

Opened 15 months ago
Last modified 4 weeks ago
#18717 new bug
[regression] Stability issues in block_cache
| Reported by: | axeld | Owned by: | nobody |
|---|---|---|---|
| Priority: | high | Milestone: | R1/beta6 |
| Component: | System/Kernel | Version: | R1/Development |
| Keywords: | Cc: | ||
| Blocked By: | #8437, #19343 | Blocking: | #18646 |
| Platform: | All |
Description
I had hrev56721 and hrev56921 running for a couple of months on my NAS without any issues (it would run for weeks). Since I upgraded to hrev57387, I have stability issues without changing the usage pattern. It now maybe lasts for a week until it crashes, sometimes even more often.
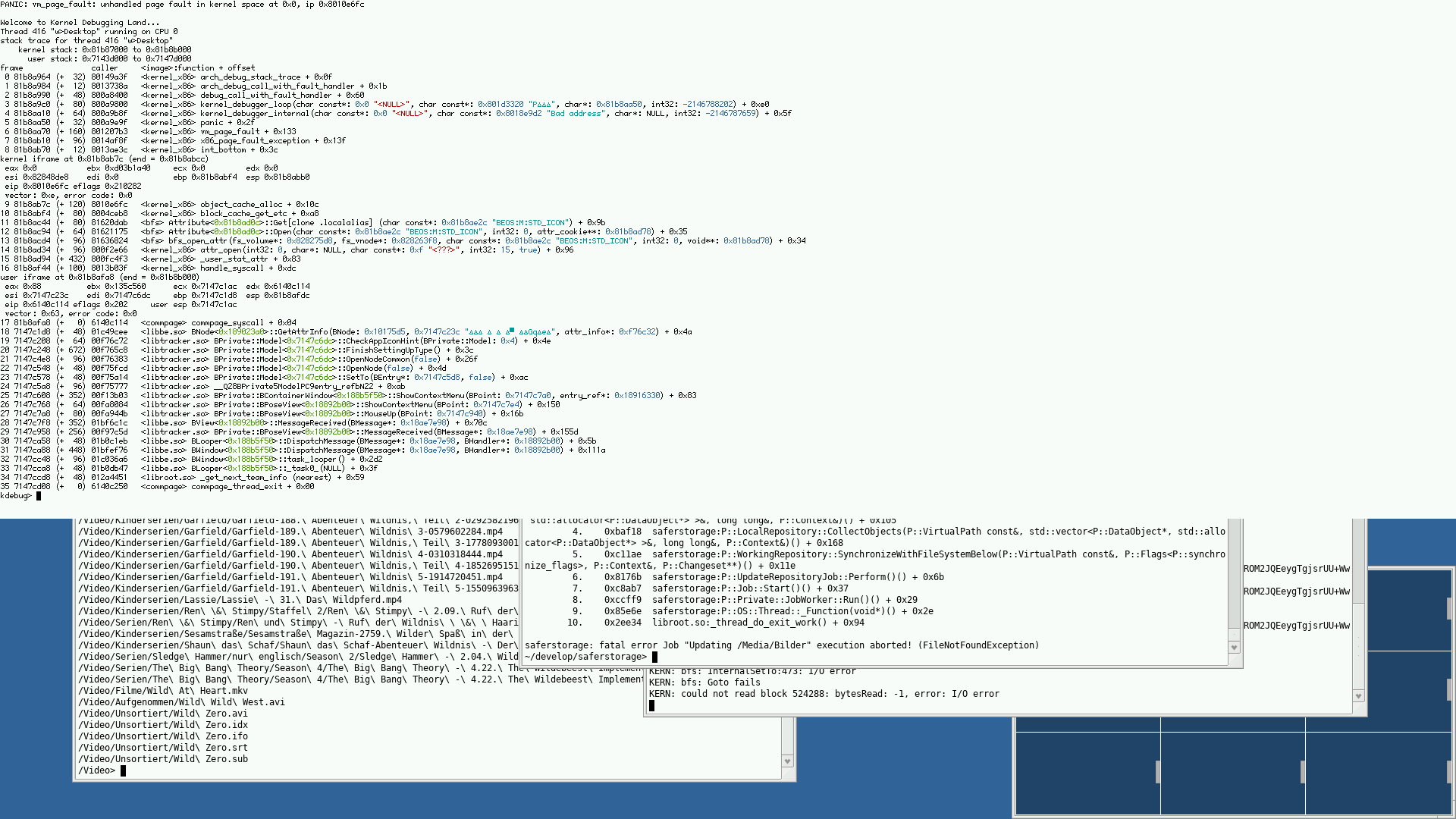
Some KDL screenshots attached.
Attachments (14)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (59)
by , 15 months ago
| Attachment: | HaikuScreenshots-2023-11-18.png added |
|---|
by , 15 months ago
| Attachment: | HaikuScreenshots-2023-11-18-2.png added |
|---|
by , 15 months ago
| Attachment: | HaikuScreenshots-2023-12-09.png added |
|---|
comment:1 by , 15 months ago
| Milestone: | Unscheduled → R1/beta5 |
|---|
comment:2 by , 15 months ago
| Summary: | Stability issues → [regression] Stability issues |
|---|
comment:3 by , 15 months ago
comment:5 by , 15 months ago
Do you have any custom kernel add-ons by any chance? I think there were some "minor" ABI changes in there (to condition variable struct sizes, at least.)
Also in that range:
- clear page queue ordering (hrev57360)
- VM changes to cut_area (hrev57096 and ~1) and unlock caches before unmapping addresses (hrev57062)
- user_mutex refactor (multiple hrevs)
(That's just for the kernel itself, I didn't skim through driver changes. )
But as noted above, I highly suspect this is just some kind of memory corruption. What drivers are loaded after booting?
comment:6 by , 15 months ago
Sorry, I didn't get or see any notification mail. I do actually use the DriveEncryption driver which, if I'm not mistaken, does make use of kernel locking facilities. I'll try to recompile that one with a newer kernel, and see if that changes anything.
comment:7 by , 14 months ago
I have switched to hrev57493, and recompiled the driver a couple of days ago.
