

Opened 2 years ago
Closed 2 years ago
#18334 closed bug (fixed)
Hangs, KDLs with callout processing in the FreeBSD compatibility layer
| Reported by: | waddlesplash | Owned by: | nobody |
|---|---|---|---|
| Priority: | normal | Milestone: | Unscheduled |
| Component: | Drivers/Network | Version: | R1/beta4 |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | #18338 | |
| Platform: | All |
Description
Yesterday, in hrev56875, I reworked the callout processing to handle another edge-case in an attempt to fix #18315.
Today, I got reports from two users (bbjimmy and zdykstra) that after updating to the latest nightly, the fbsd callout thread would occasionally spike to 100% CPU usage and stay there until a reboot, while using the ipro1000 driver. After some attempts, I managed to reproduce this myself on bare metal; I have yet to reproduce it in a VM. It is very intermittent; sometimes I get it within minutes, and sometimes it takes much longer to occur. I have not yet found any way of more reliably triggering it, having only had it about 4-5 times in multiple hours of attempts.
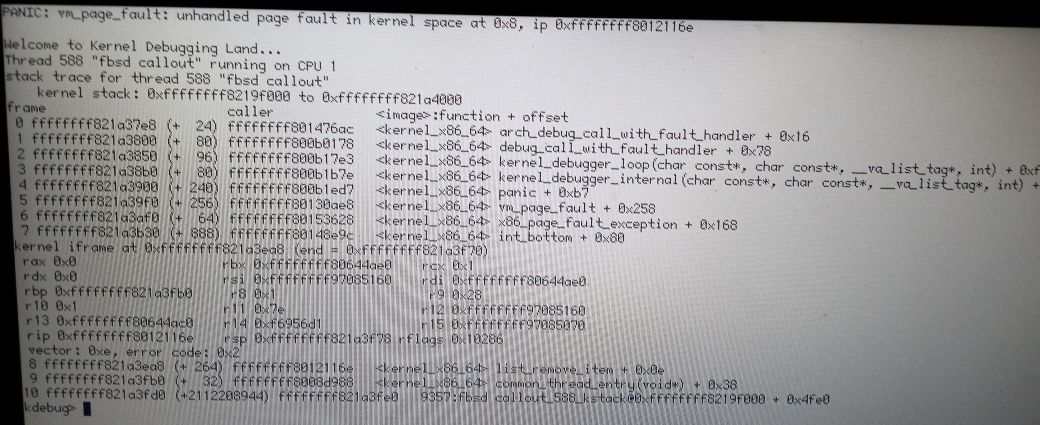
After staring at the code today for multiple hours, I deduced one possible way things could end up in an infinite loop: if the linked-list became corrupted. Thus, in hrev56881, I added code under KDEBUG that should have turned such corruptions into NULL-dereference KDLs. This, it appears, was successful; after this change I started getting such KDLs (a photo is attached.)
However, my repeated inspection of the code has produced no way that I can see of the problem the KDL shows occurring. Items are only removed from the linked list after checking c_due, and all this only happens while the lock is held. I tried sprinkling ASSERT_LOCKED_MUTEX around parts of the code that modify the linked list; none have so far asserted.
I also got, while trying to reproduce this problem, an "invalid concurrent access to page" KDL in the page scrubber which looks a lot like #16552 (or the other ones Diver linked in the comments there), only with most of the page fields zeroed out.
I have made various edits to the callout code in an attempt to shore things up or shake things loose (hrev56882, hrev56884, etc.), but it does not seem that any have had concrete effect.
