

#15211 closed bug (fixed)
KDL in MultiLocker::ReadLock()
| Reported by: | 3dEyes | Owned by: | waddlesplash |
|---|---|---|---|
| Priority: | normal | Milestone: | R1/beta2 |
| Component: | System/Kernel | Version: | R1/Development |
| Keywords: | Cc: | mmlr, korli | |
| Blocked By: | Blocking: | #15227, #15229 | |
| Platform: | All |
Description (last modified by )

Attachments (5)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (32)
by , 5 years ago
| Attachment: | photo_2019-07-30_20-35-45.jpg added |
|---|
comment:1 by , 5 years ago
| Description: | modified (diff) |
|---|
comment:2 by , 5 years ago
| Description: | modified (diff) |
|---|
comment:3 by , 5 years ago
comment:4 by , 5 years ago
| Cc: | added |
|---|---|
| Component: | - General → System/Kernel |
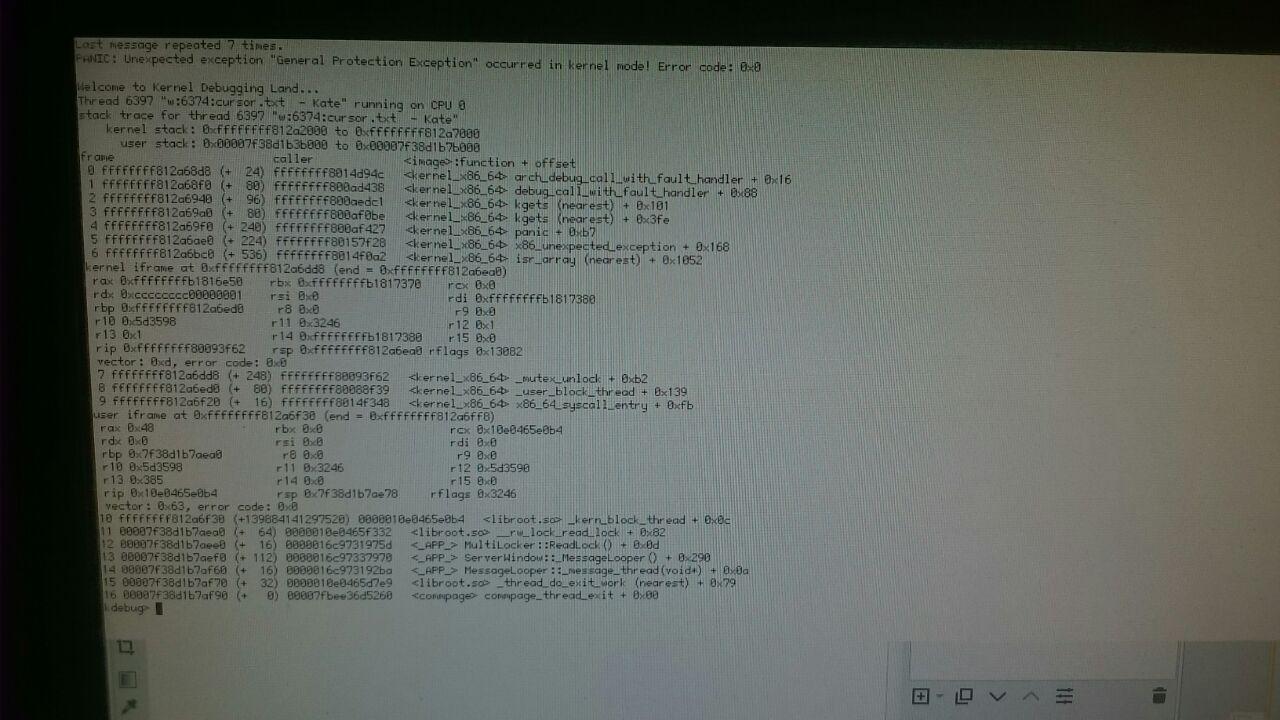
_user_block_thread only hits one mutex -- the thread's. So I'm not sure how this is somehow turning into a GPE; the thread mutex should obviously not be destroyed or otherwise altered while the thread is alive. (And since this is in unlock, the mutex lock obviously did not cause a problem.)
The "isr_array (nearest)" seems suspicious. That's presumably here. Are we running past the end of it or something?
CC korli and mmlr: do either of you have an idea as to what might be occurring here? This is a little over my head, still.
comment:5 by , 5 years ago
0xcccccccc00000001 is in the non-canonical address hole on x86_64, accessing it triggers a GPE.
