

Opened 5 years ago
Last modified 8 months ago
#15886 assigned bug
tcp addon doesn't actually support window scaling
| Reported by: | ambroff | Owned by: | ambroff |
|---|---|---|---|
| Priority: | normal | Milestone: | Unscheduled |
| Component: | Network & Internet/TCP | Version: | R1/Development |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | ||
| Platform: | All |
Description
I've been looking in to network performance today. There are other related issues that hurt performance like #12876 regarding how performance of a given network connection degrades over time. In investigating this, I found an unrelated issue in the tcp addon.
There is some support for window scaling defined in RFC7323. This is supposed to be an extension of the original window definition, which was a 16-bit field in the header, which meant that the max window size was 65KiB. A window scale factor can be defined with a value between 0 and 14, allowing either end of the stream to shift the window size by that window factor. This allows for defining a window size of up to 0xffff << 14 = 1GiB.
TCPEndpoint, as of hrev54052, seems to support this behavior, although I have not yet confirmed whether it is done correctly. One thing that I have confirmed though, is that this scale factor is not actually used. When a TCPEndpoint is constructed, it is given a net_socket object which defines the default window size.
tcp_init_protocol(net_socket* socket)
{
socket->send.buffer_size = 32768;
// override net_socket default
TCPEndpoint* protocol = new (std::nothrow) TCPEndpoint(socket);
...
The send window is set to 32KiB in 6f58064f to work around a bug, but that may not be valid any longer. socket->receive.buffer_size will default to 65535.
net_socket_private::net_socket_private()
...
{
...
// set defaults (may be overridden by the protocols)
send.buffer_size = 65535;
...
receive.buffer_size = 65535;
}
In the current code, this serves as the initial window size that is chosen for receiving TCP segments (receive.buffer_size) as well as the expected window of the other end of the stream (send.buffer_size).
TCPEndpoint's constructor uses these values for several things. First, it sets the initial window size of this end of the stream (fReceiveWindow) to be receive.buffer_size, or 65KiB. This is pretty typical with most TCP implementations. It also initializes the window shift factor (fReceiveWindowShift) to 0 initially.
When a connection is established in TCPEndpoint::_PrepareSendPath, it has to figure out the max scale factor that it can advertise to the other end of the stream, which is a field in the SYN packet.
// Compute the window shift we advertise to our peer - if it doesn't support
// this option, this will be reset to 0 (when its SYN is received)
fReceiveWindowShift = 0;
while (fReceiveWindowShift < TCP_MAX_WINDOW_SHIFT
&& (0xffffUL << fReceiveWindowShift) < socket->receive.buffer_size) {
fReceiveWindowShift++;
}
This is the first problem right here. This will never compute a value larger than 0 for the window shift factor, since socket->receive.buffer_size is always fixed at 65KiB, or 0xffff. socket->receive.buffer_size should be just the initial window size, and the advertized max window scaling factor should be a function of the amount of available memory for buffering those segments.
Since this is the only opportunity to tell the other side that we support window sizes larger than 65KiB, they will never try to send us more 65KiB worth of segments.
The other problem is that TCPEndpoint uses socket->receive.buffer_size to set the max amount of memory that can be used to buffer segments received.
fReceiveQueue(socket->receive.buffer_size),
This value should really be a factor of available memory, not the initial window size. Other systems like Linux have a guaranteed minimum amount of memory that is available for receiving segments on every TCP stream, usually 4KiB or one page. This is guaranteed even if there is memory pressure, since it's allocated along with the socket data structures. But if there is free memory, it can scale up to some defined maximum.
$ sysctl net.ipv4.tcp_rmem net.ipv4.tcp_rmem = 4096 87380 6291456
This is just for the receive path, I haven't analyzed the send path yet.
Obviously this needs to be carefully analyzed to figure out the actual properties of the current implementation, and we need to propose a new scheme that will not use tons of memory but will still allow for higher throughput.
