

Opened 13 years ago
Closed 13 years ago
#8068 closed bug (fixed)
A crash bring up the app_server in gdb when changing the screen resolution
| Reported by: | oco | Owned by: | axeld |
|---|---|---|---|
| Priority: | normal | Milestone: | R1 |
| Component: | Servers/app_server | Version: | R1/Development |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | ||
| Platform: | All |
Description (last modified by )
Reproducible on a fresh install after few change of the screen resolution (less than five) on my laptop (Vesa mode)
I use release hrev42926
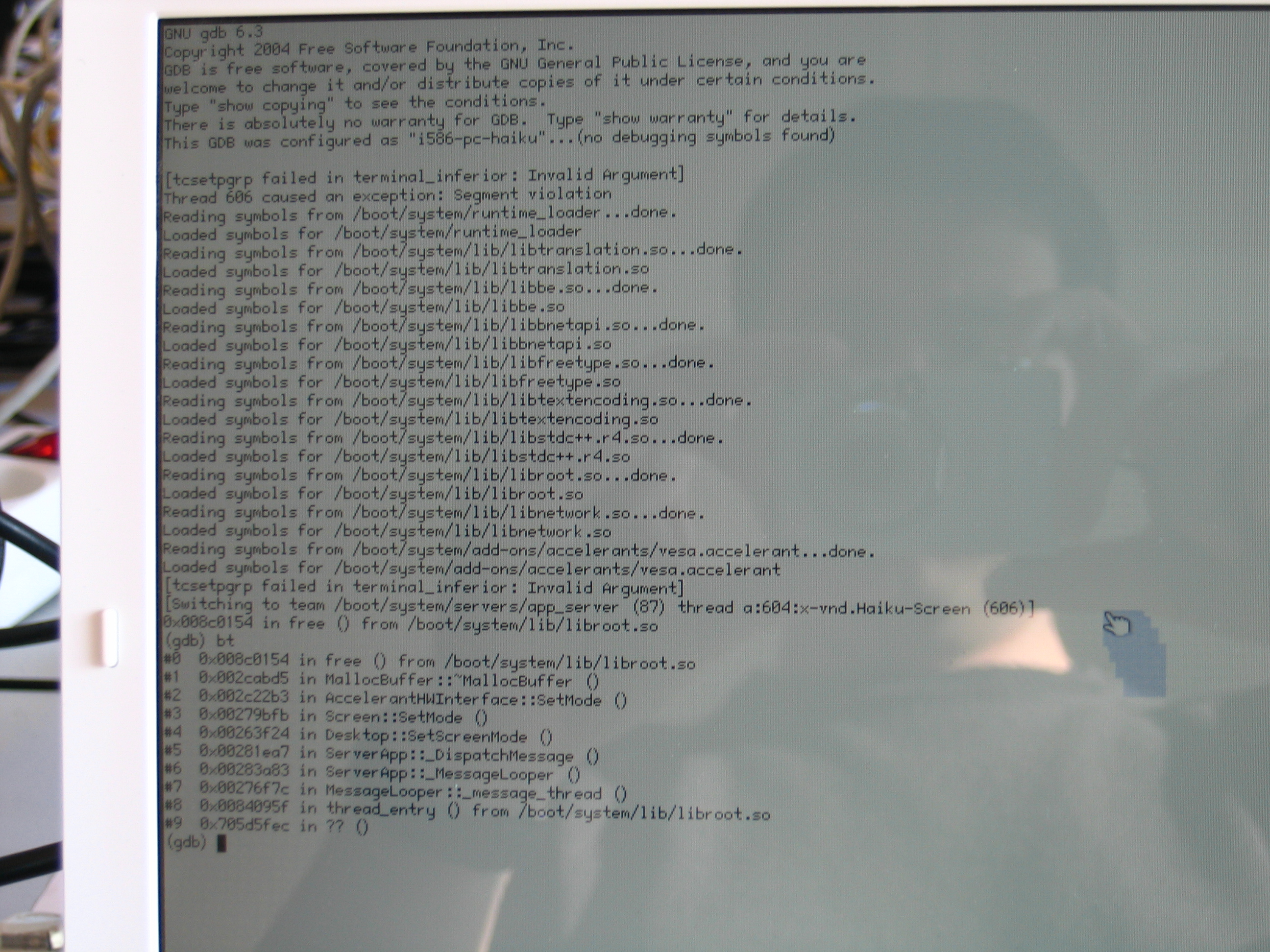
Overview of the backtrace :
free MallocBuffer::MallocBuffer AccelerantHWInterface::SetMode Screen::SetMode Desktop::SetScreenMode ServerApp::_DispatchMessage ServerApp::_MessageLooper ...
