

Opened 6 months ago
Closed 5 months ago
#18983 closed bug (fixed)
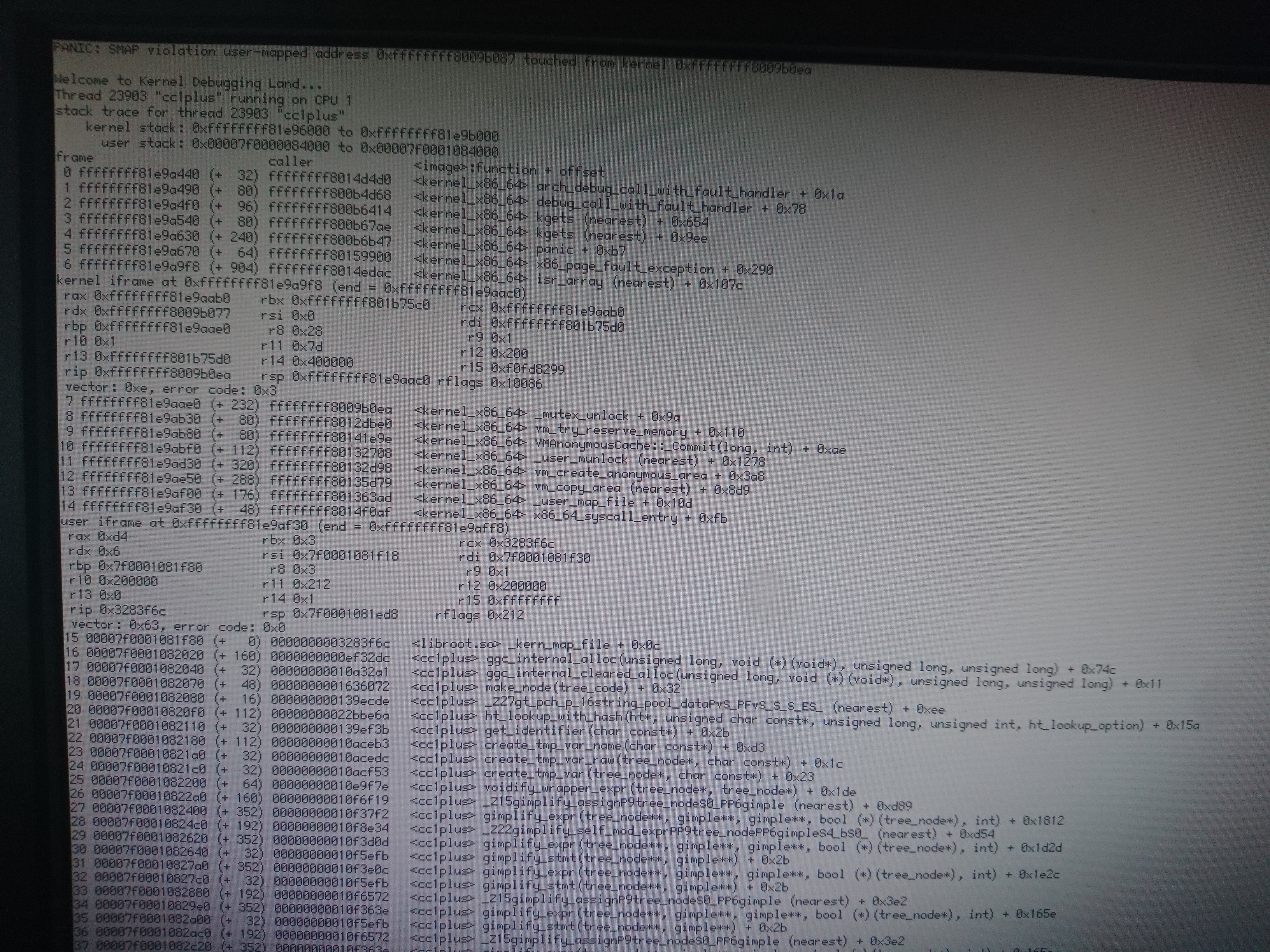
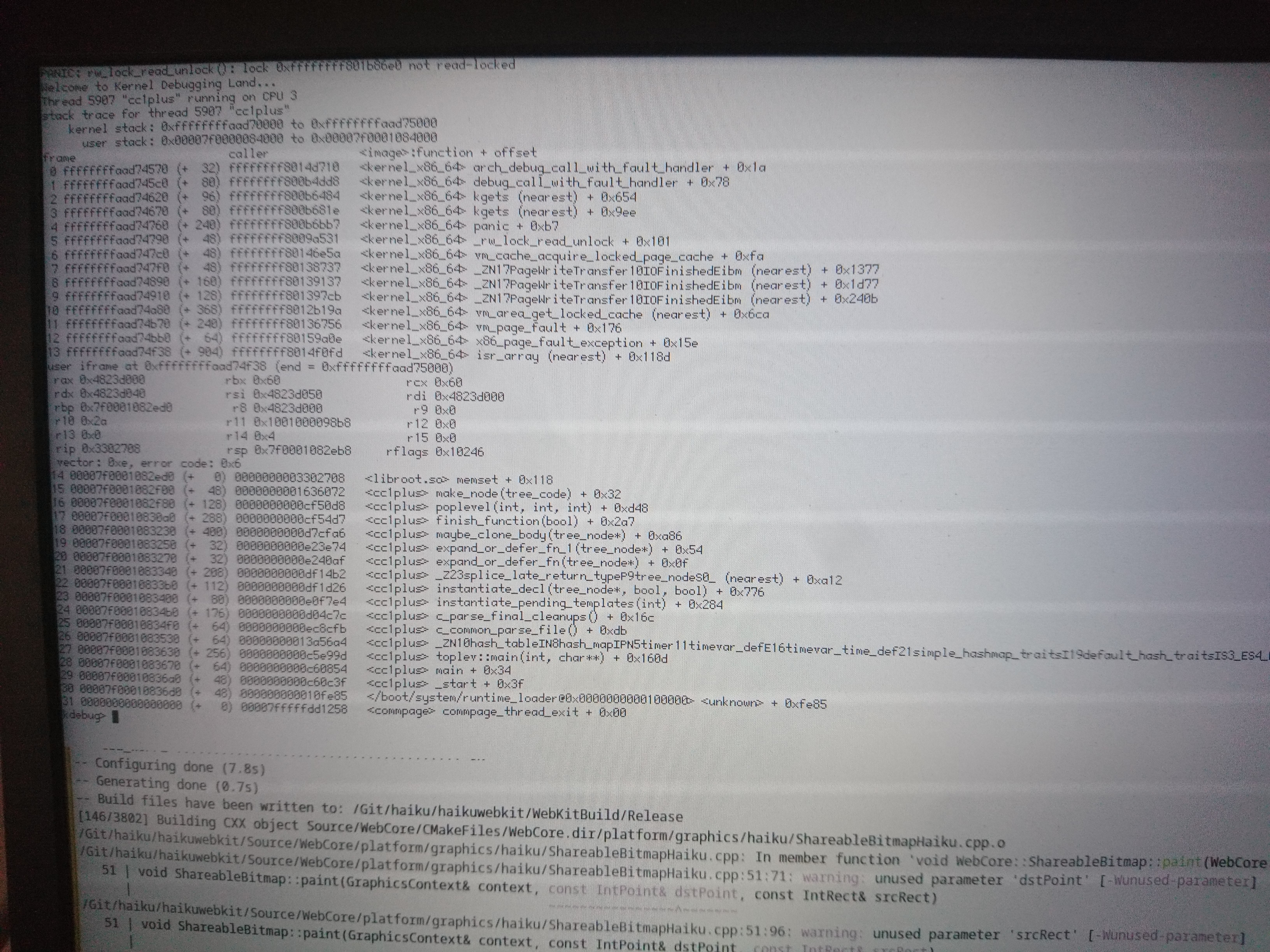
KDLs in vm_try_reserve_memory mutexes when called from _user_map_file
| Reported by: | pulkomandy | Owned by: | nobody |
|---|---|---|---|
| Priority: | normal | Milestone: | R1/beta5 |
| Component: | System/Kernel | Version: | R1/beta5 |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | ||
| Platform: | All |
Description
Happened while compiling webkit.
