

Opened 11 years ago
Last modified 6 months ago
#10312 new bug
Kernel runs out of address space in checkfs
| Reported by: | kallisti5 | Owned by: | axeld |
|---|---|---|---|
| Priority: | high | Milestone: | R1 |
| Component: | System/Kernel | Version: | R1/Development |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | #12118 | |
| Platform: | All |
Description
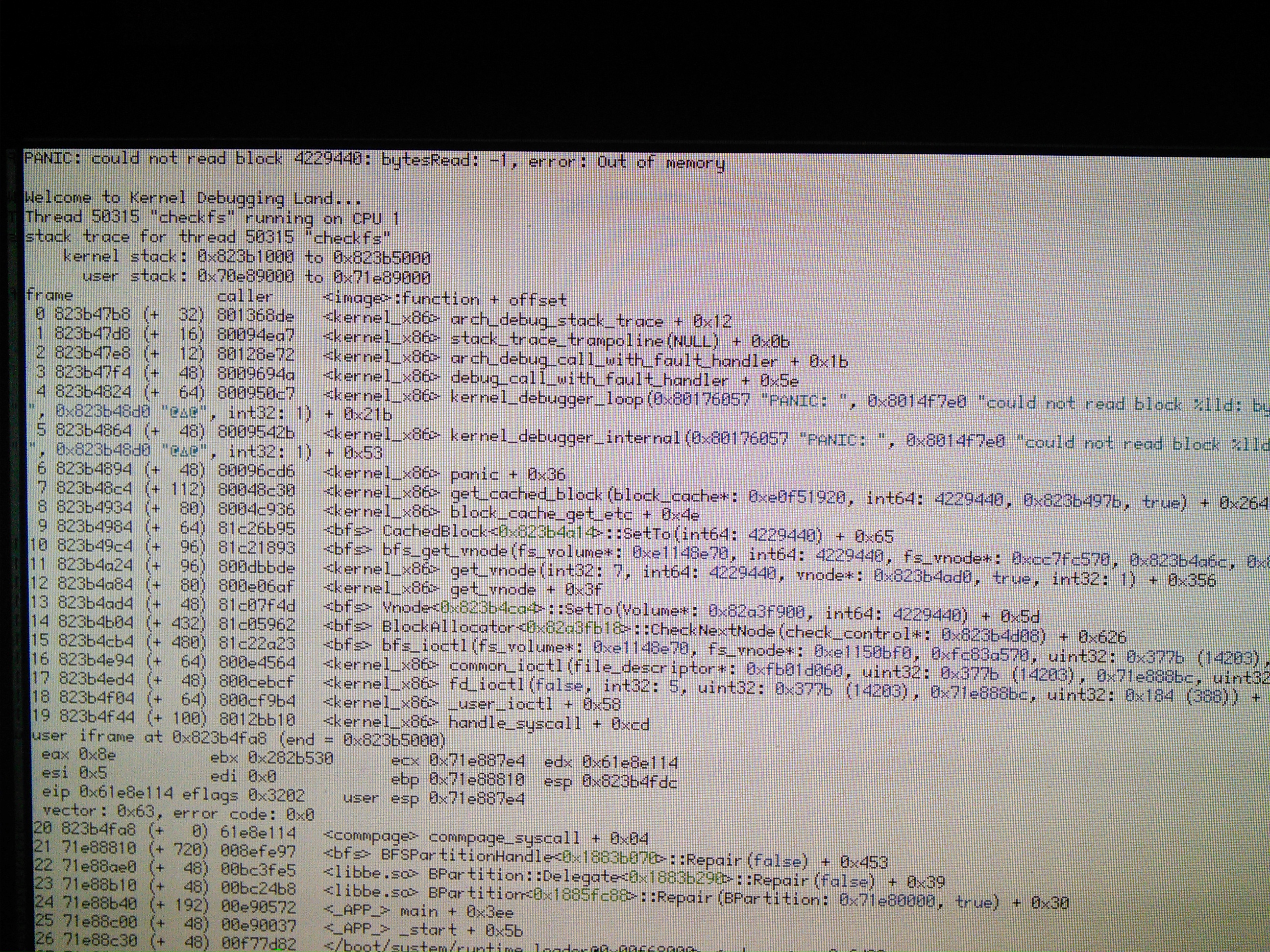
If a large number of errors exist on a bfs filesystem, the kernel can run out of address space for checkfs (screenshot attached of kdl)
tested in hrev46530 gcc2h
Attachments (1)
{kind=link}
{kind=link}
Change History (11)
by , 11 years ago
| Attachment: | IMG_20131213_231308.jpg added |
|---|
comment:1 by , 11 years ago
comment:2 by , 11 years ago
| Priority: | normal → high |
|---|
I'm hitting something similar here. I didn't wait until KDL, however.