Today I first got strange problems like "I/O error" or "File not exists error" while I could open the file just fine, and also Tracker could open the directory that caused the latter error. Then later, the system crashed with the attached output.
comment:8 by , 14 months ago
It might still be caused by that driver, actually. Do you know offhand what kernel config is being used for the nightlies? Does that end up somewhere on the image (the kernel_debug_config.h file)? And how can I find out?
I used KERNEL_DEBUG 2 to compile that driver, so that might not have been compatible.
comment:9 by , 14 months ago
KDEBUG_LEVEL 2 is correct. But are you not using the exact same headers/sources to compile the driver as the nightly you are running on, including the file where KDEBUG_LEVEL is defined?
A thought occurs to me: within that range, the size of the ConditionVariable class changed, and with it the IORequest classes as they contain ConditionVariable members. The "I/O error" and the like might be caused by those malfunctioning, and then the memory corruptions also.
comment:10 by , 14 months ago
I use the headers as they come with the Haiku package. But this does not define the correct KDEBUG_LEVEL; I use my own kernel_header_config.h file for that. I don't use IORequests in that driver yet, it uses standard read/write hooks.
It does make use of condition variables, though. But any issues there should be fixed by a recompile.
comment:11 by , 14 months ago
I made changes a while ago that were supposed to make KDEBUG_LEVEL 2 binaries ABI compatible with KDEBUG_LEVEL 0 kernels, at least as far as locks go (note that the reverse is not true, however.)
Are you sure that your Haiku _devel package is up to date with the main Haiku package? The ABI change to ConditionVariable was hrev57320.
comment:12 by , 14 months ago
I have not used the driver in this session, but today it crashed again, after about two days of uptime. Screenshot attached.
by , 14 months ago
| Attachment: | HaikuScreenshots-2024-01-09.png added |
|---|
comment:13 by , 14 months ago
Do you have any other drivers in "non-packaged" that are being loaded/used? (You can check with 'listimage'.)
comment:14 by , 14 months ago
I have no non-packaged drivers at all, and "encrypted_drive" is the only foreign driver.
comment:15 by , 14 months ago
I'm currently at 12 days uptime with the driver in use, but I have to restart the host today.
comment:16 by , 14 months ago
I removed the driver, and just updated to the current revision. Immediately after the reboot, I got greeted by this KDL.
by , 14 months ago
| Attachment: | HaikuScreenshots-2024-01-19.png added |