Attachments (12)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (34)
by , 6 months ago
| Attachment: | DSC_0061.JPG added |
|---|
comment:1 by , 6 months ago
| Component: | - General → System/Kernel |
|---|
by , 6 months ago
| Attachment: | DSC_0062.JPG added |
|---|
comment:2 by , 6 months ago
Today's crash has a different error, and no userspace backtrace.
Currently running hrev57947
by , 5 months ago
| Attachment: | DSC_0101.JPG added |
|---|
by , 5 months ago
| Attachment: | DSC_0102.JPG added |
|---|
comment:3 by , 5 months ago
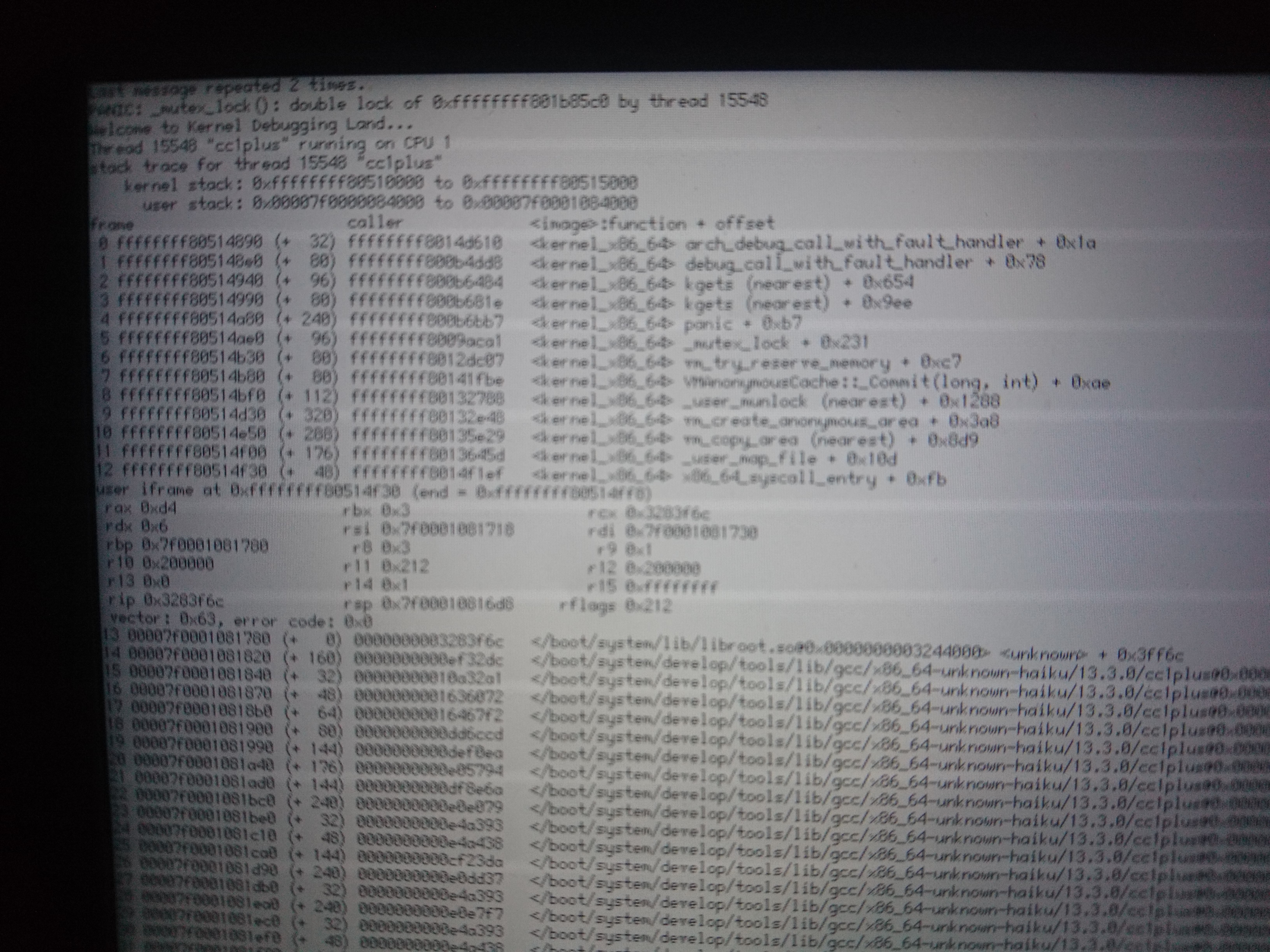
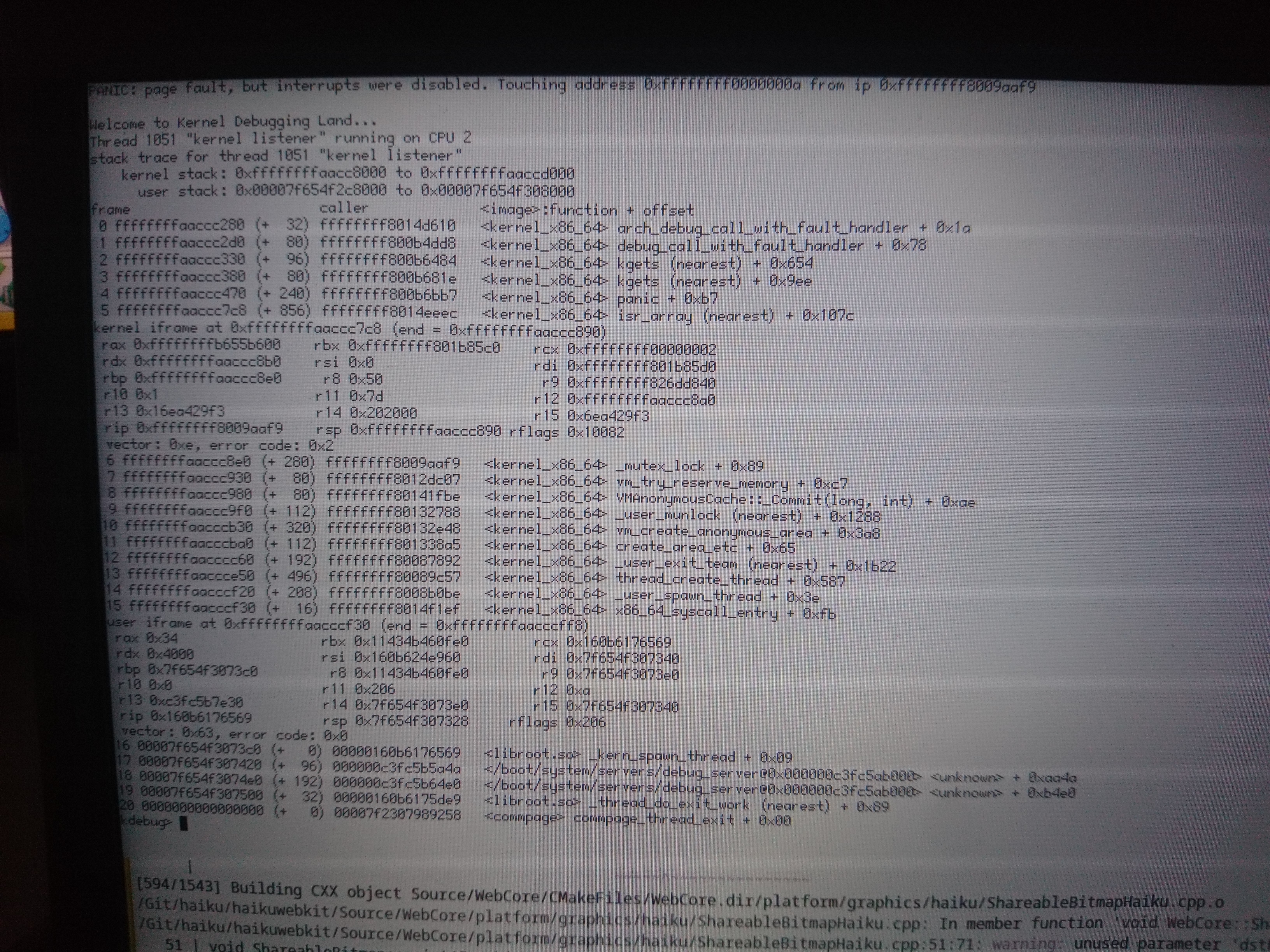
Added today's panics. Not sure if they are related to the previous ones.
comment:4 by , 5 months ago
Not sure, but the panic in 0102 is especially odd because the only lock touched by that function is one with static storage (sAvailableMemoryLock). The