Attachments (3)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (20)
by , 2 years ago
| Attachment: | KDL-list_remove_item.png added |
|---|
comment:1 by , 2 years ago
comment:2 by , 2 years ago
I should also note that there are a number of cases where I could potentially see a way for a double-removal to have occurred outside the callout thread, but none within it. The removal happens just after having fetched the item from the list, and no lock is released inbetween. How is that possible?
comment:3 by , 2 years ago
hrev56878, profiling a system with the bug triggered:
profiling results for thread "fbsd callout" (1231):
tick interval: 1000 us
total ticks: 12084 (12084000 us)
unknown ticks: 0 (0 us, 0.00%)
dropped ticks: 0 (0 us, 0.00%)
samples/tick: 3.0
hits unknown image
------------------------------------------------------------------------------
12084 0 1 kernel_x86_64
1763 510 7392 /boot/system/add-ons/kernel/drivers/dev/net/ipro1000
hits in us in % image function
------------------------------------------------------------------------------
12084 12084000 100.00 1 common_thread_entry(void*)
10087 10087000 83.47 1 __system_time_rdtscp()
743 743000 6.15 7392 callout_thread(void*)
509 509000 4.21 1 list_get_next_item
235 235000 1.94 1 system_time
1 1000 0.01 1 _mutex_unlock
comment:4 by , 2 years ago
Looking at the code more, after realizing that callouts may reschedule themselves, there may be a case or two that isn't quite handled properly before hrev56884; and I guess I did not reproduce this bug specifically, after that point; that was when I saw the "page scrubber" KDL.
However, I still am having trouble finding a way for a double-removal to occur from within the callout thread. It would simply have to be from _callout_stop_safe, I think; either that, or an item which has NULL next/prev to appear removed but there are other items in the list that still point to it. I can't figure out how either case could happen.
comment:5 by , 2 years ago
Same things on I225-V. KDL with list_remove_item after about hour of idle.
comment:7 by , 2 years ago
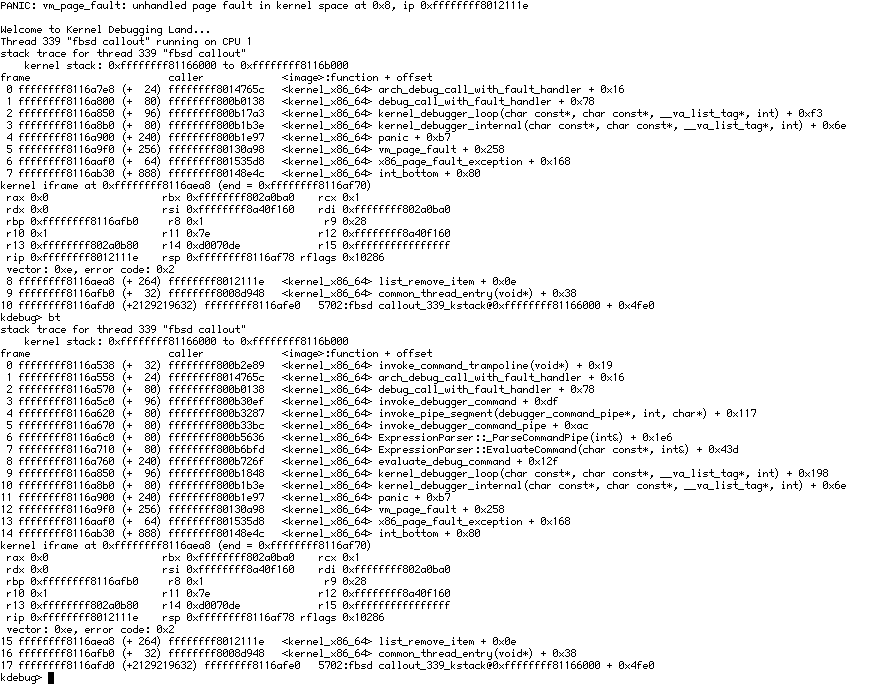
by , 2 years ago
| Attachment: | fbsd_callout_hrev56884_VM.png added |
|---|
comment:10 by , 2 years ago
VM is Qemu + KVM running on Mageia, card is defined as e1000 in VM / ipro1000 in Haiku
comment:11 by , 2 years ago
Indeed I managed to reproduce it in QEMU. That should make testing easier.
Interestingly, I had ProcessController open before the KDL; it appears the "fbsd callout" thread was using a lot of CPU just before the crash. So that may be an important clue.
comment:12 by , 2 years ago
Now I just watched it happen. CPU usage spiked for somewhere around 0.5-1.5 seconds before the crash.