From https://software.intel.com/sites/default/files/managed/39/c5/325462-sdm-vol-1-2abcd-3abcd.pdf :
3.3.7.1 Canonical Addressing In 64-bit mode, an address is considered to be in canonical form if address bits 63 through to the most-significant implemented bit by the microarchitecture are set to either all ones or all zeros. Intel 64 architecture defines a 64-bit linear address. Implementations can support less. The first implementation of IA-32 processors with Intel 64 architecture supports a 48-bit linear address. This means a canonical address must have bits 63 through 48 set to zeros or ones (depending on whether bit 47 is a zero or one). Although implementations may not use all 64 bits of the linear address, they should check bits 63 through the most-significant implemented bit to see if the address is in canonical form. If a linear-memory reference is not in canonical form, the implementation should generate an exception. In most cases, a general-protection exception (#GP) is generated. However, in the case of explicit or implied stack references, a stack fault (#SS) is generated.
comment:6 by , 5 years ago
Ah. Well, that address looks like garbage, where did it come from? Is this memory corruption, maybe?
threedeyes, can you reproduce this?
comment:7 by , 5 years ago
It all started after the upgrade to the specified revision. The KDL is spontaneously in various situations. The first time I started the recipe build: hp wonderbrush (at the time of downloading the archive). The second time this happened was when I worked in Pe and switched the active window to the Kate editor. I did a memory test - everything is ok. I could not get syslog yet - I will try to save it if it happens again.
comment:8 by , 5 years ago
The address contains 0xcccccccc which would match the "uninitialized memory" pattern written by the normal allocator. Since the lock cannot really be uninitialized (as one would expect the corresponding lock to fail in that case), this might be a use-after-free case where the allocation has been handed out again already. Is it possible that the thread went away due to a missing reference or some such?
The isr_array (nearest) is a red herring as (nearest) always just means that the symbol lookup did not find an actual match. This can happen in some generated and/or optimized code and usually means that it's not actually where it suggest it might be.
by , 5 years ago
| Attachment: | photo_2019-08-01_21-41-59.jpg added |
|---|
by , 5 years ago
| Attachment: | previous_syslog added |
|---|
comment:10 by , 5 years ago
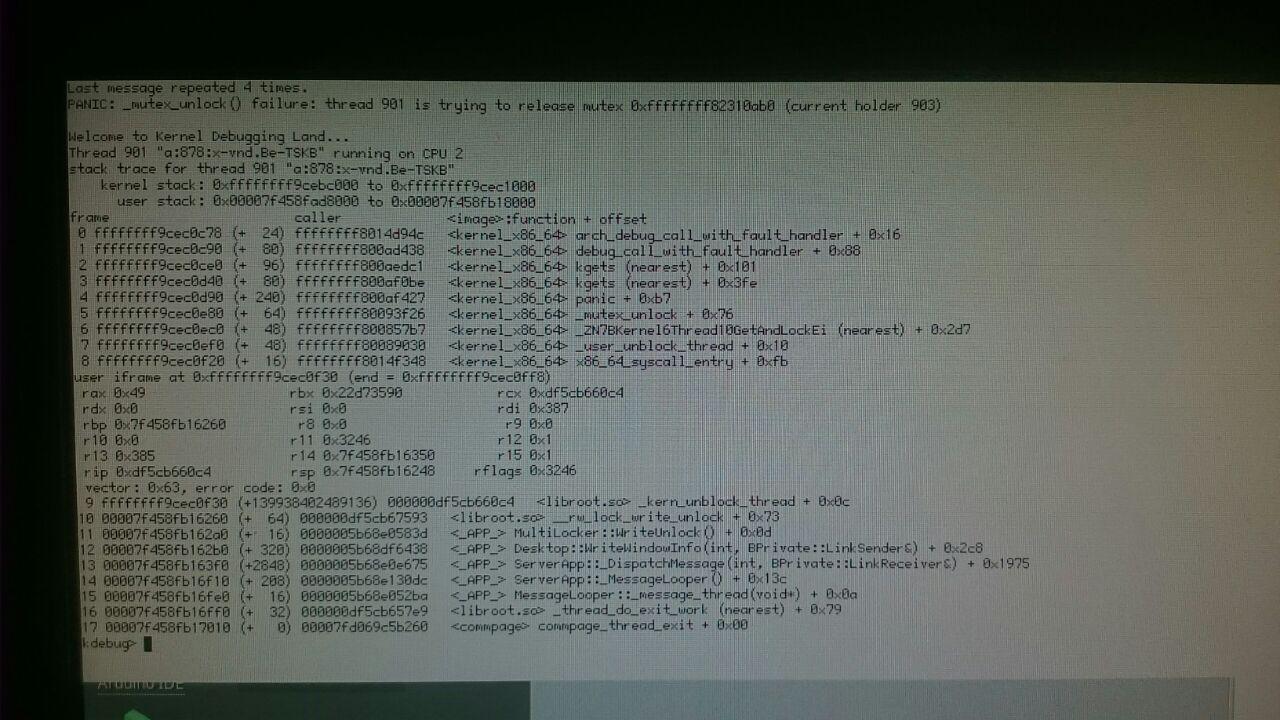
This is actually the opposite panic; it's occuring on unlock, not lock. And it's not a GPE, it seems to be one of the assert failures in the mutex code; but you've typed bt again (why? There's already a backtrace printed automatically...) and so the actual message is cut off.