panic in 0101 looks like it's the same lock, and this time we got the panic accessing the thread structure, so that hints the panic in 0102 is likely due to the same.
So, somehow an invalid thread pointer got into the mutex. How did that happen? Was the mutex overwritten? Is something else wrong here?
Do you have any drivers in non-packaged? Or any unusual drivers loaded?
comment:5 by , 5 months ago
No drivers in non-packaged, this is hrev58021 from the haiku package repository without any changes or anything unusual as far as I know
by , 5 months ago
| Attachment: | DSC_0103.JPG added |
|---|
by , 5 months ago
| Attachment: | DSC_0104.JPG added |
|---|
by , 5 months ago
| Attachment: | DSC_0105.JPG added |
|---|
by , 5 months ago
| Attachment: | DSC_0106.JPG added |
|---|
comment:7 by , 5 months ago
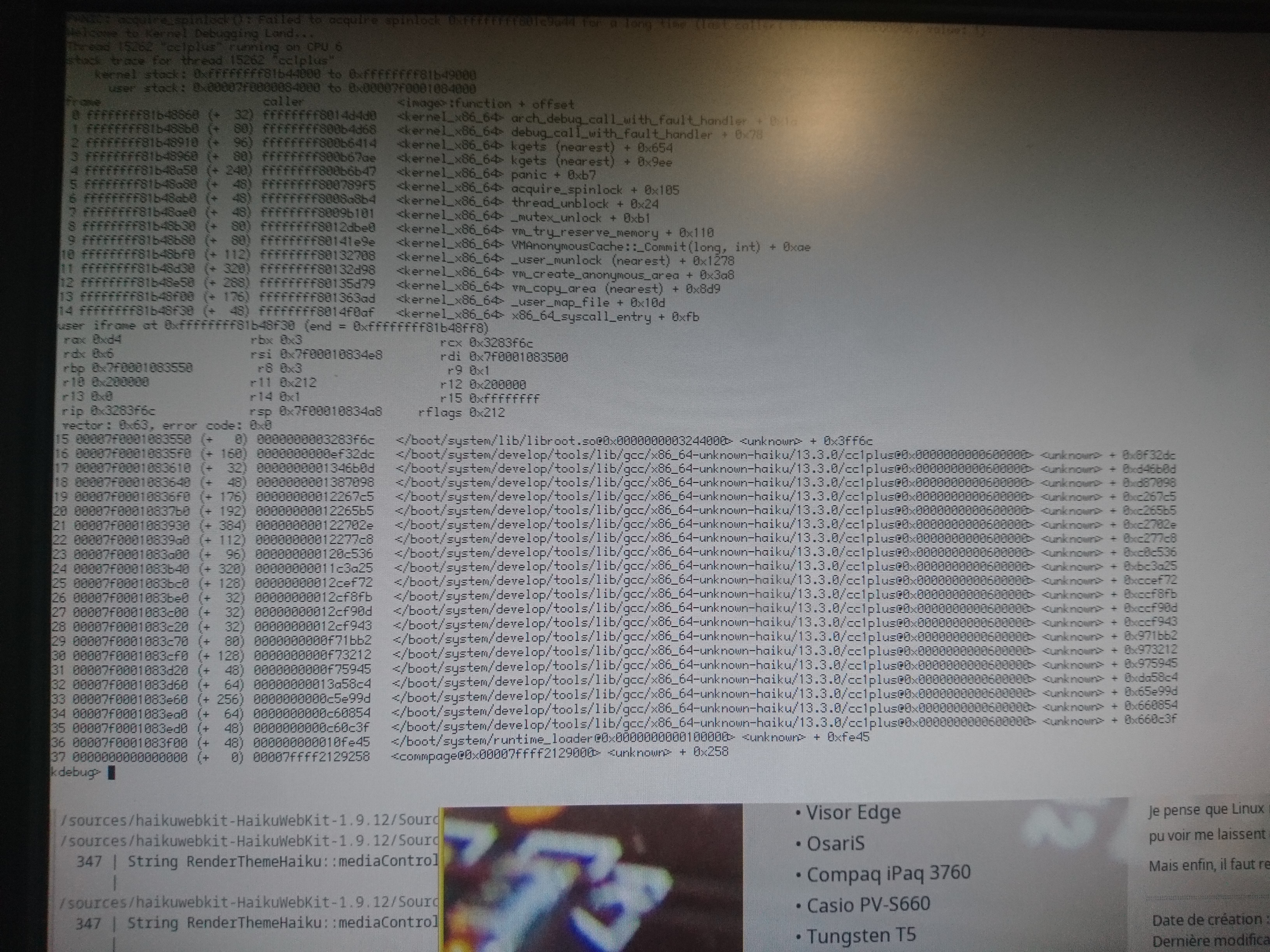