Meanwhile, the if_config_tqg_0 thread has this stack trace:
<kernel_x86_64> reschedule(int) + 0x424 <kernel_x86_64> thread_block + 0xc6 <kernel_x86_64> _mutex_lock + 0x21a </boot/system/add-ons/kernel/drivers/dev/net/ipro1000> _callout_stop_safe.part.0 + 0x22 </boot/system/add-ons/kernel/drivers/dev/net/ipro1000> callout_reset + 0x30 </boot/system/add-ons/kernel/drivers/dev/net/ipro1000> _task_fn_admin + 0x1fb </boot/system/add-ons/kernel/drivers/dev/net/ipro1000> gtaskqueue_run_locked + 0xde </boot/system/add-ons/kernel/drivers/dev/net/ipro1000> gtaskqueue_thread_loop + 0x83 <kernel_x86_64> common_thread_entry(void*) + 0x38
comment:13 by , 2 years ago
I added a snooze at the top of callout_stop_safe. New panic, in the gtaskqueue thread: the mtx_assert failed inside _callout_stop_safe (same backtrace as above otherwise.) Meanwhile, the callout thread had just been woken up and had not yet returned from _mutex_unlock.
Continuing from this KDL did not have the bug manifest; the system continued normally after that.
comment:14 by , 2 years ago
I think I finally have a reliable way to trigger the problem. Adding the following block to _callout_stop_safe before the MutexLocker creation triggers the KDL very reliably shortly after boot:
if (c->c_due > 0) while (!callout_active(c)) atomic_get64((int64*)&sCurrentCallout);
comment:15 by , 2 years ago
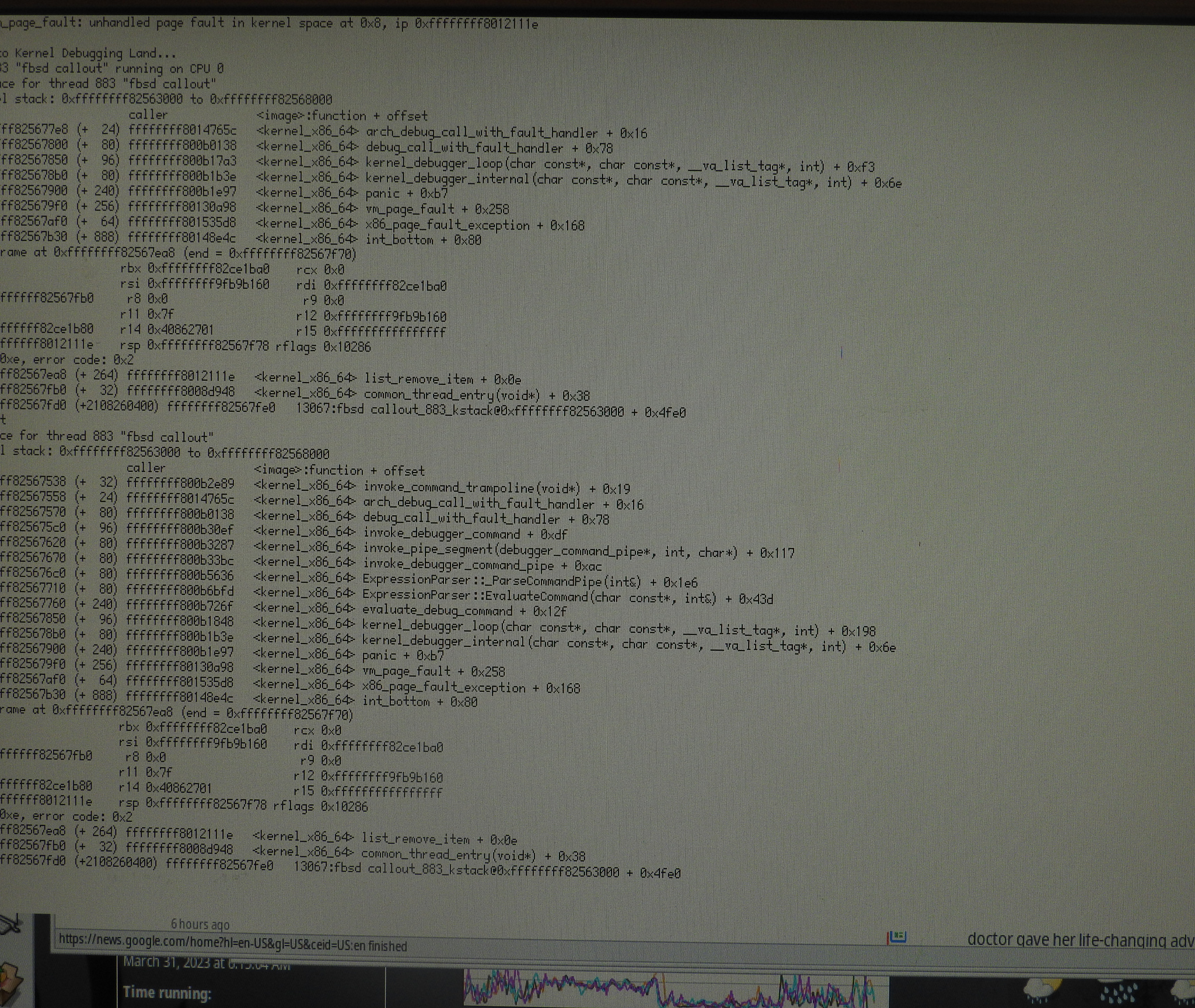
I added debug prints and noticed the looping before the crash is also still due to the linked list. Added more assertions, and:
PANIC: ASSERT FAILED (../src/system/kernel/util/list.cpp:74): link->prev != link
Welcome to Kernel Debugging Land...
Thread 326 "fbsd callout" running on CPU 2
stack trace for thread 326 "fbsd callout"
kernel stack: 0xffffffff81a79000 to 0xffffffff81a7e000
frame caller <image>:function + offset
0 ffffffff81a7dd08 (+ 24) ffffffff8014a9cc <kernel_x86_64> arch_debug_call_with_fault_handler + 0x16