I think during session establishment, TCPEndpoint should determine which window scaling factor to include in the SYN based on available memory. For example, if the system has 1GiB of memory, then it makes no sense to advertise a scaling factor of 14, because you don't have room to actually buffer 1GiB of segments. Likewise, fReceiveQueue should be allowed to grow up to the advertised scale factor unless there is memory pressure. If the max window scaling factor is advertised, but there is memory pressure and fReceiveQueue cannot grow, then some segments will be dropped and the sender will back off by halving the window size anyway.
To demonstrate what a huge difference this makes, just a simple change (that is too simple to actually ship) of hard-coding the window scaling factor to 14 and setting the max size of fReceiveQueue to 0xffff<<14, the throughput for a synthetic benchmark improves by orders of magnitude.
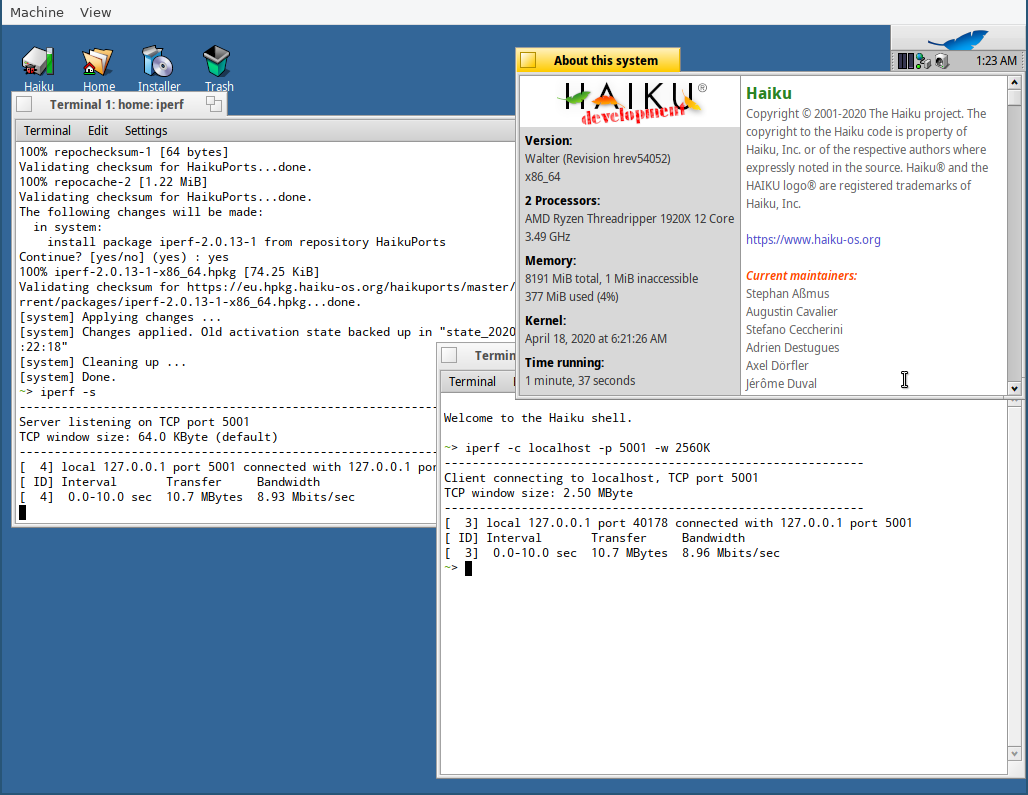
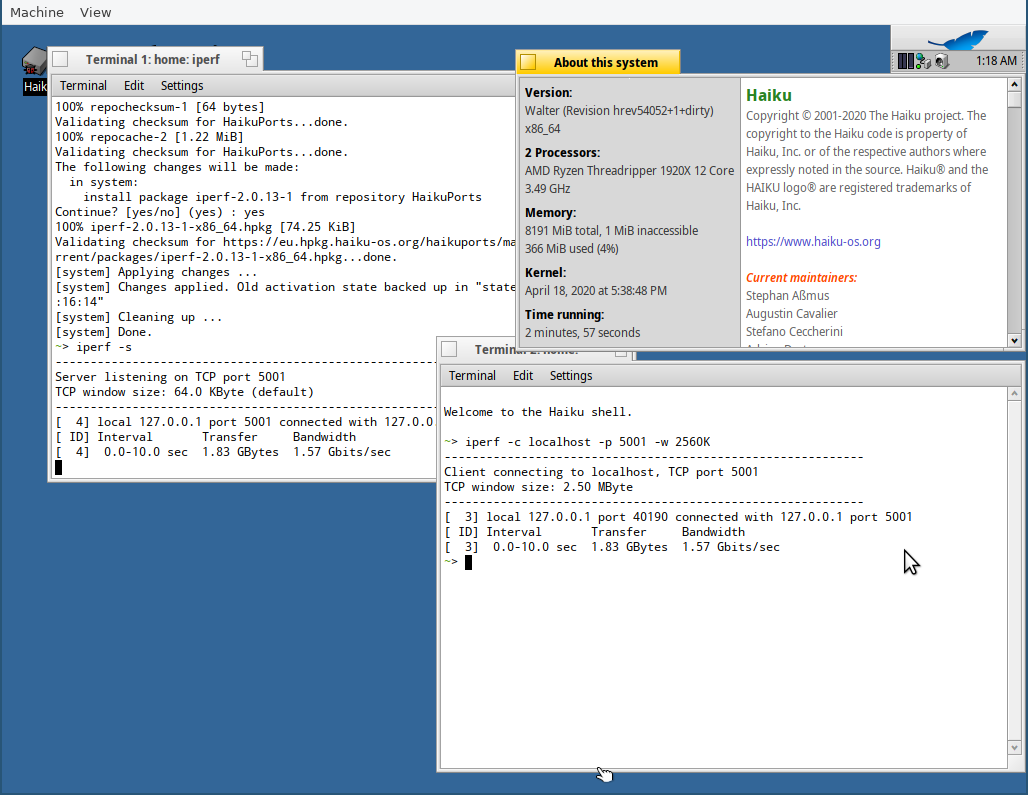
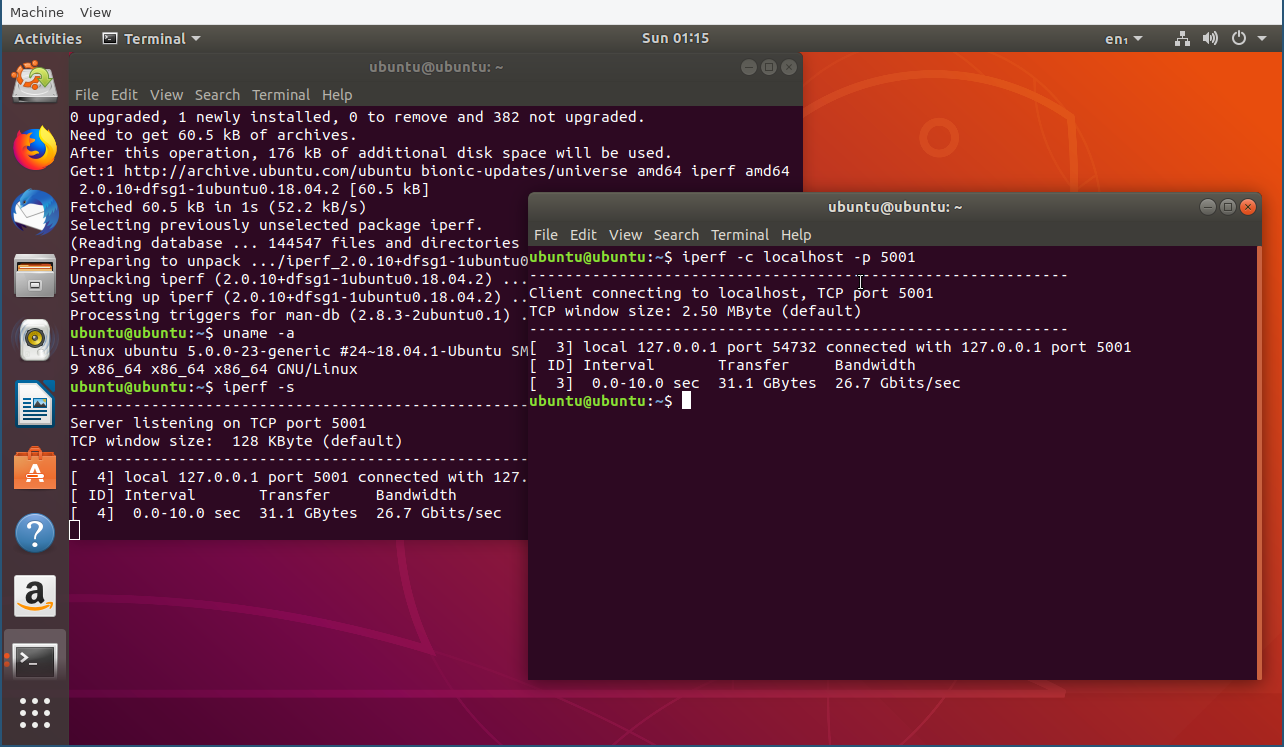
See results here, where throughput increases from 8.9Mbps to 1.57Gbps (still a far cry from what you might expect from Linux, 26.7Gbps in my test): https://imgur.com/gallery/dfmDFG6
diff --git a/src/add-ons/kernel/network/protocols/tcp/TCPEndpoint.cpp b/src/add-ons/kernel/network/protocols/tcp/TCPEndpoint.cpp