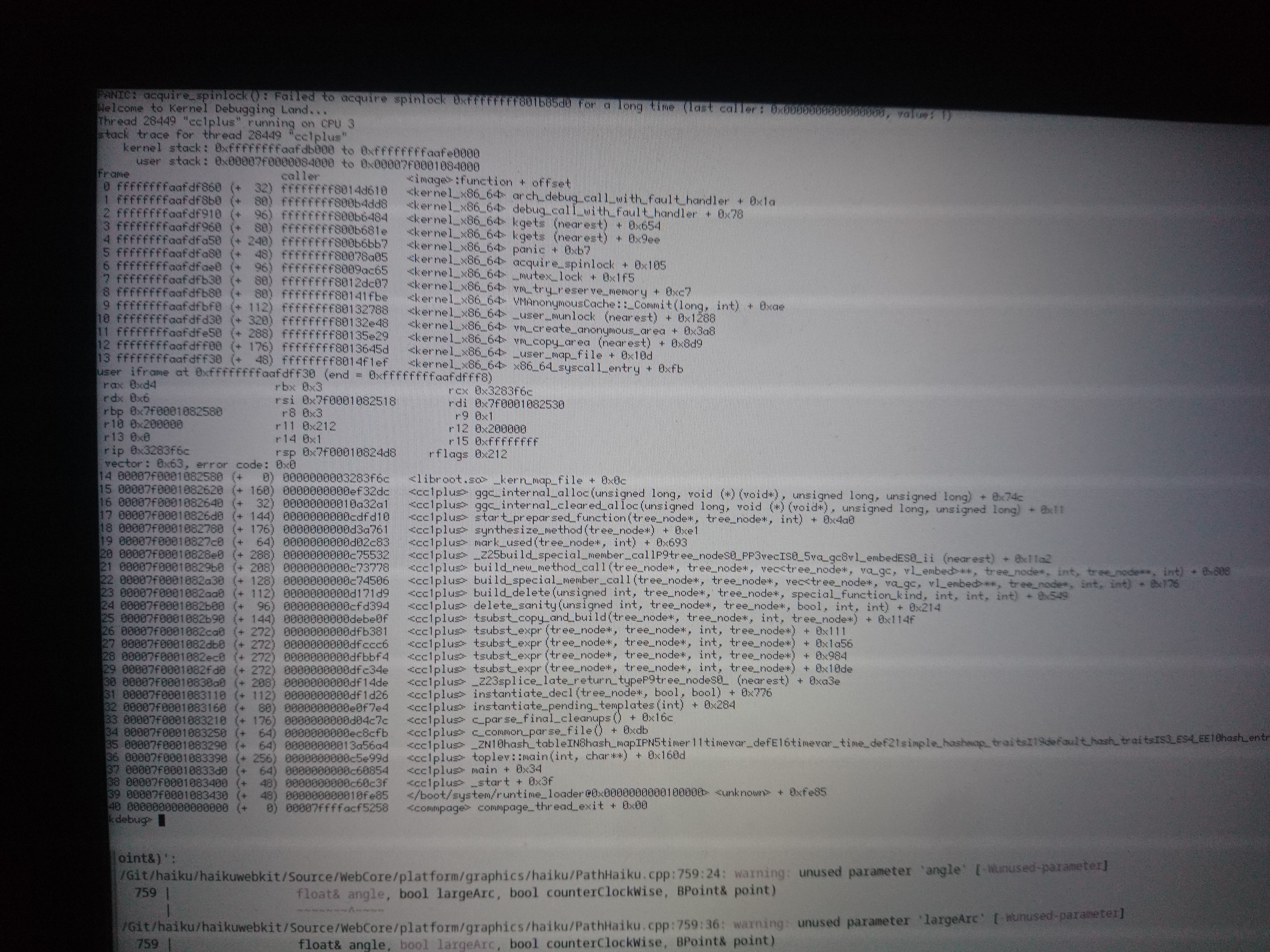
It's all the same lock structure that appears to be getting corrupted. Can you try and see if it's getting corrupted somehow?
Unless GCC is reordering the static data members, I don't see anything immediately suspect...
comment:8 by , 5 months ago
What are machine characteristics (RAM size, swap enabled or not, CPU core count and -j option during building)?
comment:9 by , 5 months ago
16 GB of RAM, Intel Core i7 1165G7 (4 cores + hyperthreading), swap enabled, swapfile is 415MB according to VirtualMemory
Building with ninja -j6 at the moment otherwise the compiler runs out of memory.
comment:10 by , 5 months ago
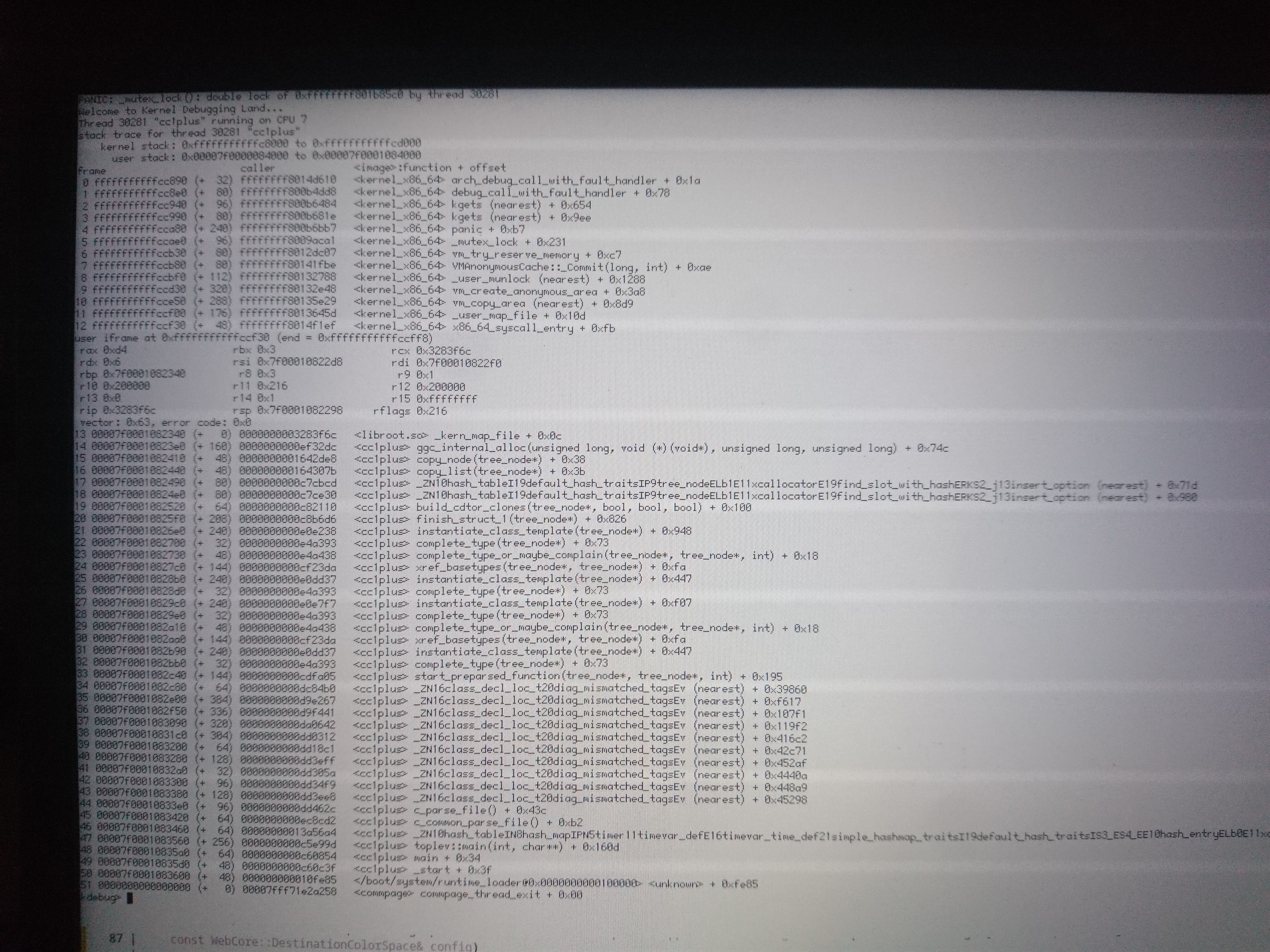
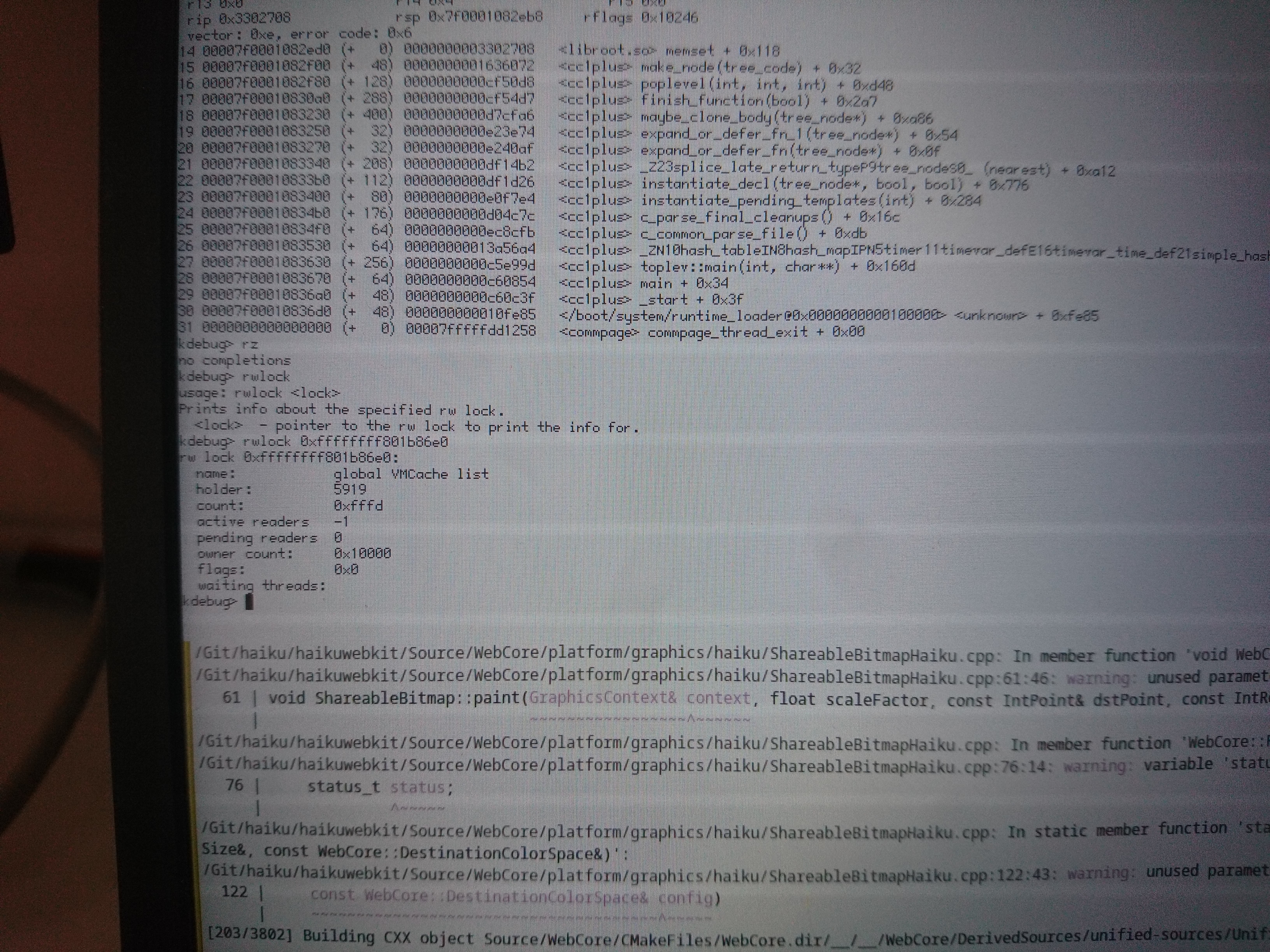
0106 is very interesting, because it's a double-lock panic. That means that, no matter what else has happened, we have a structure with the current thread's ID at the expected offset. If the structure had been overwritten or the pointer to it replaced with garbage data, then we wouldn't expect that to happen, I don't think. So what's going on here?
comment:11 by , 5 months ago
| Summary: | Smap violation in kern_map_file → KDLs in vm_try_reserve_memory mutexes when called from _user_map_file |
|---|
comment:12 by , 5 months ago
otherwise the compiler runs out of memory.
I think this is some important context. vm_try_reserve_memory has a codepath where it loops while calling the low_resource handler. It looks like that's where we're getting to here.
The question then becomes how our MutexLocker (or the mutex itself) got corrupted. The low_resource routine does wait for the low_resource system to complete a run, so we will presumably have waited and then woken up again, since we last locked/unlocked the mutex.
