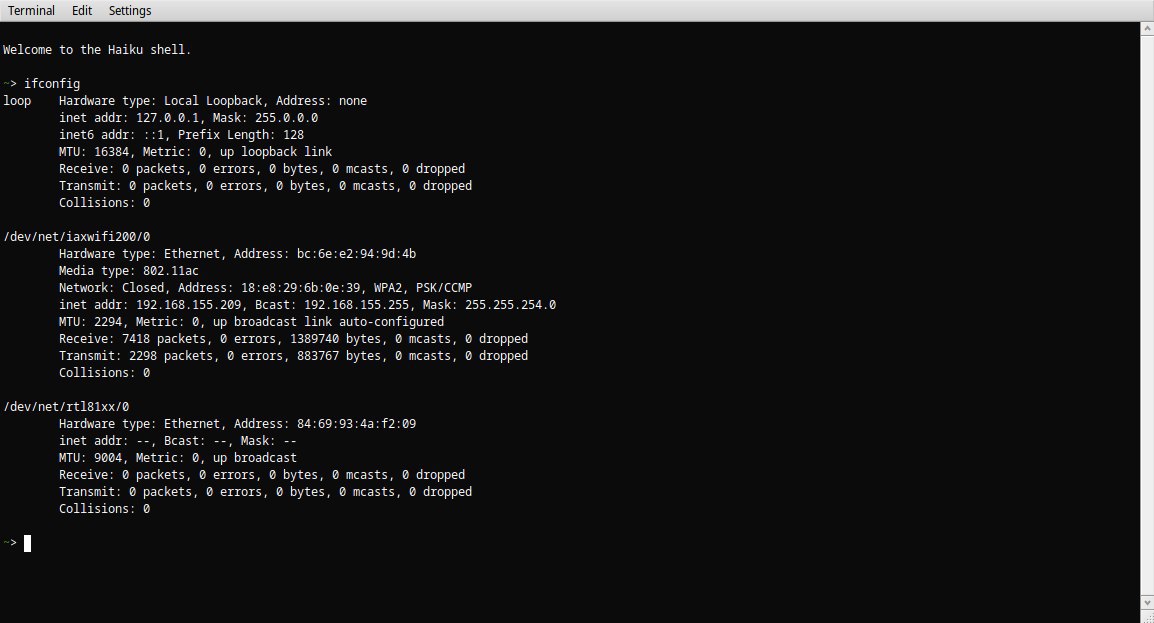
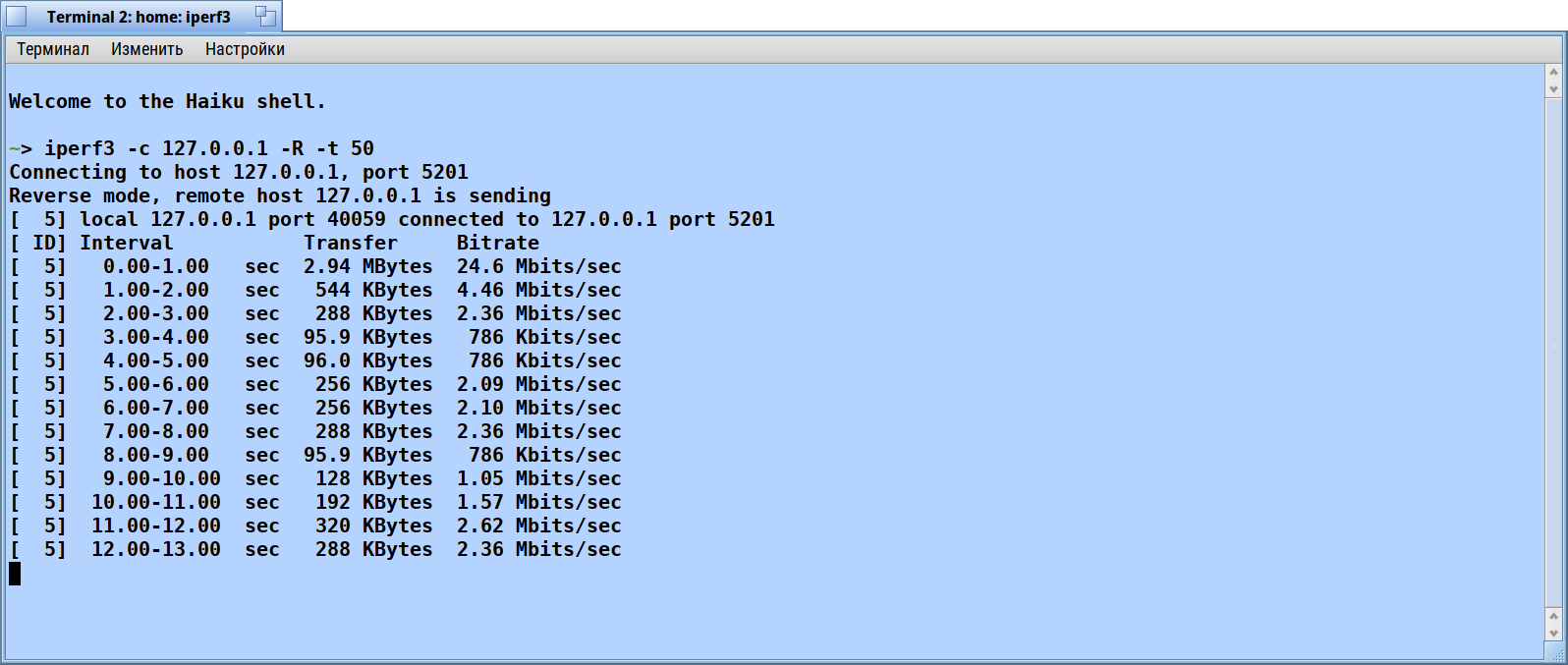
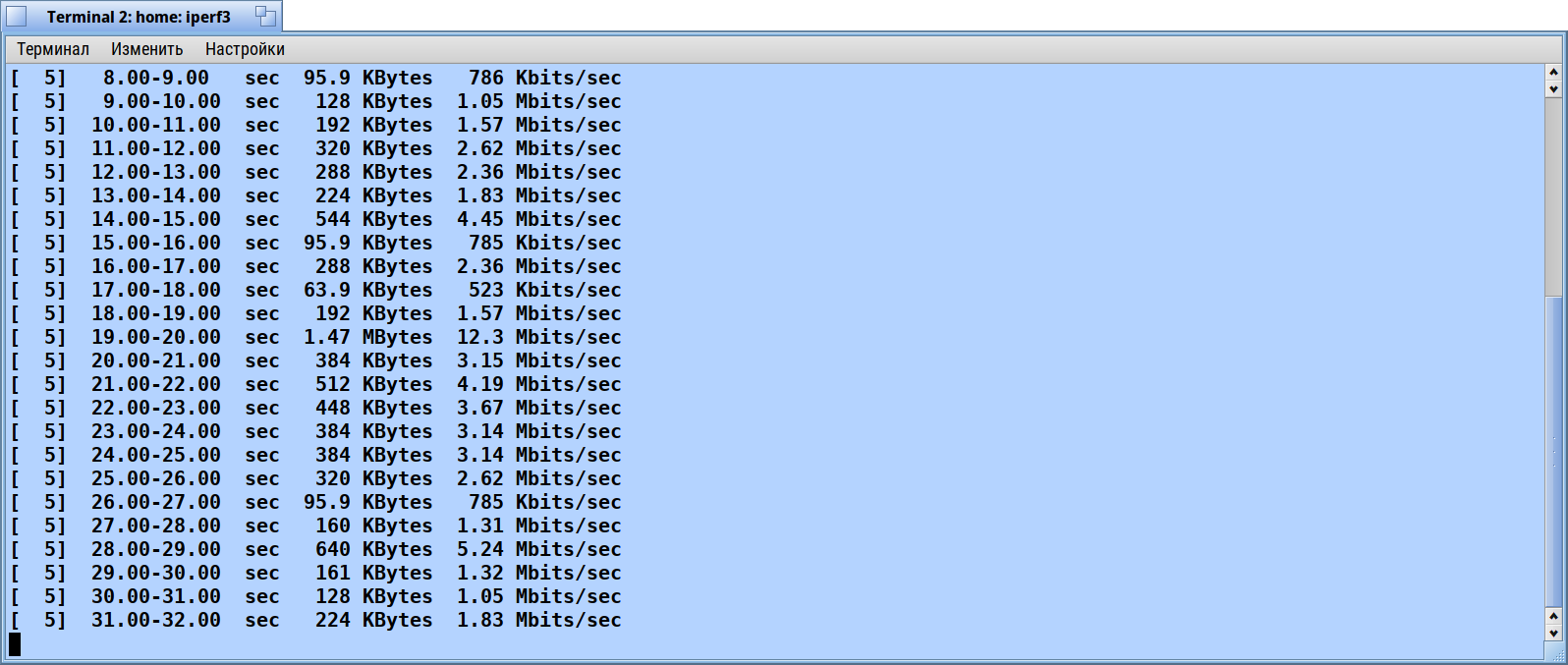
64 bit hrev56578+65 R1Beta4 Intel Core i5-8400 Intel processor in energy saving mode. Network disabled.