|---|
comment:17 by , 12 months ago
| Summary: | [regression] Stability issues → [regression] Stability issues in block_cache |
|---|
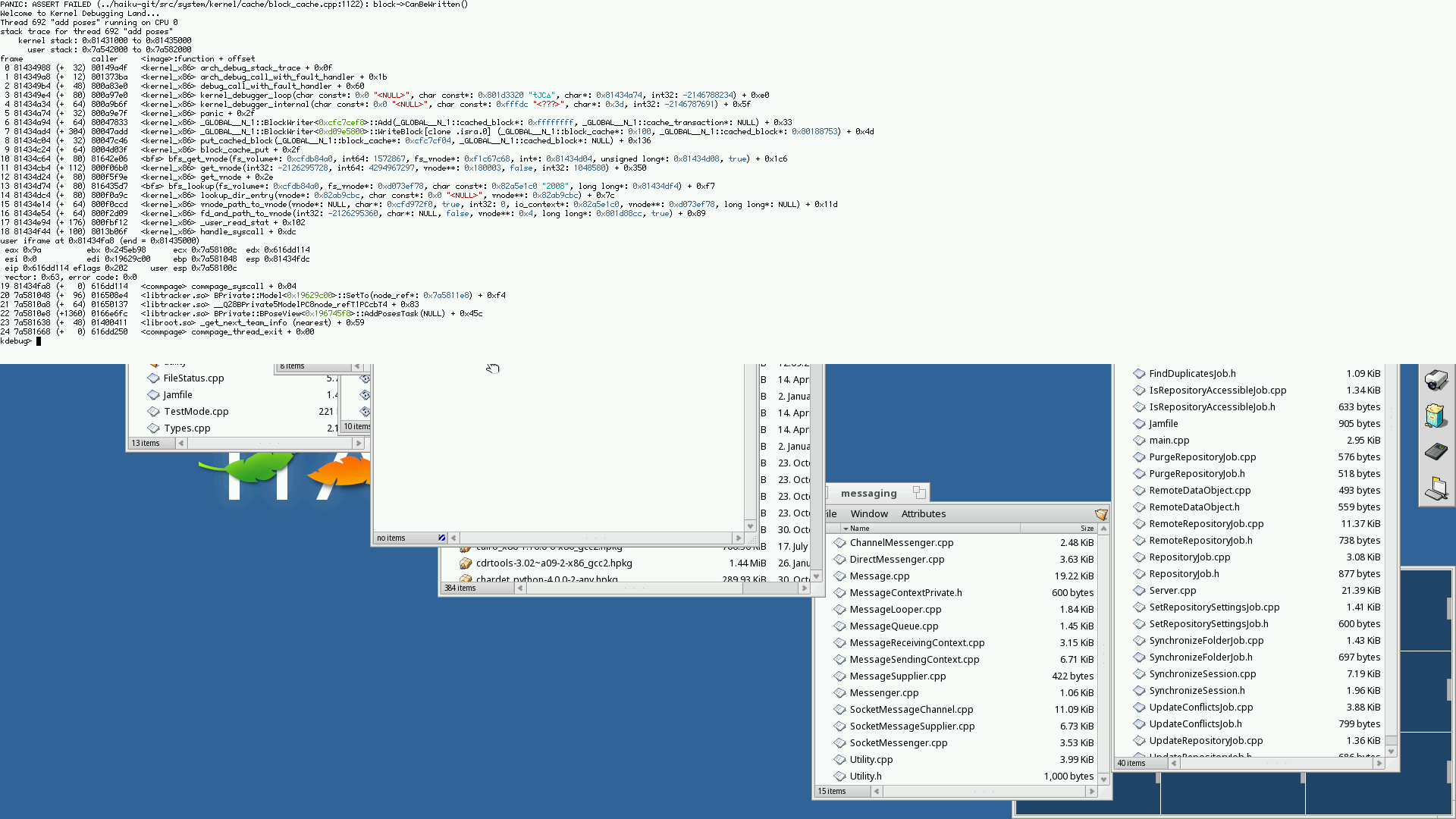
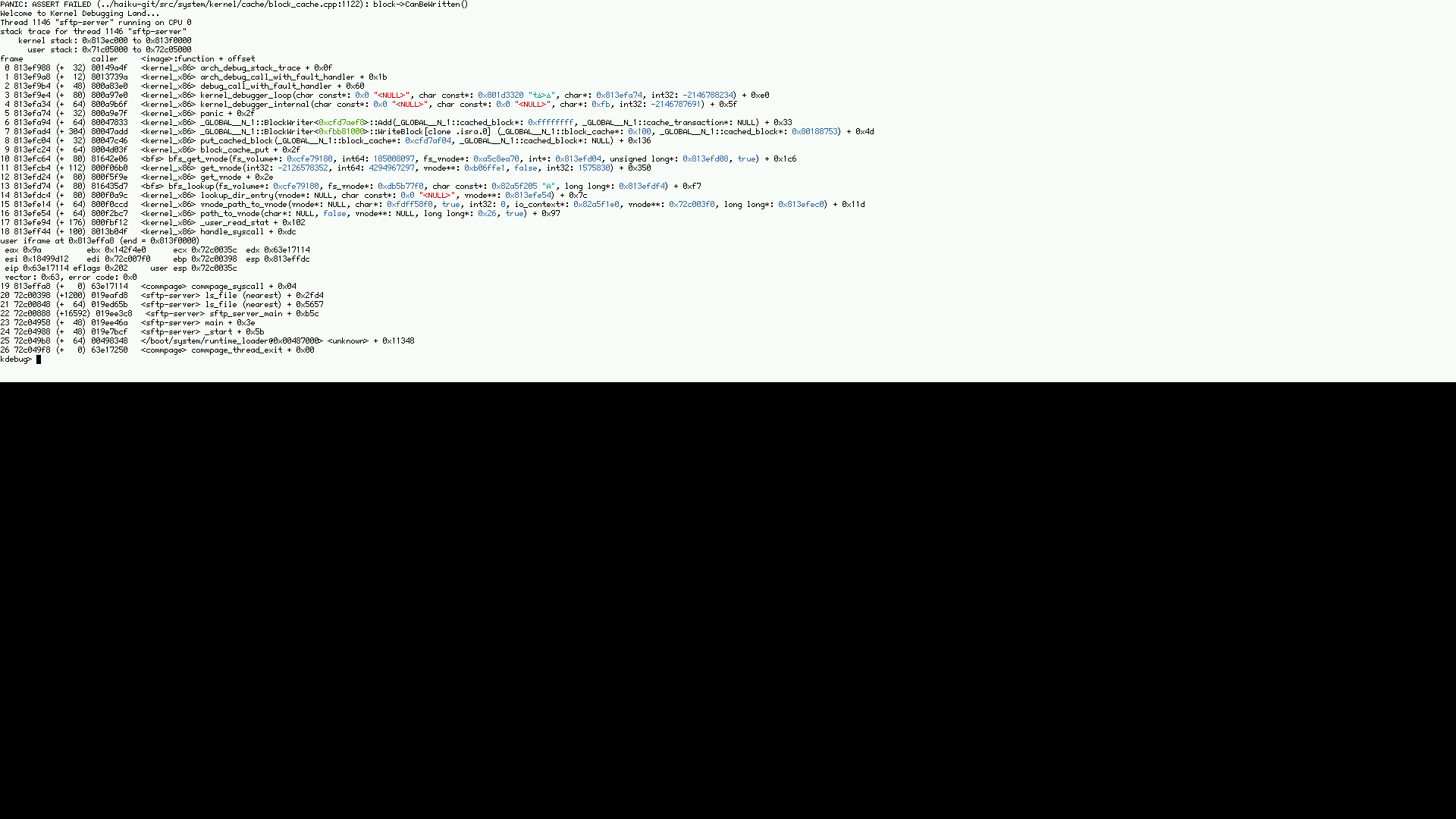
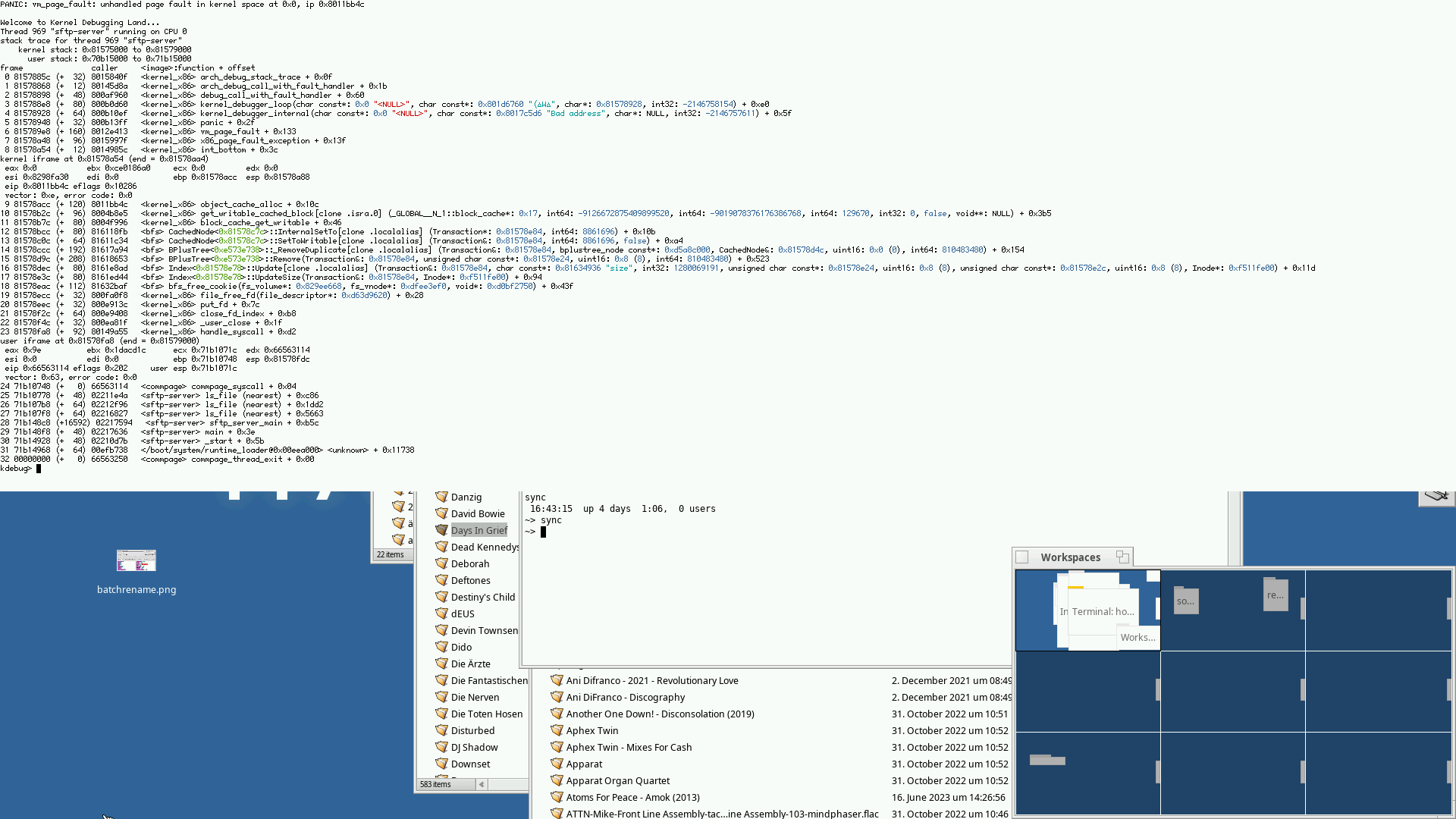
all but one of the attached screenshots are either in block_cache_get -> object_cache_alloc dereferencing a NULL pointer, or block_cache_put failing to write back some blocks.
I'm adjusting the ticket title, although it could either be a bug in the block cache, or possibly in the underlying disk IO.
comment:18 by , 10 months ago
Any changes recently with this? Would it be possible to try with the guarded_heap?
comment:19 by , 9 months ago
Since the system is in use, I didn't play around with it in the last months, and just stayed at R1/Beta4 (currently hrev56578+95). I haven't had any issues with it, but I also did not bother to use the encrypted_drive driver so far (I'm currently using tcplay on the host instead).
I'd be ready to do another test drive, if you want me to :-) However, I don't know how to launch Haiku with the guarded heap compiled in; there currently is no Haiku checkout on the host or guest. I guess there is no distribution with the guarded heap turned on to be fetched via pkgman? Also, how slow is it/how much memory does it need? Sometimes the problems did only manifest after more than a week of usage, and if it's not really usable, I wouldn't want to let it run that long.