comment:13 by , 5 months ago
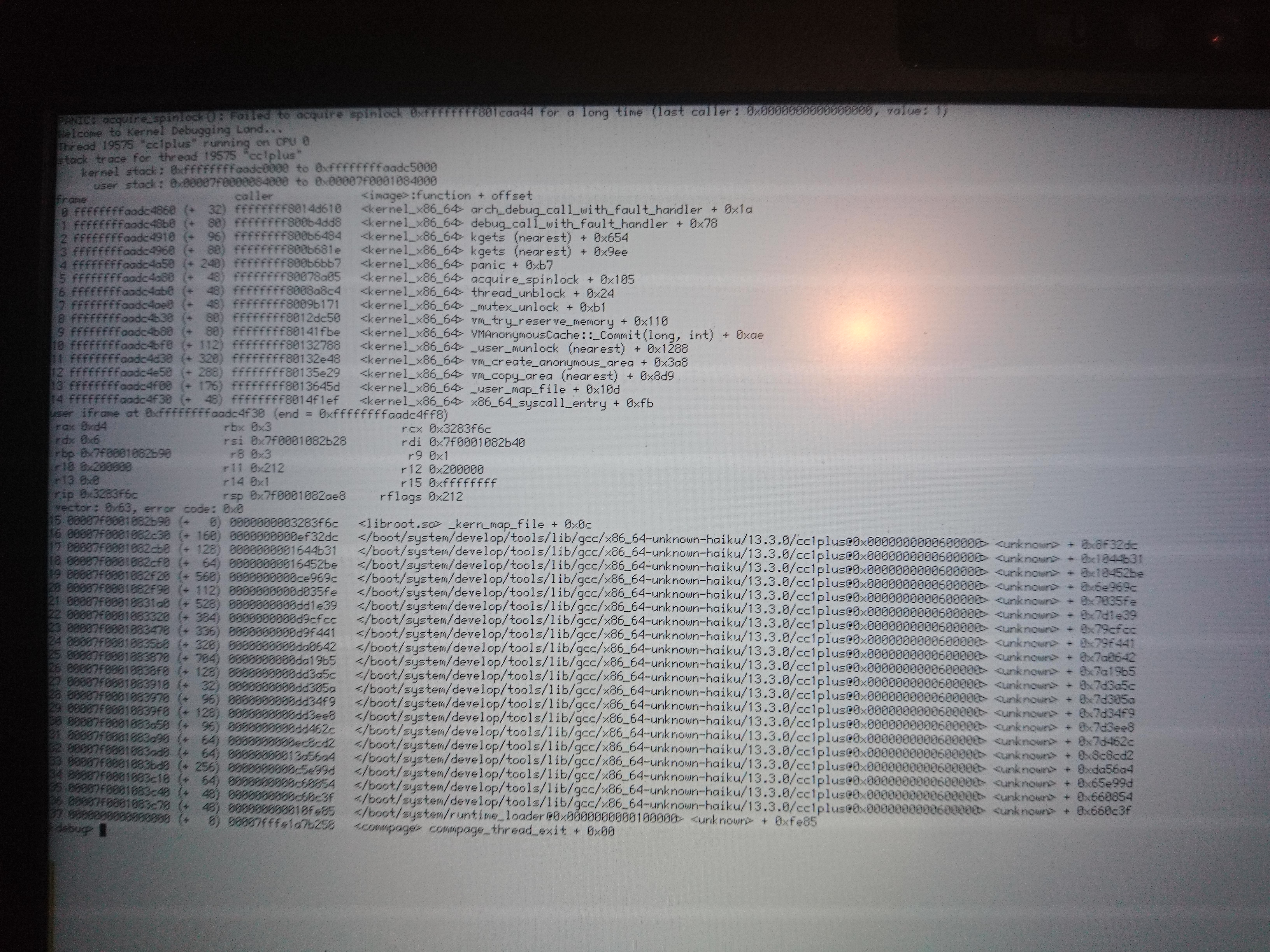
I looked at the generated assembly for vm_try_reserve_memory. Every single call to a mutex routine appears to be preceded by movq $_ZL20sAvailableMemoryLock, %rdi, so the mutex pointer isn't cached in a local register or on the stack. So I don't know what could be happening here.
comment:14 by , 5 months ago
comment:15 by , 5 months ago
I am beginning to wonder if this is yet another "spurious wakeup", whether from the mutex or the condition variable, though I looked them over again and can't see how that might happen. At any rate, this assertion may catch the problem:
@@ -1007,15 +1007,12 @@ _mutex_lock(mutex* lock, void* _locker)
// block
thread_prepare_to_block(waiter.thread, 0, THREAD_BLOCK_TYPE_MUTEX, lock);
locker->Unlock();
status_t error = thread_block();
-#if KDEBUG
- if (error == B_OK) {
- ASSERT(lock->holder == waiter.thread->id);
- }
-#endif
+ ASSERT((error != B_OK && lock->holder != waiter.thread->id)
+ || (error == B_OK && lock->holder == waiter.thread->id));
return error;
}
void
comment:16 by , 5 months ago
I added some hacks to vm_try_reserve_memory to run the loop on nearly all invocations even if there's no low-memory condition. And in relatively short order:
PANIC: vm_page_fault: unhandled page fault in kernel space at 0x30, ip 0xffffffff8009d3a8
Welcome to Kernel Debugging Land...
Thread 724 "dash" running on CPU 2
stack trace for thread 724 "dash"
kernel stack: 0xffffffff82136000 to 0xffffffff8213b000
frame caller <image>:function + offset
0 ffffffff8213a1d0 (+ 32) ffffffff801500a0 <kernel_x86_64> arch_debug_call_with_fault_handler + 0x1a
1 ffffffff8213a220 (+ 80) ffffffff800b7648 <kernel_x86_64> debug_call_with_fault_handler + 0x78
2 ffffffff8213a280 (+ 96) ffffffff800b8cf4 <kernel_x86_64> kernel_debugger_loop(char const*, char const*, __va_list_tag*, int) + 0xf4
3 ffffffff8213a2d0 (+ 80) ffffffff800b908e <kernel_x86_64> kernel_debugger_internal(char const*, char const*, __va_list_tag*, int) + 0x6e
4 ffffffff8213a3c0 (+ 240) ffffffff800b9427 <kernel_x86_64> panic + 0xb7
5 ffffffff8213a4b0 (+ 240) ffffffff80139250 <kernel_x86_64> vm_page_fault + 0x2e0
6 ffffffff8213a4f0 (+ 64) ffffffff8015c39e <kernel_x86_64> x86_page_fault_exception + 0x15e
7 ffffffff8213a848 (+ 856) ffffffff8015197c <kernel_x86_64> int_bottom + 0x80
kernel iframe at 0xffffffff8213a848 (end = 0xffffffff8213a910)
rax 0x0 rbx 0xffffffff98ae3320 rcx 0x4
rdx 0xffffffff8fe52040 rsi 0xfffffffb rdi 0xffffffff8fe51de4
rbp 0xffffffff8213a950 r8 0x50 r9 0xffffffff82211840
r10 0x1 r11 0x7d r12 0xffffffff
r13 0xffffffff8f8e95c8 r14 0xffffffff98ae32a0 r15 0xffffffff98ae3320
rip 0xffffffff8009d3a8 rsp 0xffffffff8213a910 rflags 0x10206
vector: 0xe, error code: 0x0
8 ffffffff8213a950 (+ 264) ffffffff8009d3a8 <kernel_x86_64> _mutex_lock + 0xd8
9 ffffffff8213a990 (+ 64) ffffffff8009dae3 <kernel_x86_64> mutex_switch_lock + 0x53
10 ffffffff8213a9d0 (+ 64) ffffffff80149682 <kernel_x86_64> VMCache::Unlock(bool) + 0xc2
11 ffffffff8213aa00 (+ 48) ffffffff8014a4ae <kernel_x86_64> VMCache::Delete() + 0x19e
12 ffffffff8213aa50 (+ 80) ffffffff8012d6bb <kernel_x86_64> delete_area(VMAddressSpace*, VMArea*, bool) + 0x17b
13 ffffffff8213aa90 (+ 64) ffffffff8012fde9 <kernel_x86_64> vm_delete_areas + 0xc9
14 ffffffff8213af20 (+1168) ffffffff800858de <kernel_x86_64> _user_exec + 0x31e
...