~> iperf3 -c 127.0.0.1 -R -t 50
by , 23 months ago
| Attachment: | screenshot406CPU.png added |
|---|
by , 23 months ago
| Attachment: | screenshot407CPU.png added |
|---|
by , 23 months ago
| Attachment: | screenshot408CPU.png added |
|---|
by , 23 months ago
| Attachment: | screenshot406.png added |
|---|
by , 23 months ago
| Attachment: | screenshot407.png added |
|---|
by , 23 months ago
| Attachment: | screenshot408.png added |
|---|
by , 23 months ago
| Attachment: | screenshot409.png added |
|---|
comment:11 by , 23 months ago
@waddlesplash
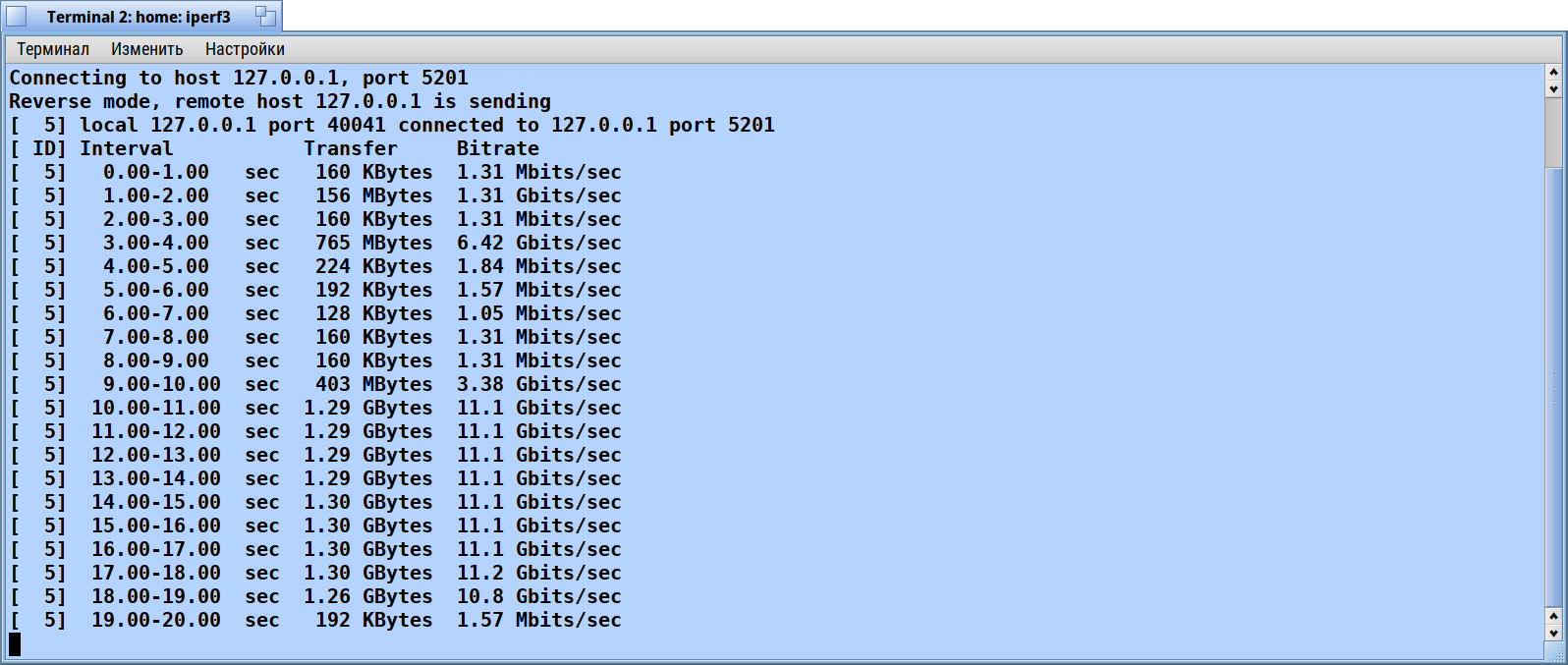
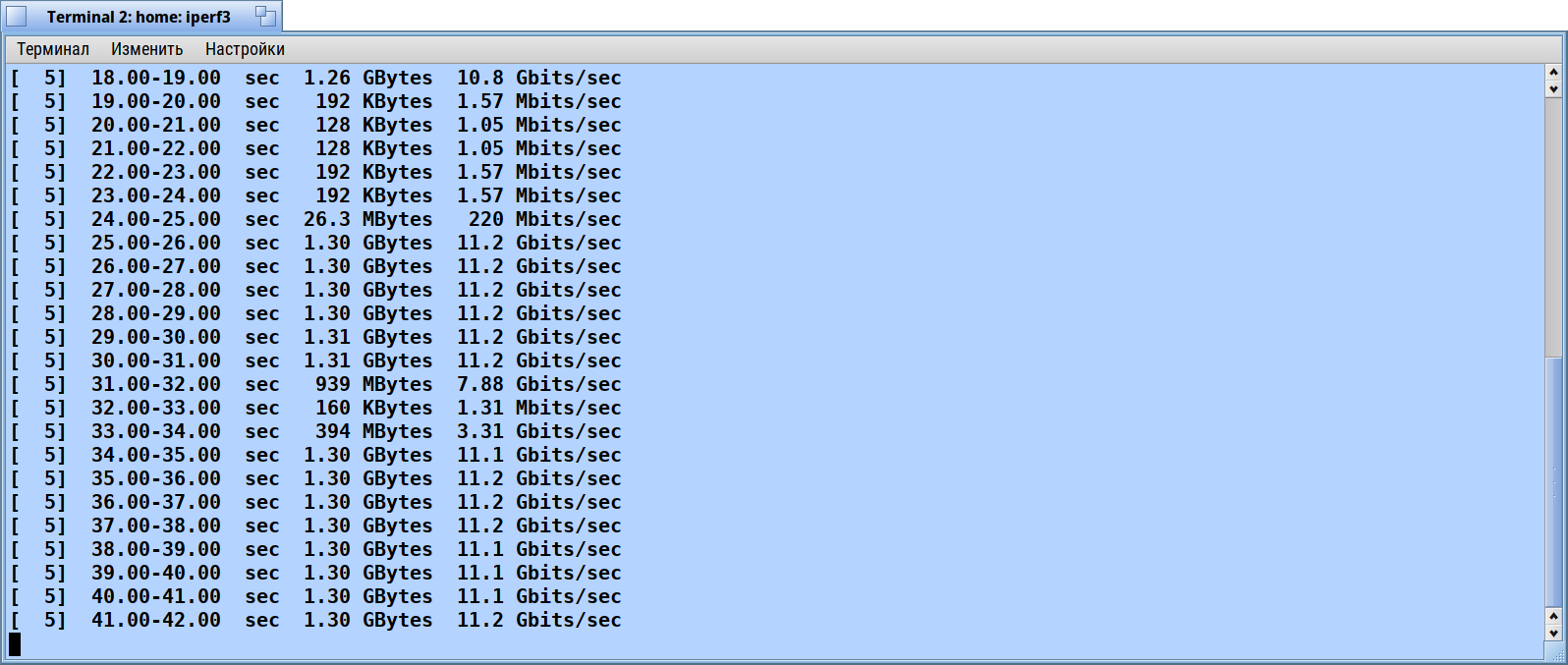
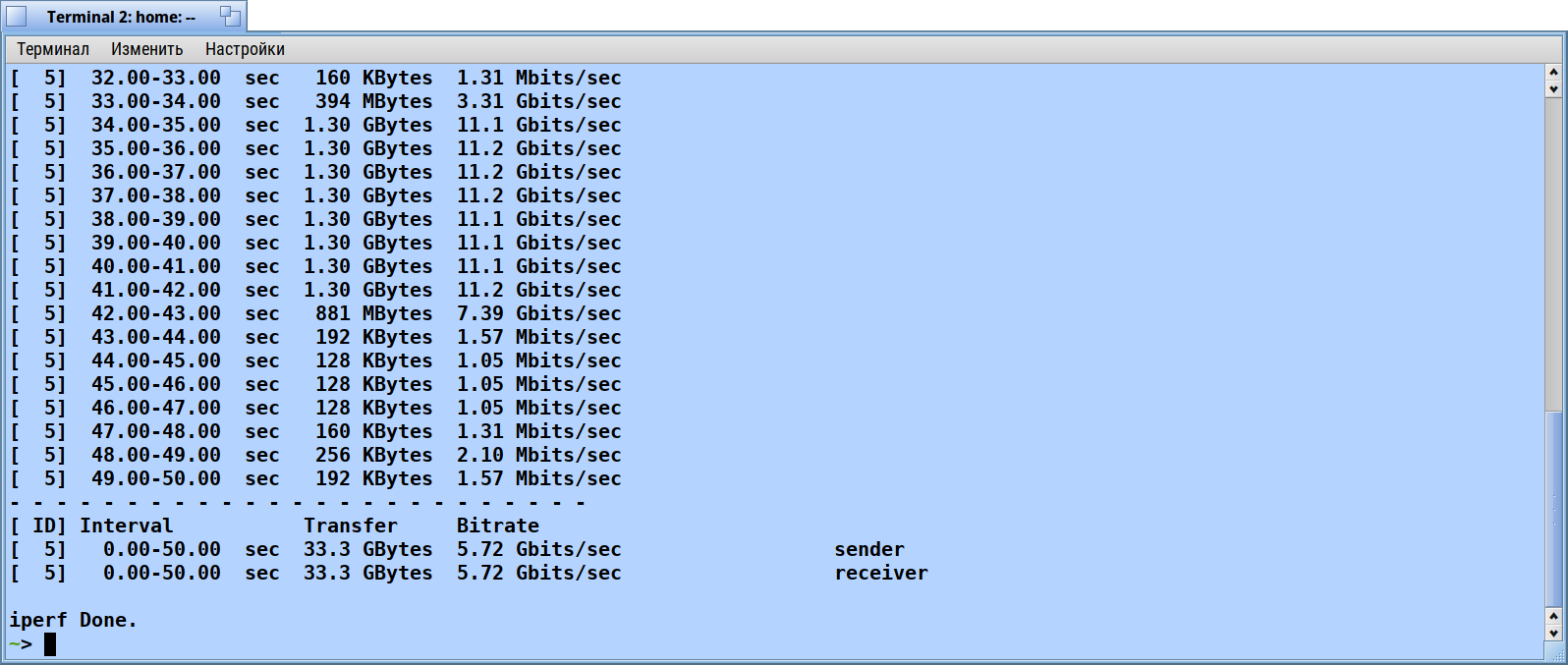
I repeated tests without acpi and with acpi but without intel power drivers. Disabling acpi give no effect. But disabling intel power drivers givs the miracle: iperf over localhost shows stable ~10 gigabit without drops and jumps.
Syslogs, iperf3 logs attached.
by , 23 months ago
comment:13 by , 23 months ago
This isn't really a fix for this problem, but I noticed that the default MTU for loopback is 16KiB. Changing it to 64KiB seems to improve throughput by about 26% in some experiments I've done, and it seems like the throughput is a little more stable, not fluctuating as much as before.