1 ffffffff81a7dd20 (+ 80) ffffffff800b1628 <kernel_x86_64> debug_call_with_fault_handler + 0x78
2 ffffffff81a7dd70 (+ 96) ffffffff800b2c93 <kernel_x86_64> kernel_debugger_loop(char const*, char const*, __va_list_tag*, int) + 0xf3
3 ffffffff81a7ddd0 (+ 80) ffffffff800b302e <kernel_x86_64> kernel_debugger_internal(char const*, char const*, __va_list_tag*, int) + 0x6e
4 ffffffff81a7de20 (+ 240) ffffffff800b3387 <kernel_x86_64> panic + 0xb7
5 ffffffff81a7df10 (+ 80) ffffffff81d06832 </boot/system/add-ons/kernel/drivers/dev/net/ipro1000> callout_reset + 0xc2
6 ffffffff81a7df60 (+ 32) ffffffff81d0622e </boot/system/add-ons/kernel/drivers/dev/net/ipro1000> invoke_callout(callout*, mtx*) + 0x3d
7 ffffffff81a7df80 (+ 48) ffffffff81d06350 </boot/system/add-ons/kernel/drivers/dev/net/ipro1000> callout_thread(void*) + 0x67
8 ffffffff81a7dfb0 (+ 32) ffffffff8008e698 <kernel_x86_64> common_thread_entry(void*) + 0x38
This looks like the cause. Now to figure out how this happens...
comment:16 by , 2 years ago
| Blocking: | 18338 added |
|---|
I guess it is also worth noting that my last "cleanup/fixes" commit (hrev56884) does affect behavior in at least some potential race cases (based on my cursory examination), but even if those cases were real, it would lead to non-insertions, not double-removals from the linked-lists, I think.
The "goto" I introduced yesterday may have been a not so bright idea, but, this file already has other "goto"s (not of my design) in it; and anyway if that was misbehaving, I would have expected the
ASSERT_LOCKED_MUTEXto trigger.Tomorrow I intend to try and create artificial scenarios to make the triggering of this problem, whatever it is, more likely. I will also probably refactor out the "goto", just in case. But it will also be interesting to hear from zdykstra and bbjimmy if they notice any different behavior with today's changes, i.e. if they get the exact same KDL now, or if it occurs less frequently, or something else.