

#8430 closed bug (not reproducible)
[kernel] mplayer segfaults in a loop
| Reported by: | diver | Owned by: | bonefish |
|---|---|---|---|
| Priority: | normal | Milestone: | |
| Component: | System/Kernel | Version: | R1/Development |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | ||
| Platform: | All |
Description
This is hrev43901 gcc2hybrid. mplayer binary (8MB)
After running mplayer smb://share/video.avi (it doesn't matter if video.avi actually exists or not!) mplayer crashes. After that
GUI and cursor becomes extremely sluggish and unresponsive.
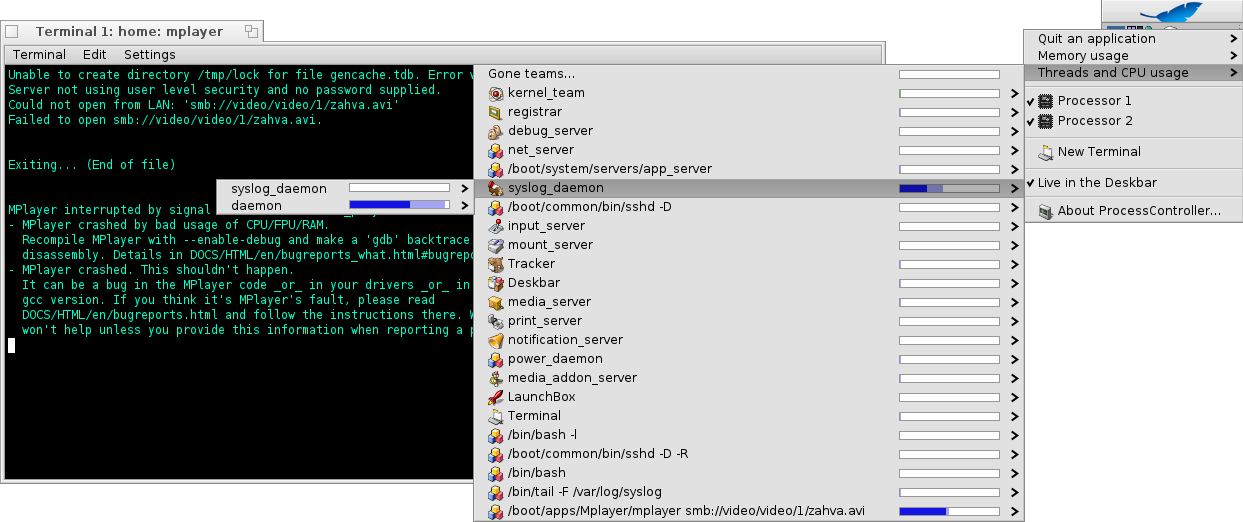
ProcessController shows that mplayer uses 50% of cpu, the other 50% is used by syslog_daemon.
I had changed it's priority from normal ![10] to lowest active ![1] and GUI with cursor became normal again.
I can see in Tracker that syslog gets constantly overwritten. The following message repeats zillion times in syslog:
vm_soft_fault: va 0x0 not covered by area in address space
vm_page_fault: vm_soft_fault returned error 'Bad address' on fault at 0x0, ip 0x0, write 0, user 1, thread 0x313
vm_page_fault: thread "mplayer" (787) in team "mplayer" (787) tried to read address 0x0, ip 0x0 ("???" +0x0)
Then I debugged mplayer thread from ProcessController:
[...] [Switching to team /boot/apps/Mplayer/mplayer smb://share/video.avi (299) thread mplayer (299)] 0x00000000 in ?? () (gdb) bt #0 0x00000000 in ?? () #1 0x03cd09ee in ucnv_close () from /boot/system/lib/gcc4/libicuuc.so.48.1.1 #2 0x03de1e67 in BPrivate::Libroot::ICUThreadLocalStorageValue::~ICUThreadLocalStorageValue () from /boot/system/lib/gcc4/libroot-addon-icu.so #3 0x03ddf0e9 in BPrivate::Libroot::ICULocaleBackend::_DestroyThreadLocalStorageValue () from /boot/system/lib/gcc4/libroot-addon-icu.so #4 0x018bb892 in __pthread_key_call_destructors () from /boot/system/lib/gcc4/libroot.so #5 0x018bad18 in __pthread_destroy_thread () from /boot/system/lib/gcc4/libroot.so #6 0x018ae222 in _thread_do_exit_work () from /boot/system/lib/gcc4/libroot.so #7 0x0190f0b0 in exit () from /boot/system/lib/gcc4/libroot.so #8 0x0030ab39 in rm_osd_msg () [...] #14 0x00b81e4f in _tevent_req_notify_callback () [...] #30 0x01000000 in ff_codec_caf_tags () [...] #43 0x00eabcd1 in tdb_allocate () #44 0x03de1e67 in BPrivate::Libroot::ICUThreadLocalStorageValue::~ICUThreadLocalStorageValue () from /boot/system/lib/gcc4/libroot-addon-icu.so #45 0x03ddf0e9 in BPrivate::Libroot::ICULocaleBackend::_DestroyThreadLocalStorageValue () from /boot/system/lib/gcc4/libroot-addon-icu.so #46 0x018bb892 in __pthread_key_call_destructors () from /boot/system/lib/gcc4/libroot.so #47 0x018bad18 in __pthread_destroy_thread () from /boot/system/lib/gcc4/libroot.so #48 0x018ae222 in _thread_do_exit_work () from /boot/system/lib/gcc4/libroot.so #49 0x0190f0b0 in exit () from /boot/system/lib/gcc4/libroot.so #50 0x0030c0a2 in exit_player_with_rc () #51 0x012be558 in ?? () (gdb)
mplayer binary is from 20.05.2011.