This is with the assertion changes I suggested above (they didn't fire). So clearly we have some problem here, perhaps the low_resource system changes some global or local state without an appropriate lock held?
comment:17 by , 5 months ago
I'm now on hrev58067. I didn't get a panic this time, instead it looks like the system just froze by running out of merory. CPU is idle, and the last entry in the syslog is the low resource manager going to critical.
Trying to open a new terminal tab didn't work (nothing qaphens). Trying to stop the compilation b' pressing ctrl+c also didn't work.
I'll see if I can reproduce this or if I get different problems. Running without -j6 to stress it a bit
comment:18 by , 5 months ago
It turns out the crash above was due to my newly added assertions, which are incorrect in the case when we were woken up by the mutex being destroyed. I reworked the assertion and committed it in hrev58103.
Also in that hrev is a change to how the low_resource call waits for runs. If this is a problem with spurious wakeups or something like that, then that change might affect behavior here.
by , 5 months ago
| Attachment: | DSC_0107.JPG added |
|---|
by , 5 months ago
| Attachment: | DSC_0108.JPG added |
|---|
by , 5 months ago
| Attachment: | DSC_0109.JPG added |
|---|
by , 5 months ago
| Attachment: | DSC_0110.JPG added |
|---|
comment:19 by , 5 months ago
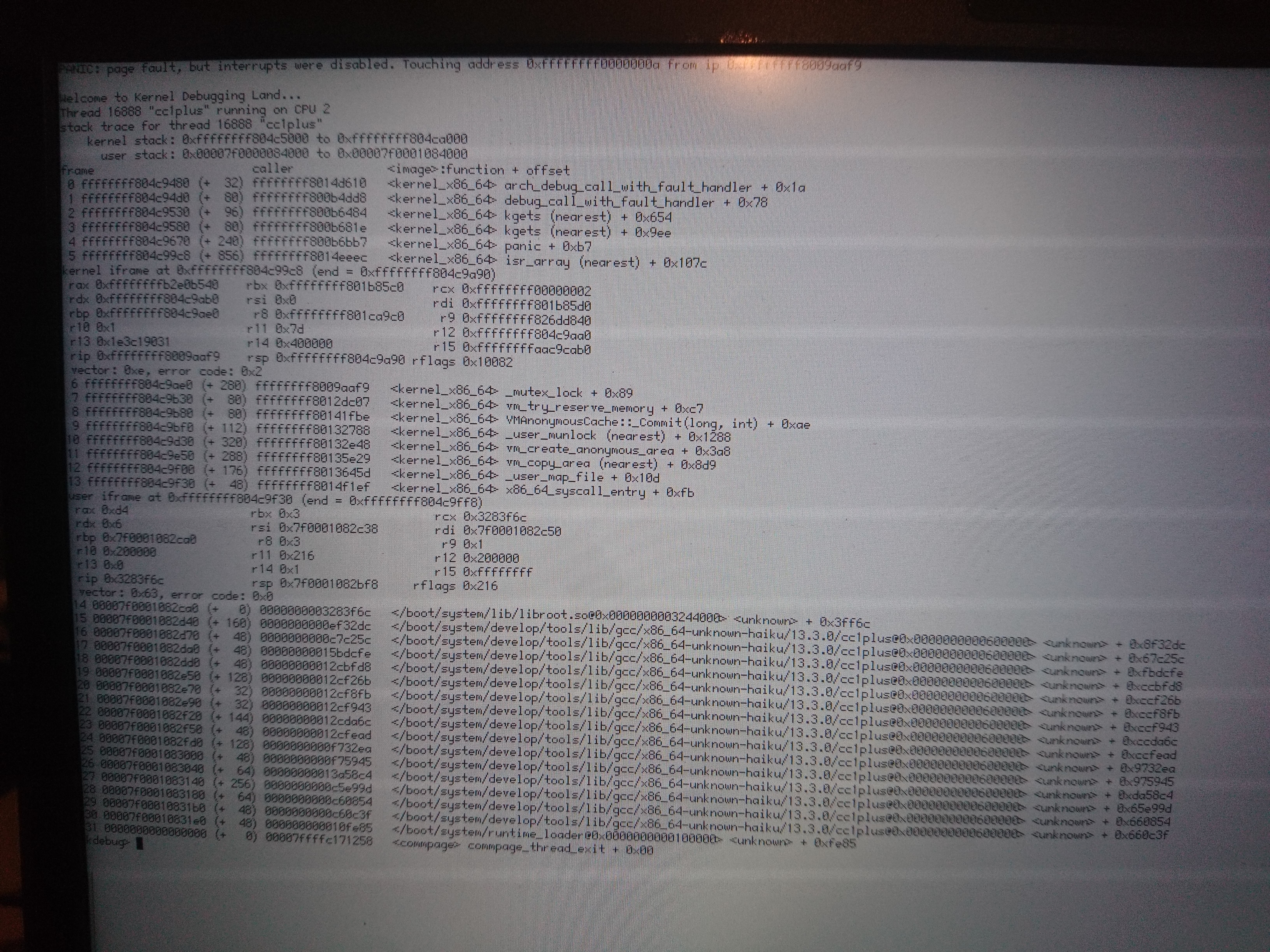
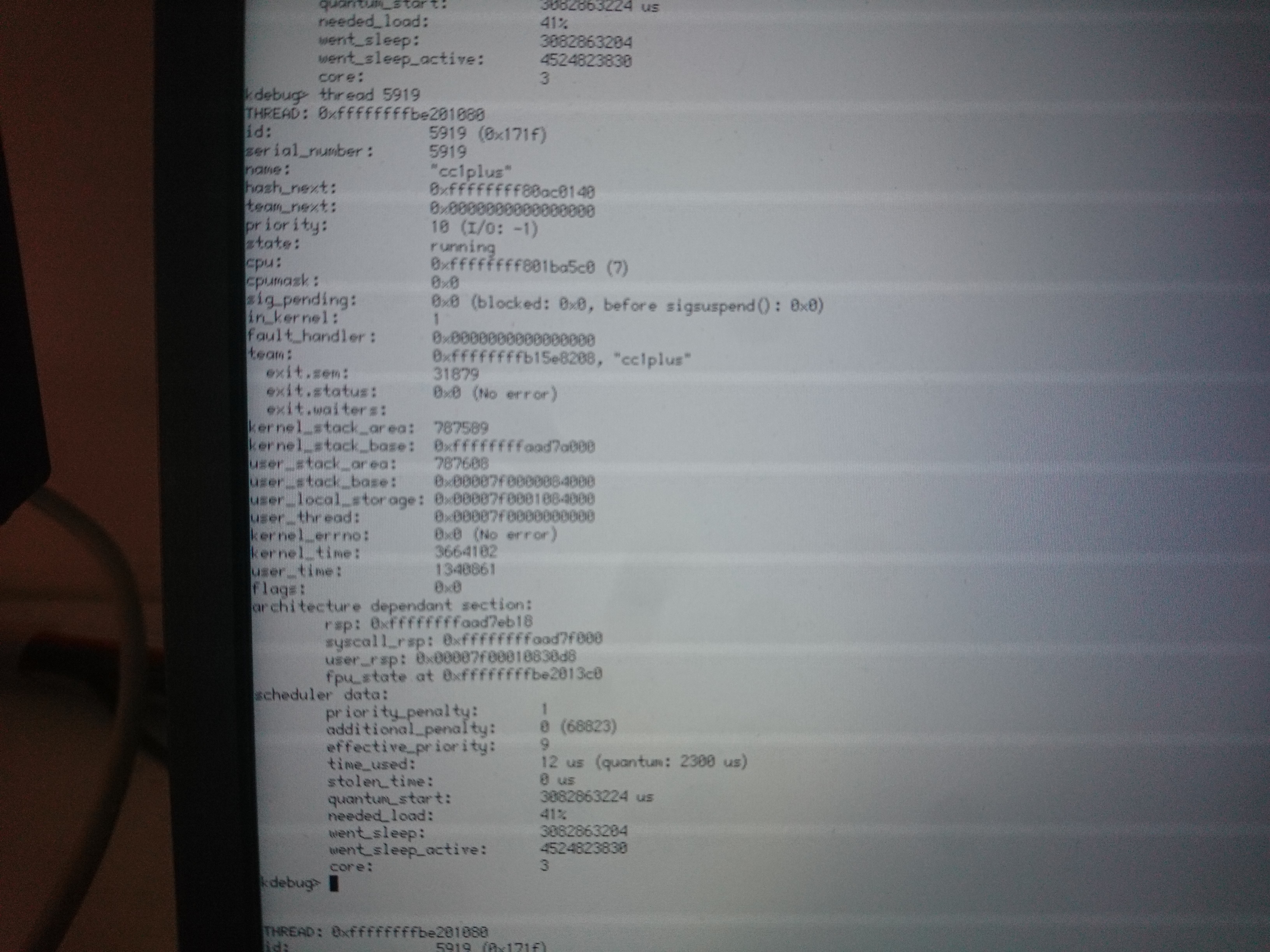
I had a look at the rwlock and its holder. I don't know this code well enough to know if that's helpful.