I suspect this is because the loop consumer thread isn't saturating the CPU as often, as more data is being packed into larger frames.
comment:14 by , 22 months ago
I see an opportunity for about 150x improvement in throughput in the test setup I have been using.
I have been using a kvm VM with 1 CPU core and 8GB of RAM, running iperf3 -s and iperf3 -c localhost -R. The throughput I get with this setup is pretty abysmal. The throughput according to iperf is pretty unstable and fluctuates between around 5Mbps to around 50Mbps. The average tends to be around 12Mbps.
With just this setup it's kinda hard to see what's going on since throughput is low but CPU utilization is also low. But when I run iperf -s on a Linux computer on my network and just run iperf -c on the Haiku VM it becomes a lot more clear what's going on. CPU utilization is 100% and the /dev/net/ipro1000/0 consumer thread is the busiest thread on the system by far. There is one of these threads for every network interface, including loopback, which is called "loop consumer". It's job is to receive a net_buffer from a FIFO of buffers enqueued by the network device and hand them off to the protocol which handles those buffers. For example, ipv4 and tcp.
Most of the CPU time in this "consumer" thread is dominated by TCPEndpoint::_SendQueued, called by TCPEndpoint::SegmentReceived. This seems a bit counter-intuitive, since this thread should almost always be delivering messages to the receive queue of the TCPEndpoint and maintaining a timer which should enqueue Ack segments to be sent back to the peer.
It seems like one problem is with TCPEndpoint::DelayAcknowledge(). This function is called by TCPEndpoint::SegmentReceived. The goal is to make sure that the kernel will periodically send an ACK segment back to the remote after receiving some segments. To get good throughput, a typical strategy is to just set a timer which will acknowledge the largest sequence number that has been received when the timer expires. This lets you receive many segments before sending a single Ack acknowledging all of the segments received.
This function does a variation of that which ends up sending many more Acks than are necessary. When a segment is received, DelayAcknowledge will schedule a timer to send an Ack. But when a segment is received before that timer has expired, it falls back to just sending an Ack immediately from within that same thread.
It handles this fallback case by calling TCPEndpoint::SendAcknowledge(true), which calls TCPEndpoint::_SendQueued(true, 0). This dequeues a segment from the send buffer and slaps an ACK onto it, or sends a lone ACK segment if there isn't one ready, calling into the code which enqueues a new frame for the network device to send out. This is done by calling into ipv4 and datalink modules, both of which will acquire mutexes.
The net effect is that this thread sends an acknowledgement for every other segment received, and each of those acknowledgements come with some potential waiting for mutexes.
A simple change of just always letting the timer trigger acknowledgement send makes a huge difference in throughput. With this patch applied, throughput goes from a very unstable 12Mbps to a steady 1.75Gbps. About 150x increase in throughput using only the loopback interface.
diff --git a/src/add-ons/kernel/network/protocols/tcp/TCPEndpoint.cpp b/src/add-ons/kernel/network/protocols/tcp/TCPEndpoint.cpp
index 42ed62ceabc0..4d5cd34558aa 100644
--- a/src/add-ons/kernel/network/protocols/tcp/TCPEndpoint.cpp
+++ b/src/add-ons/kernel/network/protocols/tcp/TCPEndpoint.cpp
@@ -1119,16 +1119,17 @@ TCPEndpoint::IsLocal() const
status_t
TCPEndpoint::DelayedAcknowledge()
{
- if (gStackModule->cancel_timer(&fDelayedAcknowledgeTimer)) {
- // timer was active, send an ACK now (with the exception above,
- // we send every other ACK)
- T(TimerSet(this, "delayed ack", -1));
- return SendAcknowledge(true);
+ // if (gStackModule->cancel_timer(&fDelayedAcknowledgeTimer)) {
+ // // timer was active, send an ACK now (with the exception above,
+ // // we send every other ACK)
+ // T(TimerSet(this, "delayed ack", -1));
+ // return SendAcknowledge(true);
+ // }
+ if (!gStackModule->is_timer_active(&fDelayedAcknowledgeTimer)) {
+ gStackModule->set_timer(&fDelayedAcknowledgeTimer,
+ TCP_DELAYED_ACKNOWLEDGE_TIMEOUT);
+ T(TimerSet(this, "delayed ack", TCP_DELAYED_ACKNOWLEDGE_TIMEOUT));
}
-
- gStackModule->set_timer(&fDelayedAcknowledgeTimer,
- TCP_DELAYED_ACKNOWLEDGE_TIMEOUT);
- T(TimerSet(this, "delayed ack", TCP_DELAYED_ACKNOWLEDGE_TIMEOUT));
return B_OK;
}
When just using iperf3 in client mode with a remote Linux serve, the throughput increase is closer to 4x. Must more modest but still substantial.