comment:20 by , 9 months ago
It's much slower and requires quite a lot more memory, how much depends on the exact workload. Yes, that's correct, there's no builds at present with it compiled in automatically.
But considering all the page faults are NULL pointer dereferences, is there any chance this is just a plain old out-of-memory/out-of-address-space problem?
comment:21 by , 8 months ago
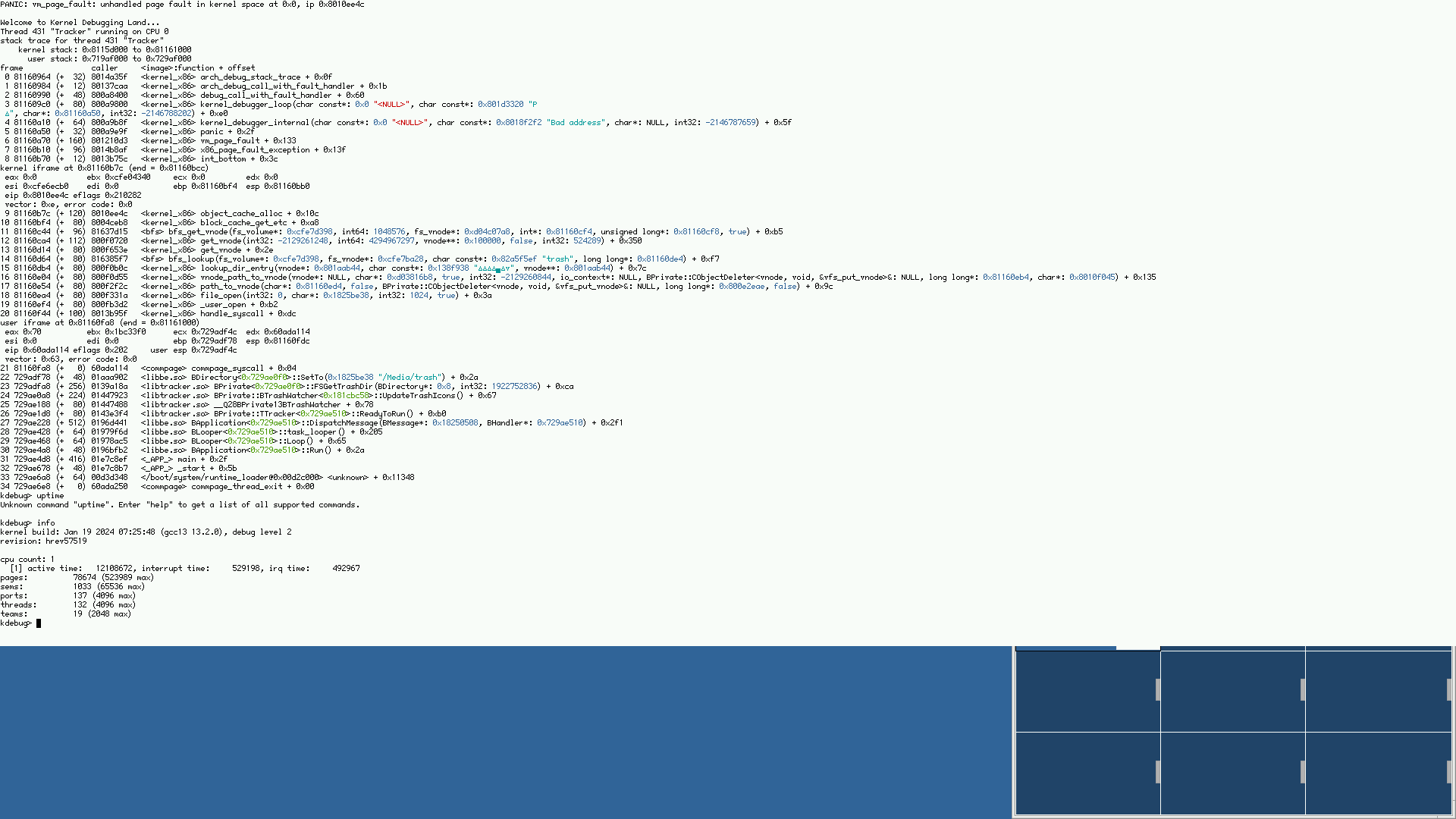
That might be possible; I did not investigate at all yet. The question remains, why this would only happen with the current versions, but not with those from last year. And also, a KDL would be a relatively poor solution for this. Since we're approaching release mode, I'll update my installation to a current nightly again, and see how it goes.
If you look at the last screenshot, it says "pages 78674 (523989 max)" - I don't remember what that means, but it doesn't look like a shortage in either direction, at least :-)
by , 8 months ago
| Attachment: | Screenshot_Haiku_2024-07-28_01ː26ː48.png added |
|---|
comment:22 by , 8 months ago
| Priority: | normal → critical |
|---|
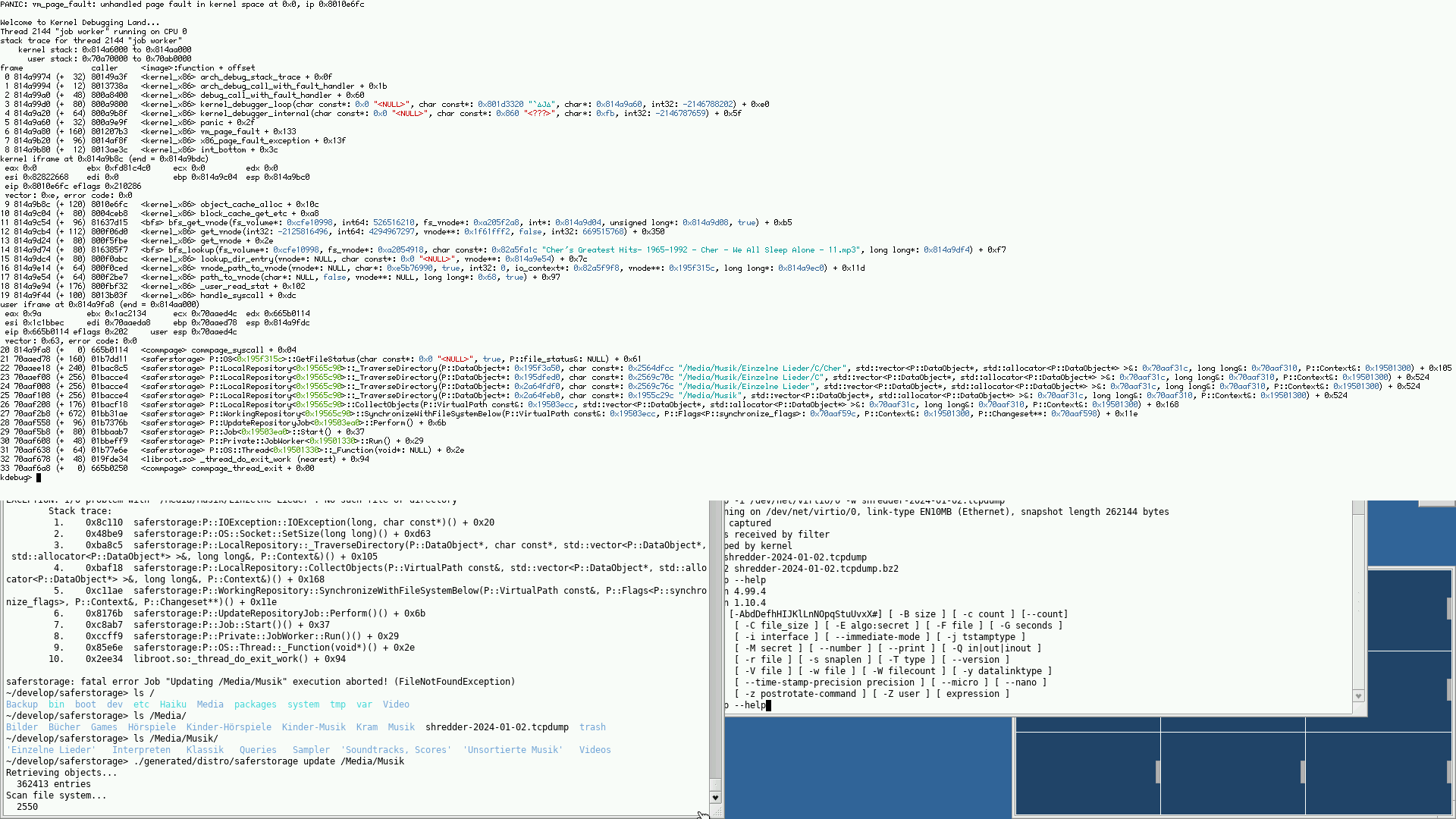
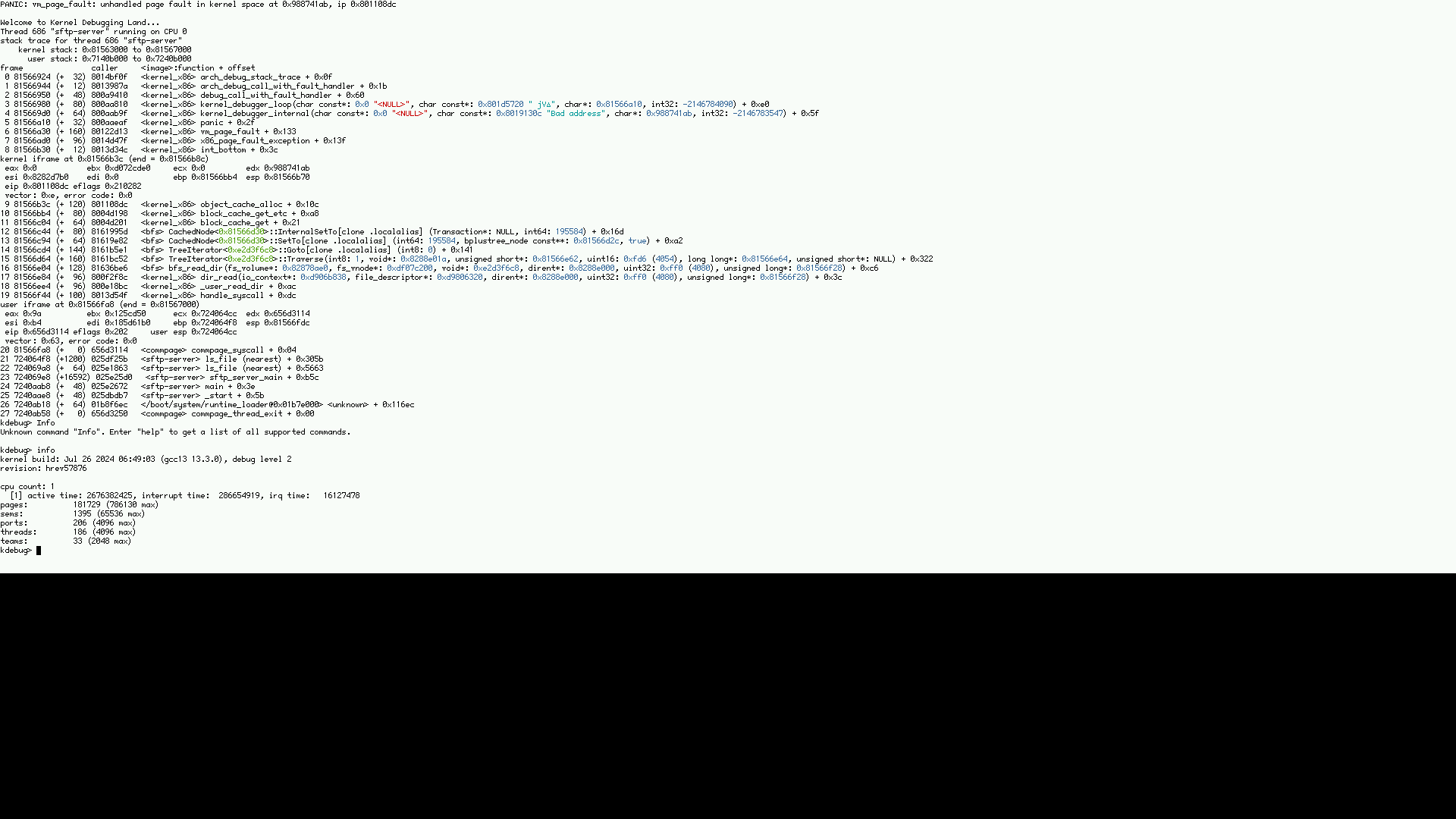
It took less than 24 hours for the next KDL to happen. I have forgotten my KDL-fu, could you give me some guides of what would help to investigate next time this happens?
The only thing that was done on that server was retrieving and pushing files via SFTP. There were no out of tree components involved, AFAICT.
by , 8 months ago
| Attachment: | Screenshot-Haiku-2024-07-29.png added |
|---|
comment:23 by , 8 months ago
Determining what the address represents would be the first step.
I find it strange that nobody else has encountered this problem so far, though. I guess I should try to use SFTP and see if I can manage to trigger it. Any particular usage patterns that cause the problem?
Will you have any time to join IRC in the next few weeks so I could help you investigate? I will also try to reproduce on my end.
comment:24 by , 8 months ago
I tested in VMware with all sorts of sftp usage (mostly, fetching large directories from Linux) for a while and didn't get any problems (though not for 24 hours, admittedly.)
axeld, could you try something other than virtio-net for the NIC, perhaps, and see if that makes any difference here?
comment:25 by , 8 months ago
I built a Haiku with the guarded_heap enabled (though not for the block cache) and got it to boot. sftp-server still didn't cause any KDLs.