comment:20 by , 5 months ago
Yes, it's helpful.
The more I think about this, the more I think it can only be spurious wakeups. It's the only thing that seems to fit all the data: "mutex already locked by (this thread)", apparent stack corruptions (because the wait entry isn't removed on the spurious wakeup, so some other thread eventually writes to it and thus corrupts our stack), "rwlock not read locked" (because we were woken up with an error status, which was ignored), and so on.
If that's the case, then the new assertion added in hrev58103 should catch this happening.
But then the question will become what is spuriously waking these threads up. The low_resource condition variable isn't likely to be the culprit, because it's always awoken with a status of 0 and not an error code, and that would've already tripped the existing asserts in the mutex code. So, what could be waking up this thread, I'm not sure. I haven't managed to reproduce any crashes like this locally, even with hacks to run the low_resource logic in try_reserve_memory much more often (though admittedly I'm not testing with the same workload.)
comment:22 by , 5 months ago
| Milestone: | Unscheduled → R1/beta5 |
|---|---|
| Resolution: | → fixed |
| Status: | new → closed |
PulkoMandy reported on IRC that the WebKit build completed with no crashes. The above fix was pushed into beta5, too.
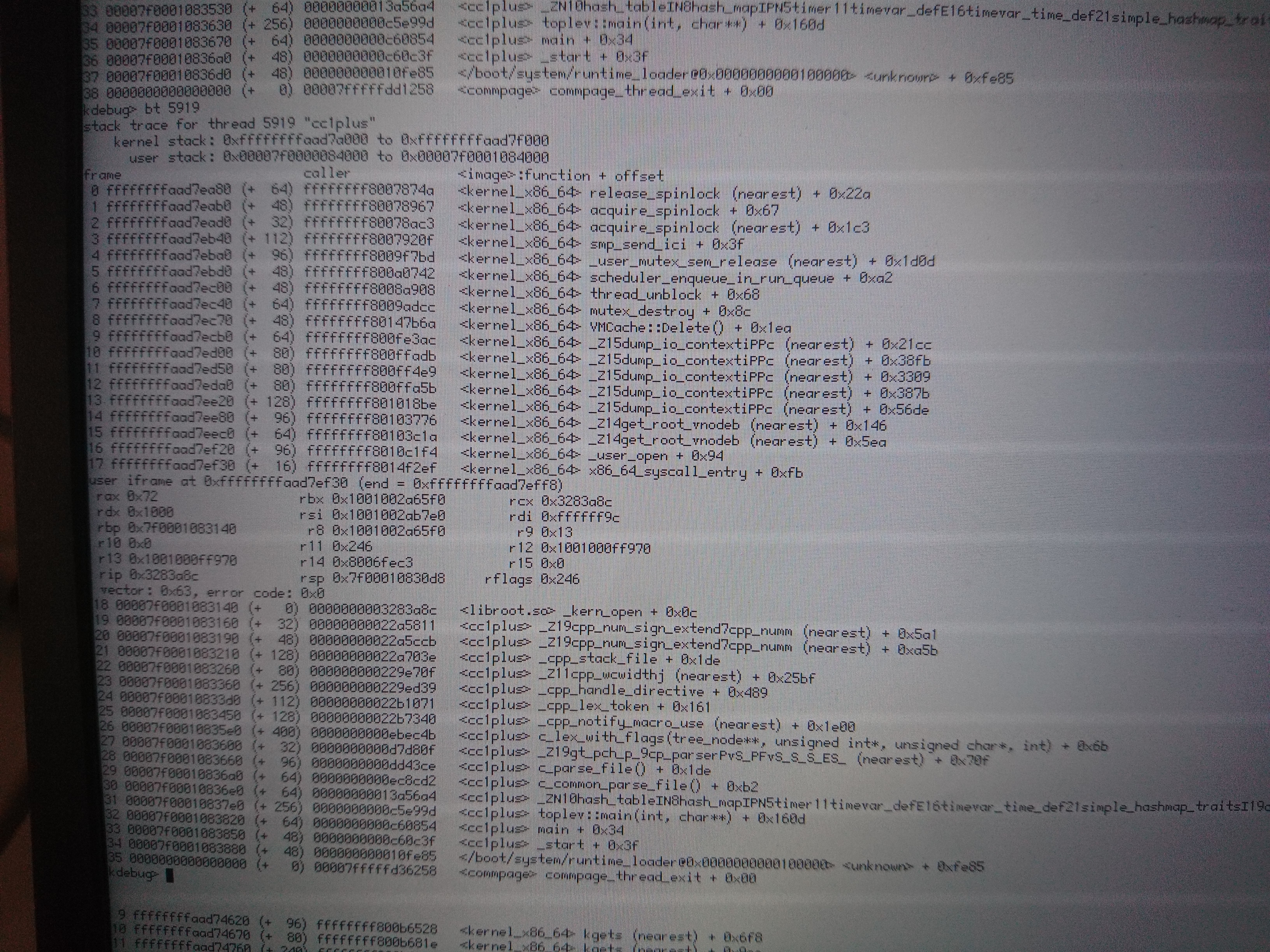
That stack trace looks wrong; the two functions that are "nearest" I don't think are in the call path of _user_map_file at all.
If this reproduces, can you try to spend some time determining what that address represents? It looks like a kernel area.
And what hrev was this?