Now the function using the most CPU in the device consumer thread is just computing checksums, so I think that there isn't much low hanging left fruit in that thread for this particular workload.
comment:15 by , 20 months ago
ambroff: is there any reason you didn't submit this patch for review, at least? If you've just been busy, I can clean it up a bit and then merge it.
comment:16 by , 20 months ago
Yeah I have had a busy couple of months at work so I haven't had time to work on this recently.
I did measure a large increase in throughput for that specific case. I wasn't comfortable merging that change yet because I was unsure of the correctness and some care needs to be taken to ensure this doesn't have any unsavory impact on some totally different workload.
For example, changing the ACK strategy might help with throughput for a big file download, but it might increase latency for some other application which sends small unary requests to a server occasionally.
RFC2581 actually says that it is strongly encouraged to have an "ACK every other segment" strategy. From section 4.2:
The requirement that an ACK "SHOULD" be generated for at least every second full-sized segment is listed in [Bra89] in one place as a SHOULD and another as a MUST. Here we unambiguously state it is a SHOULD. We also emphasize that this is a SHOULD, meaning that an implementor should indeed only deviate from this requirement after careful consideration of the implications. See the discussion of "Stretch ACK violation" in [PAD+98] and the references therein for a discussion of the possible performance problems with generating ACKs less frequently than every second full-sized segment.
So it isn't necessarily a problem if we change the ACK strategy in a way that improves performance. It just requires a little more care than I have put into this up to this point.
I don't yet understand the ACK strategy used by Linux or FreeBSD. That would be worth looking into to see if they diverge from the RFC.
comment:17 by , 20 months ago
See the "Stretch ack violation" section here https://www.rfc-editor.org/rfc/rfc2525#page-40
We can maybe be more flexible with the ACK strategy using some heuristic, OR this is just a sign that the code path to send back an ACK has a performance problem in itself if other systems implement the "ACK every other full size segment" strategy.
comment:18 by , 20 months ago
I have been looking through this a little more today. I have a couple of new observations.
TCPEndpoint::_Receive returns an action bitfield. If the action includes the IMMEDIATE_ACKNOWLEDGE action then an ACK will immediately be sent. This function returns IMMEDIATE_ACKNOWLEDGE if the sender included the PSH header in a segment. I haven't found any guidance in the RFCs that ack should immediately be sent when PSH is used, so that seems like a bug to me. Just changing that branch to only return KEEP instead of KEEP & IMMEDIATE_ACKNOWLEDGE doesn't quite work though, I think there is a path missing somewhere that would trigger a delayed ack. But I think that's a good lead.
Another observation is that DelayedAcknowledge is currently sending an ACK for every other segment received. But the guidance in the RFCs is to send an ACK for every other full sized segment. I interpret this as having received segments totaling 2*MSS bytes.
So I think a pretty straight forward optimization should be to have TCPEndpoint track the number of bytes received since the last ACK it has sent, and ACK either when 2*MSS bytes are received or after 100ms, whichever comes first. That I think is closer to the guidance than what is done in the code today.
The final observation is that TCPEndpoint::_SendQueued seems very suboptimal. It is called either to take a chunk of data in the send queue and turns it into N TCP segments, or it is called with force=true when an ACK is being sent.