This is much more interesting than the last one. The thread_block syscall only operates on the current thread, which there really is no way of destroying while it is running, and so the thread structure getting corrupted is about the only option. Since this is now occurring inside GetAndLock, this means the thread is still in the hash, but the mutex is indeed destroyed or corrupted. So then this is pretty much proof there is memory corruption.
threedeyes, can you please do a guarded heap build of the kernel, and additionally change the thread structs to be allocated from the heap rather than their object cache? That should hopefully catch whatever is corrupting memory here.
by , 5 years ago
| Attachment: | photo_2019-08-01_21-41-05.jpg added |
|---|
comment:11 by , 5 years ago
but you've typed bt again (why? There's already a backtrace printed automatically...)
Ooops, sorry. Original photo attached.
can you please do a guarded heap build of the kernel, and additionally change the thread structs to be allocated from the heap rather than their object cache?
I try.
So then this is pretty much proof there is memory corruption.
I've run the memory test three times , it's okay.
comment:12 by , 5 years ago
Oh, I doubt it's a case of bad memory, it's probably a memory bug in the kernel itself.
comment:13 by , 5 years ago
The panic message says that the mutex is being released from the wrong thread. The thread ids 901 and 903 are reasonably close, so that it seems plausible. I would not conclude memory corruption from this. If it is indeed the case that the locks are being triggered from the wrong threads, all sorts of strange things may happen.
comment:14 by , 5 years ago
That also does not make sense here. How is this one use case triggering the problem?
comment:15 by , 5 years ago
I don't think the current multilocker looks safe. The check if it is locked and the action afterward is not done in any kind of transaction. No lock, no mem barrier. So when the action is done it might have already changed state by another thread. If it is intentional that several threads see it as unlocked and then start locking it should be documented. I also see problems if several threads would call destruction.
I don't think these kind of changes should be done this lightly, and I would like to see some tests to guarantee that it has been proven to work before commited.
You should be able to test this with mock threads and sleeps right after each lock check return otherwise you will have subtle errors like this where lock thread will be updated as soon as sem is relaased as others hang there.
comment:16 by , 5 years ago
I'm confused. The new MultiLocker just uses rw_lock; is that what you are referring to that has problems here? My new MultiLocker implementation definitely doesn't need memory barriers or the like, the rw_lock should be more than enough.
Even if those things were somehow a problem here, this is crashing in the kernel. Under no circumstances should userland be able to trigger an assert failure or GPE or anything else like that in the kernel. So this is a kernel bug no matter what.
comment:17 by , 5 years ago
So you ask should I grab the lock or do something else depending on the state. The state however changes at any point as any other thread may lock or unlock in the meantime.
If it is not locked then you should lock, but another thread asked the same and got the same answer. So you have two threads that think that they are the ones that should lock. If it was done as an transaction (ie protected by a lock) the other thread would see that it was locked already).
Look at Ingo's RWLocker for how he has a lock to protect and do the action in one transaction.
comment:18 by , 5 years ago
I still don't know what you are referring to here. The IsWriteLocked is not used to determine if the lock is "busy", it is used to determine if the current thread holds the lock. If some other thread holds the lock, it returns false.
comment:20 by , 5 years ago
It is the equivalent of BLocker::IsLocked which has identical semantics.
comment:21 by , 5 years ago
Yes, unfortunate naming. I looked at the debug functions as well, not the proper ones. using a rw lock looks perfect. But do we want to define DEBUG if it is not defined?
comment:22 by , 5 years ago
| Blocking: | 15227 added |
|---|
comment:23 by , 5 years ago
| Blocking: | 15229 added |
|---|
comment:24 by , 5 years ago
comment:25 by , 5 years ago
hrev53340+2 32bit.
All of a sudden got:
KERN: PANIC: ASSERT FAILED (../../haiku/src/system/kernel/locks/lock.cpp:785): lock->holder == waiter.thread->id.
The panic was continuable, so I saved a syslog,
by , 5 years ago
comment:27 by , 5 years ago
| Milestone: | Unscheduled → R1/beta2 |
|---|
Assign tickets with status=closed and resolution=fixed within the R1/beta2 development window to the R1/beta2 Milestone
Please attach a syslog.