Some pointers from DeadYak:
DeadYak looks like it's trapping segfaults DeadYak that might explain the issue, if it's doing that in a loop it's going to be nailing the VM like crazy DeadYak file that as a kernel bug and assign to bonefish please...including screenshots DeadYak looks like mplayer installs a segfault handler and then something else goes wrong DeadYak possibly during thread cleanup DeadYak but right now it looks more like a VM bug DeadYak or a combination of a design issue in the VM + bad behavior somewhere DeadYak also, if that behavior doesn't happen in older revs, it'd be interesting to know when it started DeadYak I suspect this isn't a new problem though
Attachments (1)
{kind=link}
{kind=link}
Change History (17)
by , 13 years ago
| Attachment: | mplayer.png added |
|---|
comment:1 by , 13 years ago
comment:2 by , 13 years ago
That begs a question: how old is that mplayer binary? If it was built on Haiku, it would have needed to be rebuilt post-43507 because this changes breaks compatibility.
comment:3 by , 13 years ago
Sure, mplayer binary is from 20.05.2011. But shouldn't Haiku behave more gracefully?
comment:4 by , 13 years ago
That might be difficult depending on what kind of signal handlers mplayer puts in place. Under normal circumstances this would simply crash on exit, but it could be that something else strange is going on here. I'm not sure what order the images get unmapped in again, so it could be some strange interaction like the image the signal handler is in already being unmapped at this point in at-exit cleanups. Ingo might have a better clue.
comment:5 by , 13 years ago
I don't really have anything insightful to add. I think the analysis so far is correct. Due to some problem (the incompatible compiler changes?) mplayer crashes on exit. It probably has installed a SIGSEGV handler which is why it isn't caught by the debug server, but enters its signal handler. No clue what this handler does. Normally they just print some error message and call _exit(). Due to the stack trace being incomplete and probably not fully correct anyway (IIRC I never implemented signal handler support in gdb), it's hard to say what happens exactly.
Maybe the SIGSEGV handler actually (directly or indirectly) calls exit() which crashes again, thus causing an infinite recursion. This should eventually overflow the stack, causing the setup of the signal handler environment to fail. ATM we just ignore that error (which should be fixed). So I guess at that point the kernel would just return to the previous point of execution and immediately trigger the page fault again. The syslog message speaks against this theory, though. On the other hand, the stack might not have overflown at this point yet. If serial debug output is enabled things might be slow enough for that to take quite a while. A kernel stack trace might provide more insights.
comment:6 by , 13 years ago
I'm unable to reproduce this on my end, it does indeed crash, but then exits normally. Trapping it in the debugger instead of letting it terminate gives a more or less expected backtrace:
#0 0xffff0114 in ?? () #1 0x018aa7f0 in debugger () from /boot/system/lib/gcc4/libroot.so #2 0x018b4b3e in __assert_fail () from /boot/system/lib/gcc4/libroot.so #3 0x01920fd2 in BPrivate::hoardHeap::freeBlock () from /boot/system/lib/gcc4/libroot.so #4 0x01921d1d in BPrivate::processHeap::free () from /boot/system/lib/gcc4/libroot.so #5 0x01922a9e in free () from /boot/system/lib/gcc4/libroot.so #6 0x03cf18c9 in uprv_free () from /boot/system/lib/gcc4/libicuuc.so.48.1.1 #7 0x03cfba9a in ucnv_close () from /boot/system/lib/gcc4/libicuuc.so.48.1.1 #8 0x03e0ce67 in BPrivate::Libroot::ICUThreadLocalStorageValue::~ICUThreadLocalStorageValue () from /boot/system/lib/gcc4/libroot-addon-icu.so #9 0x03e0a0e9 in BPrivate::Libroot::ICULocaleBackend::_DestroyThreadLocalStorageValue () from /boot/system/lib/gcc4/libroot-addon-icu.so #10 0x018bb892 in __pthread_key_call_destructors () from /boot/system/lib/gcc4/libroot.so #11 0x018bad18 in __pthread_destroy_thread () from /boot/system/lib/gcc4/libroot.so #12 0x018ae222 in _thread_do_exit_work () from /boot/system/lib/gcc4/libroot.so #13 0x0190f0b0 in exit () from /boot/system/lib/gcc4/libroot.so #14 0x0030c0a2 in exit_player_with_rc () #15 0x012be558 in ?? ()
Perhaps it's in some way triggered by memory usage constraints? I do have 8GiB here.