See attached photo for detailled backtrace.
Attachments (1)
{kind=link}
{kind=link}
Change History (8)
by , 13 years ago
| Attachment: | IMG_3808.JPG added |
|---|
comment:1 by , 13 years ago
| Version: | R1/alpha3 → R1/Development |
|---|
comment:2 by , 13 years ago
| Description: | modified (diff) |
|---|
follow-up: 4 comment:3 by , 13 years ago
I've built a small script that gets the app_server reliably crashing after a couple of seconds when running normally:
while true do screenmode -q 1280 1024 screenmode -q 1024 768 done
Which will cause continuous mode switches until the crash happens.
Using that I've confirmed that this only happens when both CPUs (it's a dual core machine) are active. Disabling one core prevents the crash from happening. So I'd suspect that the vm86 stuff needs to run on the same CPU that it was set up on and causes side effects leading to the crash otherwise.
follow-up: 5 comment:4 by , 13 years ago
Replying to mmlr:
So I'd suspect that the vm86 stuff needs to run on the same CPU that it was set up on and causes side effects leading to the crash otherwise.
That's probably easy to verify. There's a kernel API to pin a thread to its CPU (thread_pin_to_current_cpu()/thread_unpin_from_current_cpu()).
comment:5 by , 13 years ago
Replying to bonefish:
Replying to mmlr:
So I'd suspect that the vm86 stuff needs to run on the same CPU that it was set up on and causes side effects leading to the crash otherwise.
That's probably easy to verify. There's a kernel API to pin a thread to its CPU (
thread_pin_to_current_cpu()/thread_unpin_from_current_cpu()).
Yes, I realize, and it does work as a workaround as well. I'd like to figure out what actually happens though. The virtual 8086 mode should be task specific and switching between threads should just store/restore the state as with any other thread (the CPU isn't specifically set up, just an appropriate iframe is constructed). It obviously works on the same CPU when being rescheduled (forcing that by inserting some pauses into the code path) without any side effects, so I don't yet really see why it'd fail running on a different CPU.
comment:6 by , 13 years ago
I'm unfamiliar with that code. I would probably examine the crash situation a bit more. If, as you say, all libroot functions seem to crash, something may have happened to the respective area or just, lower level, to the page table(s). I usually add a panic() in vm_page_fault() in such cases, so it is easier to examine and it is very unlikely that something else happened in between that might have changed the situation.
Good luck hunting, anyway! :-)
comment:7 by , 13 years ago
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
Fixed in hrev43321.
The libroot calls actually crashed in _errnop() where the clobbered TLS was used. Since TLS is re-setup on reschedule (more specifically on context switch) it also explains why I didn't see the crash when introducing enough pauses to always trigger a reschedule before returning from the vm86 code (even with SMP). Obviously staying on the same CPU worked as well as the restored TLS value happened to be the right one.
I've seen this on another machine and it really is easily reproducible. I've added enough debug output to rule out that it comes from the place the stack trace would suggest. The buffer handling is fine, the free call is merely a victim of what's going on. My debug efforts showed that everything works as expected up to and including the call of fAccSetDisplayMode in AccelerantHWInterface::SetMode(). After that it seems like any access to libroot functions will fault (including the printf I added for debugging). I've tried to narrow it further down, but I can only suspect a side effect of the vm86 code to be the problem here. Since the code doesn't run through to update of the KDL framebuffer with the added debug output I wasn't able to gather more info just yet. I'll try to investigate further, but I don't really have a good overview of what should or should not happen within the vm86 code.