Admittedly I am working on 64-bit here not 32-bit, maybe that makes a difference somehow?
comment:26 by , 8 months ago
I guess it may make sense to try with some other disk I/O than virtio, too, if you are using that.
comment:27 by , 8 months ago
I use both, virtio-blk and virtio-net on 32-bit Haiku. I will try to configure it to use something else; however, both should have been in use with a working revision, too IIRC. I could join IRC in the next few weeks, but those will probably odd times for you, and I cannot really predict when I'll actually have time there.
comment:28 by , 8 months ago
I haven't been able to reproduce this on x86_64 either yet. Here's my tests:
(/Data has a LOT of files mixed over a long period of time)
Session 1:
qemu-system-x86_64 --enable-kvm -device virtio-scsi-pci,id=scsi \ -device scsi-hd,drive=hd1 -device scsi-hd,drive=hd2 \ -drive file=haiku-master-hrev57881-x86_64-anyboot.iso,if=none,id=hd1 \ -drive file=/dev/nvme1n1,if=none,id=hd2 -m 4G
find /Data -exec cat {} > /dev/null \;
Session 2:
qemu-system-x86_64 --enable-kvm \ -drive file=haiku-master-hrev57881-x86_64-anyboot.iso,if=virtio \ -drive file=/dev/nvme1n1,if=virtio -m 768M -device usb-tablet -usb
find /Data -exec cat {} > /dev/null \;
comment:29 by , 7 months ago
Just an intermediate update: I have switched to no-virtio for disk, and network. Since then, I did not have a single crash or any other oddities, but only updates to up to a week (before I updated or rebooted the host). I'm now on hrev57977 with an uptime of 6 days -- I'll try to let it run for the next couple of days, to see how it'll go.
comment:30 by , 6 months ago
It appears there was an oversight in hrev56952 (no hrev tag on it for some reason) which led to I/O operations not properly reporting failures in some cases. After the recent refactors to use real vectored I/O in the block cache and BFS journal, this could've lead to filesystem corruptions if the underlying disk rejected the I/O for some reason, which apparently virtio-block sometimes did due to some bugs. mmlr has posted patches to Gerrit fixing those in virtio-block, and I've fixed the I/O request regression in hrev58056. The initial hrevs you mention are before those changes, it appears.
However, we still did not see any crashes like the ones displayed here. Admittedly we are testing with 64-bit and not 32-bit, though, so perhaps there's some difference.
comment:31 by , 6 months ago
I'm now at 17 days without issue without virtio devices. I'll update now, and re-enable some of them. Should I test with virtio-block first, or virtio-net?
BTW I did not have any actual file system corruptions, just crashes or weird file system issues (like empty folders, or missing files). Whenever I encountered those, I rebooted to find the files unharmed.
comment:32 by , 6 months ago
The virtio fixes aren't pushed just yet.
I'd test with virtio-net first until the block changes are merged.
comment:33 by , 6 months ago
The changes were merged in hrev58076, so it'd be interesting to see if they fix this or not.
comment:34 by , 6 months ago
This release obviously wasn't built yet, so I'm still on hrev58057 for now. Will check again, soon. I have already enabled virtio-net now, but that doesn't seem to have caused any regressions for now (but it's only up since 36 hours). Maybe it's a good thing to give that one more time to settle, after all :-)
comment:35 by , 6 months ago
Just to give an update, I'm now running hrev58097 since about 30 hours with enabled virtio-blk and virtio-net.
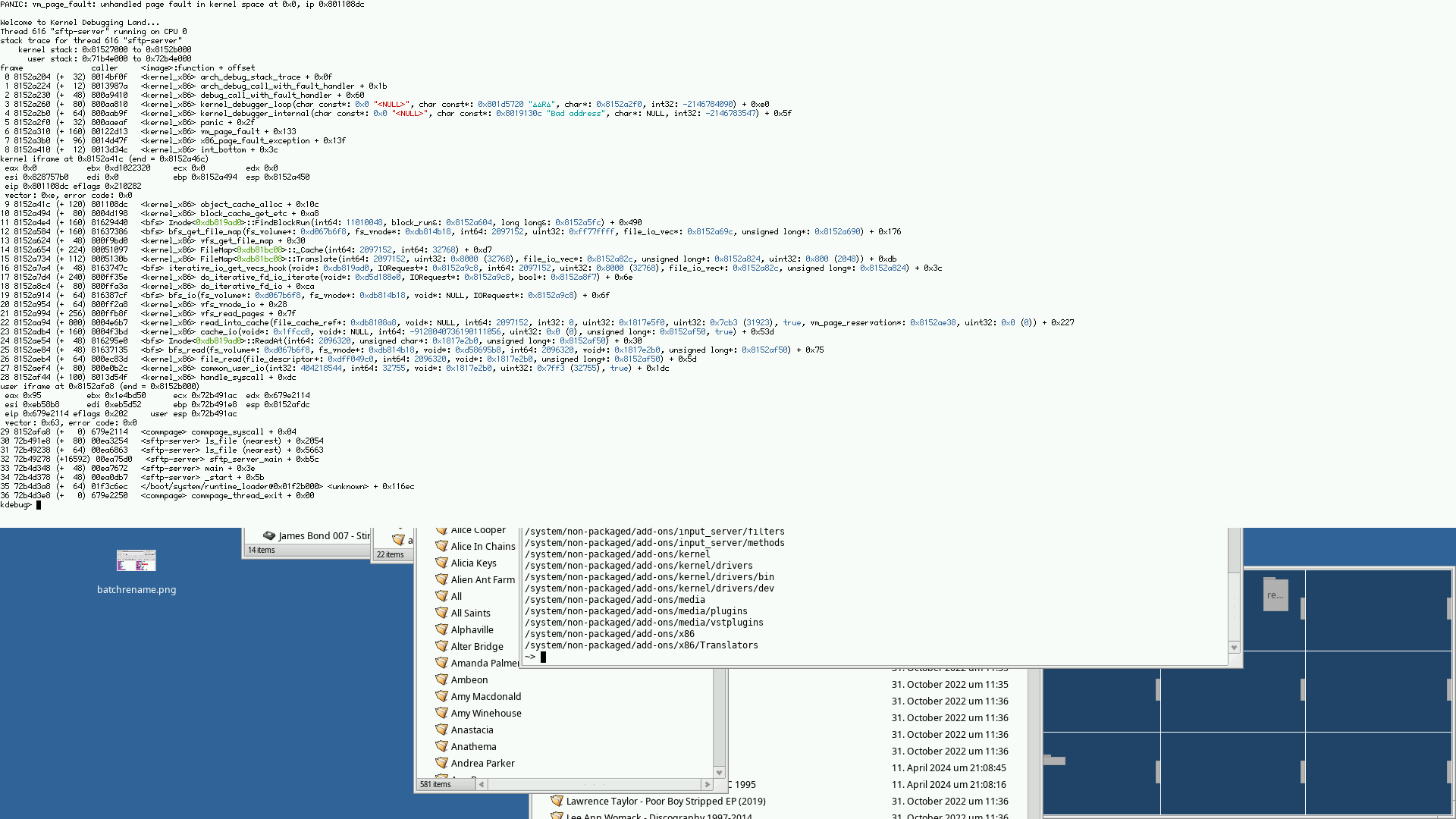
comment:37 by , 6 months ago
It just crashed again while transferring files via SFTP, new screenshots attached. I will now restart it again without virtio-blk again.