index 509f58418be0..6113ca434e63 100644
--- a/src/add-ons/kernel/network/protocols/tcp/TCPEndpoint.cpp
+++ b/src/add-ons/kernel/network/protocols/tcp/TCPEndpoint.cpp
@@ -441,7 +441,7 @@ TCPEndpoint::TCPEndpoint(net_socket* socket)
fReceiveMaxAdvertised(0),
fReceiveWindow(socket->receive.buffer_size),
fReceiveMaxSegmentSize(TCP_DEFAULT_MAX_SEGMENT_SIZE),
- fReceiveQueue(socket->receive.buffer_size),
+ fReceiveQueue(0xffff << 14),
fSmoothedRoundTripTime(0),
fRoundTripVariation(0),
fSendTime(0),
@@ -2257,11 +2257,11 @@ TCPEndpoint::_PrepareSendPath(const sockaddr* peer)
// Compute the window shift we advertise to our peer - if it doesn't support
// this option, this will be reset to 0 (when its SYN is received)
- fReceiveWindowShift = 0;
- while (fReceiveWindowShift < TCP_MAX_WINDOW_SHIFT
- && (0xffffUL << fReceiveWindowShift) < socket->receive.buffer_size) {
- fReceiveWindowShift++;
- }
+ // while (fReceiveWindowShift < TCP_MAX_WINDOW_SHIFT
+ // && (0xffffUL << fReceiveWindowShift) < socket->receive.buffer_size) {
+ // fReceiveWindowShift++;
+ // }
+ fReceiveWindowShift = 14;
return B_OK;
}
Anecdotally this makes a huge improvement in download speeds when updating packages as well, although as noted in #12876 the throughput still slowly decreases over time.
I'm going to start doing a more thorough analysis of this implementation, and try to come up with a solution that still works on systems with very little memory.
Attachments (3)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (8)
by , 5 years ago
| Attachment: | iperf-loopback-throughput-nightly-hrev54052.png added |
|---|
by , 5 years ago
| Attachment: | iperf-loopback-throughput-hrev54052-max-tcp-buffers.png added |
|---|
The same test but after modifying TCPEndpoint to actually support growing the window beyond 65KiB.
by , 5 years ago
| Attachment: | ubuntu-18.04-iperf-throughput-8G-2core-kvm.png added |
|---|
Ubuntu 18.04 in the same VM setup for comparison
comment:1 by , 5 years ago
Wow, thanks for spending time investigating this!
Yeah, we've known the TCP implementation has needed work for a while. There was a GSoC project to work on it which helped, but it really does need investigation like this. Awesome!
comment:2 by , 5 years ago
| Owner: | changed from to |
|---|---|
| Status: | new → assigned |
comment:3 by , 5 years ago
| Component: | - General → Network & Internet/TCP |
|---|
comment:5 by , 8 months ago
Receive window scaling changes merged in hrev57910. Send window isn't resized yet though.
Running iperf to measure throughput over loopback with hrev54052