In the case where an ACK is being sent but there is nothing in the send queue, then a 256 byte buffer is allocated for the ACK. That is probably a little wasteful. I'm not sure yet if this code path is slow because allocating that 256 bytes is slow. It's possible that allocating a smaller buffer for a segment that is just the size of segment overhead would be a lot faster but I'm not sure yet.
In the case where there is data in the send queue, this code is breaking that data up into segments of the size 256 bytes regardless of what the max segment size (MSS) is set to. Elsewhere the MSS seems to be calculated appropriately, which is something like MTU - 20, where 20 is the TCP header overhead.
Sending segments of the size MSS when possible and more closely aligning the allocation with the size of the segment itself would probably yield better results. But I think the throughput would be even better if a large allocation was made that packed multiple segments up to size MSS inside of it would be better. That seems to be a bit incompatible with the design of the network stack unfortunately I'm not sure how difficult that would be at the moment.
follow-up: 23 comment:19 by , 20 months ago
Without looking at the code: net_buffers internally are minimum 2048 bytes, I think, so if that's a 256-sized net_buffer allocation it probably doesn't matter. If it's a regular heap allocation then that makes a difference.
Breaking data up into chunks of size 256 sounds slow, though.
follow-ups: 21 22 comment:20 by , 19 months ago
This function returns IMMEDIATE_ACKNOWLEDGE if the sender included the PSH header in a segment.
To me this looks correct, no other packet will be received, so why care to wait for sending an ACK?
comment:21 by , 19 months ago
Replying to korli:
To me this looks correct, no other packet will be received, so why care to wait for sending an ACK?
Seems like rfc1122 says there is a 200ms delay ack in this case... so not an immediate acknowledge.
comment:22 by , 19 months ago
Replying to korli:
This function returns IMMEDIATE_ACKNOWLEDGE if the sender included the PSH header in a segment.
To me this looks correct, no other packet will be received, so why care to wait for sending an ACK?
For a socket that is being used for a single HTTP request or something then yeah it doesn't matter. But if you have, say, a bidirectional streaming protocol implemented with a TCP socket and you are streaming lots of messages onto a socket with PSH at the message boundary then you could be ACKing a way more often than you need to which could hurt throughput. Especially if those messages are much smaller than the MSS.
comment:23 by , 19 months ago
Replying to waddlesplash:
Without looking at the code: net_buffers internally are minimum 2048 bytes, I think, so if that's a 256-sized net_buffer allocation it probably doesn't matter. If it's a regular heap allocation then that makes a difference.
Breaking data up into chunks of size 256 sounds slow, though.
Thanks, that's good to know. I definitely don't understand the net_buffer code yet.
follow-up: 26 comment:24 by , 11 months ago
It looks like the DelayedAcknowledge code used to wait to send ACKs much like ambroff's above change suggests, but this was removed very early on: hrev21255.
korli, are you the "Jerome" mentioned in that commit message? Any idea what happened here?
comment:25 by , 11 months ago
https://wiki.geant.org/display/public/EK/TCP+Acknowledgements
RFC 5681 mandates that an acknowledgement be sent for at least every other full-size segment, and that no more than 500ms expire before any segment is acknowledged. The resulting behavior is that, for longer transfers, acknowledgements are only sent for every two segments received ("ack every other").
comment:26 by , 11 months ago
Replying to waddlesplash:
korli, are you the "Jerome" mentioned in that commit message? Any idea what happened here?
Back then I sent a serial log with tcp trace enabled, not more.
comment:27 by , 11 months ago
As of hrev57490 I've revived the tcp_shell (which allows testing the TCP implementation in userland -- it doesn't have a raw sockets mode yet for interaction with the real world, but that could probably be added), and added a .pcap output mode to it for easy inspection in Wireshark and other tools. Now it's possible to use a real debugger on the TCP implementation again...
comment:28 by , 11 months ago
| Milestone: | Unscheduled → R1/beta5 |
|---|---|
| Resolution: | → fixed |
| Status: | new → closed |
Should be fixed by hrev57492 (one patch in that series inspired by ambroff's comments and changes above). Further problems should probably go in new tickets.
Do you get the same sort of results when using the wired connection?