comment:7 by , 13 years ago
I stand corrected, feeding it different SMB URI which actually led to a valid machine reproduced the issue here. KDL-based backtrace is as follows:
stack trace for thread 453 "mplayer"
kernel stack: 0x82666000 to 0x8266a000
user stack: 0x7efef000 to 0x7ffef000
frame caller <image>:function + offset
0 82669c48 (+ 48) 8006c31a <kernel_x86> process_pending_ici(int32: 3) + 0x0106
1 82669c78 (+ 48) 8006c3d5 <kernel_x86>:smp_intercpu_int_handler + 0x0015
2 82669ca8 (+ 32) 801277ac <kernel_x86>:i386_ici_interrupt(NULL) + 0x0014
3 82669cc8 (+ 48) 8005880a <kernel_x86>:int_io_interrupt_handler + 0x005e
4 82669cf8 (+ 64) 80125bcd <kernel_x86> hardware_interrupt(iframe*: 0x82669d44) + 0x006d
5 82669d38 (+ 12) 8012a88d <kernel_x86>:int_bottom + 0x003d
kernel iframe at 0x82669d44 (end = 0x8669d94)
eax 0x1 ebx 0x8019cf08 ecx 0x0 edx 0x8019cf08
esi 0x82669df8 edi 0x80183dc0 ebp 0x82669dcc esp 0x82669d78
eip 0x8009298c eflags 0x213202
vector: 0xfd, error code: 0x0
6 82669d44 (+ 136) 8009298c <kernel_x86> dprintf_args(0x80183dc0 "vm_soft_fault: va 0x%lx not covered by area in address space", 0x82669df8, "", true) + 0x00fc
7 82669dcc (+ 32) 8009346f <kernel_x86>:dprintf + 0x0037
8 82669dec (+ 192) 80107ddf <kernel_x86> vm_soft_fault(VMAddressSpace*: 0xcdd17a88, uint32: 0x0 (0), false, true, vm_page*: NULL, VMAreaWiredRange*: NULL) + 0x00fb
9 82669eac (+ 160) 801073b7 <kernel_x86>:vm_page_fault + 0x009f
10 82669f4c (+ 80) 80125b4a <kernel_x86> page_fault_exception(iframe*: 0x82669fa8) + 0x0176
11 82669f9c (+ 12) 8012a90b <kernel_x86>:int_bottom_user + 0x006f
user iframe at 0x82669fa8 (end = 0x8266a000)
eax 0x1803d050 ebx 0x3dfe58c ecx 0x7ffed1a4 edx 0x0
esi 0x0 edi 0x7ffed1c0 ebp 0x7ffed1dc esp 0x82669fdc
eip 0x0 eflags 0x213283 user esp 0x7ffed150
vector: 0xe, error code: 0x4
12 82669fa8 (+ 0) 00000000
13 7ffed1dc (+ 32) 03e0ce67 <libroot-addon-icu.so> BPrivate::libroot::ICUThreadLocalStorageValue::~ICUThreadLocalStorageValue() + 0x0025
14 7ffed1fc (+ 32) 03e0a0e9 <libroot-addon-icu.so> BPrivate::libroot::ICULocaleBackend<0x180a1820>::_DestroyThreadLocalStorageValue(void*: 0x7ffed248) + 0x0021
15 7ffed21c (+ 48) 018bb892 <libroot.so>:__pthread_key_call_destructor + 0x005e
16 7ffed24c (+ 32) 018bad18 <libroot.so>:__pthread_destroy_thread + 0x0038
17 7ffed26c (+ 32) 018ae222 <libroot.so>:_thread_do_exit_work + 0x005d
18 7ffed28c (+ 16) 0190f0b0 <libroot.so>:exit + 0x0018
19 7ffed29c (+ 624) 0030ab39 <mplayer>:rm_osd_msg (nearest) + 0x1319
Also note, confirmed that mplayer indeed installs a signal handler, as it displays a console error message indicating that it was interrupted by signal 11 in module: exit_player.
comment:8 by , 13 years ago
If it matters, the thread in question can be terminated via ProcessController when it's trapped in this state and exits normally then.
comment:9 by , 13 years ago
Custom signal handlers don't seem to be coming into play for the infinite loop at least ; a kernel with signal tracing enabled isn't showing any extra activity to go with the page fault/soft fault messages.
comment:10 by , 13 years ago
I have no idea about the infinite loop, but the trigger of the segfault has been fixed in hrev43933.
Leaving this open for anyone wanting to look at why the loop occurs ...
comment:11 by , 12 years ago
What about syslog_daemon? Does it really need to run at normal priority or we can lower it to lowest active?
comment:12 by , 7 years ago
| Milestone: | R1 → Unscheduled |
|---|
comment:13 by , 6 years ago
comment:14 by , 6 years ago
I can't reproduce it with current version of mplayer and I don't have the older binary it seems. Let's close this one then?
comment:15 by , 6 years ago
| Resolution: | → not reproducible |
|---|---|
| Status: | new → closed |
comment:16 by , 5 years ago
| Milestone: | Unscheduled |
|---|
Remove milestone for tickets with status = closed and resolution != fixed
Using binary search I've found out that this behavior started from hrev43507.