

Opened 14 years ago
Closed 13 years ago
#7697 closed bug (fixed)
[AboutSystem] Link to MIT licence looks strange when localized
| Reported by: | taos | Owned by: | nobody |
|---|---|---|---|
| Priority: | normal | Milestone: | R1 |
| Component: | Applications/AboutSystem | Version: | R1/Development |
| Keywords: | localization | Cc: | |
| Blocked By: | Blocking: | ||
| Platform: | All |
Description
Using r1a3-rc-hrev42159.
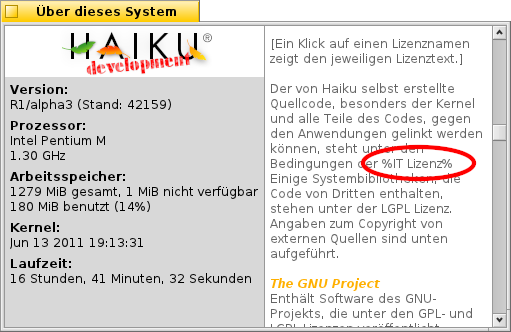
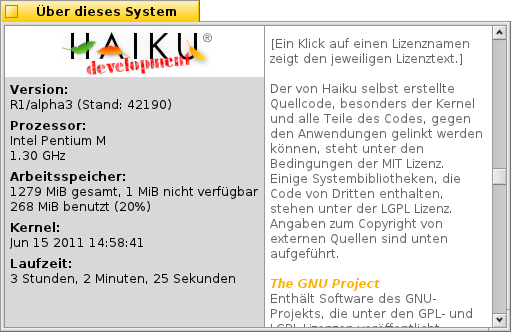
When using the german localization, the link "MIT licence" (string: ... %MIT licence% ...) in AboutSystem is displayed as "%IT Lizenz%" instead of "MIT Lizenz".
.")
Attachments (13)
{kind=link}
{kind=link}
{kind=link}
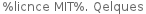{kind=link}
{kind=link}
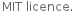{kind=link}
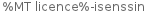{kind=link}
{kind=link}
{kind=link}
Change History (31)
by , 14 years ago
| Attachment: | MIT_link.png added |
|---|
comment:2 by , 14 years ago
Here are the corresponding excerpts from AboutSystem.cpp:
BPath mitPath;
_GetLicensePath("MIT", mitPath);
// Haiku license
BString haikuLicence = B_TRANSLATE("The code that is unique to Haiku, "
"especially the kernel and all code that applications may link "
"against, is distributed under the terms of the %MIT licence%. "
"Some system libraries contain third party code distributed under the "
"LGPL license. You can find the copyrights to third party code below.\n"
"\n");
int32 licencePart1 = haikuLicence.FindFirst("%");
int32 licencePart2 = haikuLicence.FindLast("%");
BString part;
haikuLicence.CopyCharsInto(part, 0, licencePart1 );
fCreditsView->Insert(part);
part.Truncate(0);
haikuLicence.CopyCharsInto(part, licencePart1 + 1, licencePart2 - 1
- licencePart1);
fCreditsView->InsertHyperText(part, new OpenFileAction(mitPath.Path()));
part.Truncate(0);
haikuLicence.CopyCharsInto(part, licencePart2 + 1, haikuLicence.CountChars()
- licencePart2);
fCreditsView->Insert(part);
Any ideas? The French version displays "%licnce MIT%" (catkeys: %licence MIT%), the Russian "%MIT licence%", the Finnish "%MT licence%-isenssin" (catkeys: %MIT licence%-lisenssin). It doesn't even show the correct phrase if this part of the string isn't translated at all. Only the non-localized English variant works.
BTW, apart from this sentence, the spelling "license" is used everywhere else in AboutSystem.
comment:3 by , 14 years ago
It should be license which is American English, whilst the spelling licence is British English.
follow-up: 5 comment:4 by , 14 years ago
IMO this is an excessive localization - the names of licenses must not be localized at all, because it breaks the "click and read" functionality in the list of installed software.
comment:5 by , 14 years ago
Replying to siarzhuk:
IMO this is an excessive localization - the names of licenses must not be localized at all, because it breaks the "click and read" functionality in the list of installed software.
I've also noticed this (see #7491 AboutSystem: clicking on localized license name doesn't open license file). But in this case, the "click and read" functionality works fine in a localized system. It's only the graphical representation of the licence name that is a little odd - even if the licence name itself isn't translated. At the moment, if you don't translate this part of the string you'll still get "%MIT licence%" instead of "MIT licence". Only in an English system, the %s are cut as intended.
comment:6 by , 14 years ago
Okay, call me completely mad. I think I found the problem: Characters with diacritics (e.g. é, ö, ñ) are counted twice (but why?). Therefore, the string is cut into parts at the wrong places. Instead of cutting out the %s (... |%|MIT...|%| ...), the cut position is shifted (e.g. ... %|M|IT...%| |...).
There is a linear correlation between the number of characters with diacritics in the translated string before %MIT...% and the shifting of the cut position.
| language | number of diacritics | shift of cutting position | cutting positions | screenshot |
|---|---|---|---|---|
| English | 0 | 0 | |%|MIT licence|%|. | 
|
| Dutch | 0 | 0 | |%|MIT-licence|%|. | 
|
| German | 1 (ö) | +1 | %|M|IT Lizenz%|.| | 
|
| Italian | 2 (è, è) | +2 | %l|i|cenza MIT%.| |Alcune | 
|
| Finnish | 2 (ä, ä) | +2 | %M|I|T licence%-|l|isenssin | 
|
| French | 4 (é, à, é, é) | +4 | %lic|e|nce MIT%. Q|u|elques | 
|
| Spanish | 5 (ó, ú, ú, ó, é) | +5 | %lice|n|cia MIT%. Al|g|unas | 
|
EDIT: As soon as the translation uses non-ASCII characters, the cutting is off. With a language written in non-latin script (cyrillic, CJK, etc) it is so bad that you have to click a few lines below the license name to activate the link and open the license file.