- Run checkfs on a small partition (2GB): kernel memory use increases, not freed after checkfs is done
- Run checkfs on a bigger partition (100GB): kernel memory reaches about 1.7GB, then system becomes very unresponsive (app server struggles to redraw the screen or even keep the mouse cursor moving)
comment:3 by , 10 years ago
| Milestone: | R1 → R1/alpha5 |
|---|
Moving to A5 as this sounds like a serious resource leak.
comment:4 by , 10 years ago
It's not a resource leak AFAICT, just a problem of how the block cache maintains its memory.
comment:5 by , 10 years ago
| Milestone: | R1/alpha5 → R1/beta1 |
|---|
comment:6 by , 10 years ago
Panic is easily reproductible here with an identical stack trace. I had a look at the block_cache KDL command. There are 3 block caches (1 per mounted volume I guess?).
BLOCK CACHE: 0x8280aa80 fd: 0 max_blocks: 1572864 block_size: 2048 next_transaction_id: 41 buffer_cache: 0x82c6ba18 busy_reading: 0, no waiters busy_writing: 0, no waiters 8018 blocks total, 1 dirty, 0 discarded, 0 referenced, 0 busy, 8017 in unused. BLOCK CACHE: 0xd300d248 fd: 34 max_blocks: 1572864 block_size: 2048 next_transaction_id: 226 buffer_cache: 0xd40cb688 busy_reading: 0, no waiters busy_writing: 0, no waiters 807 blocks total, 0 dirty, 0 discarded, 0 referenced, 0 busy, 807 in unused. BLOCK CACHE: 0xd4076190 fd: 33 max_blocks: 24588800 block_size: 2048 next_transaction_id: 64 buffer_cache: 0xd40cb548 busy_reading: 1, no waiters busy_writing: 0, no waiters 311080 blocks total, 20 dirty, 0 discarded, 0 referenced, 1 busy, 311060 in unused.
I notice the first one has fd 0, but I assume this is not a problem (probably the root FS is mounted first and gets the first FD number?)
The third one is relevant. While it is not too busy at this point (only 20 dirty blocks), there is a big number of unused blocks and a very high max_blocks. Still, 311060 * 2048 is only 622MB, not enough to run out of memory. The max_blocks appears to allow allocating 24 million blocks, which at 2K by block would be enough to run out of 32-bit address space (4.8GB). Shouldn't we limit this value somehow?
avail lists about 6.25GB RAM free on this 8GB system.
I'm not sure what else I should be looking for?
comment:7 by , 10 years ago
| Milestone: | R1/beta1 → R1 |
|---|
comment:8 by , 8 years ago
| Component: | File Systems/BFS → System/Kernel |
|---|
max_blocks is not the maximum number of blocks to cache, but refers to the highest accessible block number for that device (so 24588800 * 2K = 46,9 GB which should correspond to your partition size).
The root FS does not have any block cache, this should be your boot disk.
I only find the huge number of unused blocks a bit worrying -- that accounts for 640 MB alone. Those should obviously be freed with a bit more enthusiasm.
comment:10 by , 6 months ago
Is this fixed with the adjustments to block cache's memory pressure handling, and then the memory leak fixes?
still exists as of hrev46796