comment:38 by , 4 months ago
| Component: | System/Kernel → Drivers/Disk/Virtio |
|---|---|
| Priority: | critical → high |
comment:40 by , 2 months ago
| Blocking: | 19343 added |
|---|
comment:41 by , 2 months ago
| Component: | Drivers/Disk/Virtio → System/Kernel |
|---|
Seems this is kernel/block_cache related after all, as it happened in #19343 under SATA not virtio.
comment:42 by , 2 months ago
Pushed a related change in hrev58506, however I think that will only affect #19343 based on the logs I see in that and in this ticket.
Based on the logs in this ticket, though, it may be possible to trigger artificial OOMs plus random I/O failures and see if that makes this any more likely to reproduce.
comment:43 by , 2 months ago
| Blocked By: | 19343 added |
|---|---|
| Blocking: | 19343 removed |
comment:44 by , 4 weeks ago
| Blocked By: | 8437 added |
|---|
comment:45 by , 4 weeks ago
| Blocking: | 18646 added |
|---|
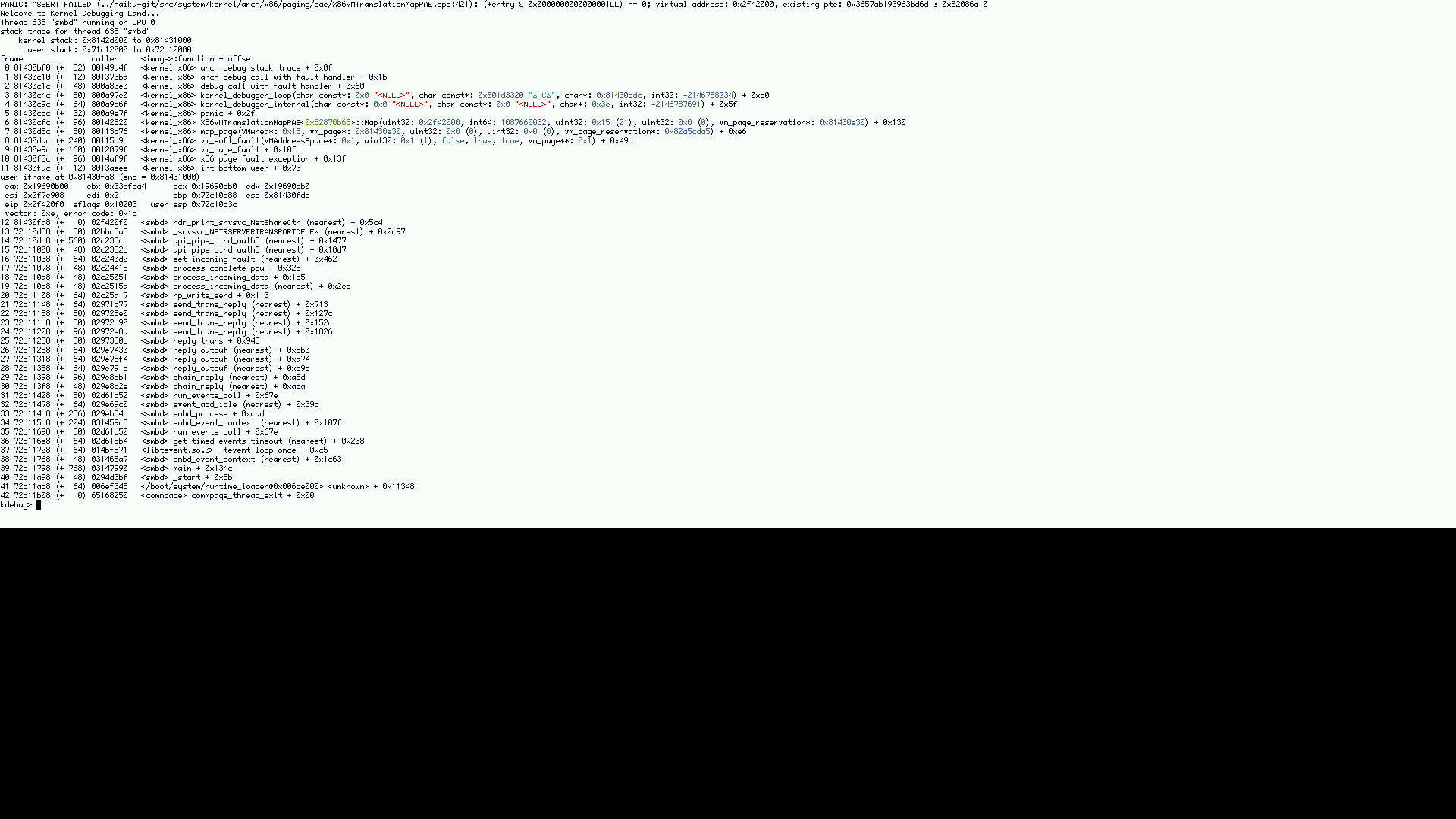
Possibly some kind of memory corruption. The x86VMTranslationMap assert has other tickets but they may always just be due to memory issues.