Any ideas how to solve this?
follow-up: 8 comment:7 by , 14 years ago
Hey, you're getting close! :-)
The problem you're describing happens because not each character uses up the same number of bytes (we're using UTF-8 encoding everywhere). While not apparent, the code in question mixes byte offsets/lengths with character offsets/lengths, and is therefore causing the problems. For example, FindFirst() is byte based, while CountChars() is character based.
comment:8 by , 14 years ago
Replying to axeld:
For example, FindFirst() is byte based, while CountChars() is character based.
Good to know. I've seen mentioned in The Haiku Book that CountChars() is aware of UTF8 and therefore counts the actual number of characters but I was not sure about FindFirst(), FindLast(), and Truncate().
So, is there already an easy way to make byte offsets compatible with character offsets? I guess something similar might have happened somewhere else in the haiku source code.
follow-up: 10 comment:9 by , 14 years ago
Hmmm, okay. If I replace CopyCharsInto() with CopyInto() and CountChars() with Length() the string is cut at the correct place - only both %s are removed as intended.
The graphical representation is okay (see screenshot below), the "click and read" functionality is still there (and at the correct place even in a Japanese or Russian system).
.")
But, I'm not sure if removing the awareness of UTF8 in the code is the right way. However, if you're interested in a quick and dirty fix I can attach a patch file.
by , 14 years ago
| Attachment: | AboutSystem_no_Chars.png added |
|---|
Screenshot of patched AboutSystem (German localization).
follow-ups: 11 12 comment:10 by , 14 years ago
Replying to taos:
Hmmm, okay. If I replace CopyCharsInto() with CopyInto() and CountChars() with Length() the string is cut at the correct place - only both %s are removed as intended. ... But, I'm not sure if removing the awareness of UTF8 in the code is the right way.
The other way around would be the better way, i.e. replacing the calls with their *Chars() version instead. There are Find{First|Last}Chars() versions as well, so you can make all the calls Chars aware.
comment:11 by , 14 years ago
Replying to mmlr:
The other way around would be the better way, i.e. replacing the calls with their *Chars() version instead. There are Find{First|Last}Chars() versions as well, so you can make all the calls Chars aware.
Really? That's what I tried first, but I couldn't compile the changed code because of a "no matching function for call to..." error. I'll try again - might have been a typo on my side.
follow-up: 13 comment:12 by , 14 years ago
Replying to mmlr:
The other way around would be the better way, i.e. replacing the calls with their *Chars() version instead. There are Find{First|Last}Chars() versions as well, so you can make all the calls Chars aware.
In this particular case, it doesn't really matter, as the '%' character is no UTF-8 character, and that's the only thing which matters for this code. So I think either solution would be fine. Patches welcome :-)
follow-up: 14 comment:13 by , 14 years ago
Replying to axeld:
In this particular case, it doesn't really matter, as the '%' character is no UTF-8 character, and that's the only thing which matters for this code. So I think either solution would be fine.
Since the *Char* variants are slower, I'd even say the non-UTF-8 aware solution is preferrable.
Patches welcome :-)
Ideally one also fixing the off-by-one error in the last CopyCharsInto() call.
follow-up: 16 comment:14 by , 14 years ago
Replying to bonefish:
Since the
*Char*variants are slower, I'd even say the non-UTF-8 aware solution is preferrable.Patches welcome :-)
Added two patches: First one (AboutSystem.cpp.patch) doesn't change the spelling of "licence" - can be used with the catkeys from HTA in alpha 3 branch. Second patch (AboutSystem.cpp.consistent_spelling_of_license.patch) changes the spelling to the US variant "license" but needs new catkeys.
Ideally one also fixing the off-by-one error in the last
CopyCharsInto()call.
Not really sure???
comment:15 by , 14 years ago
| patch: | 0 → 1 |
|---|
follow-up: 17 comment:16 by , 14 years ago
Replying to taos:
Ideally one also fixing the off-by-one error in the last
CopyCharsInto()call.Not really sure???
It starts copying at index licencePart2 + 1, but copies haikuLicence.Length() - licencePart2 bytes, which is one too many. It doesn't really matter, since the method clamps the length anyway, but still no reason not to pass the correct value.
by , 14 years ago
| Attachment: | AboutSystem.cpp.patch added |
|---|
Patch to fix display of MIT license link (compatible with current catkeys in alpha3-rc).
by , 14 years ago
| Attachment: | AboutSystem.cpp.consistent_spelling_of_license.patch added |
|---|
Patch to fix display of MIT license link and introduces consistent spelling of license (needs new catkeys).
comment:17 by , 14 years ago
Replying to bonefish:
It starts copying at index
licencePart2 + 1, but copieshaikuLicence.Length() - licencePart2bytes, which is one too many.
Thanks, I changed the patch files accordingly.
by , 13 years ago
| Attachment: | AboutSystem_updated_r42387.patch added |
|---|
Updated patch to fix display of MIT license link and to introduce consistent spelling of "license".
by , 13 years ago
| Attachment: | AboutSystem_updated_r42512.patch added |
|---|
Updated patch to fix display of MIT license link and to introduce consistent spelling of "license".
comment:18 by , 13 years ago
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
Applied with hrev42514. Closing as fixed. We'll see if it finally nailed the bugger when the translated catkeys arrive. Thanks a lot.
Link to MIT licence in AboutSystem (german localization).