

#8684 closed bug (fixed)
Unhandled page fault panic at boot with rtl81xx driver
| Reported by: | xyzzy | Owned by: | mmlr |
|---|---|---|---|
| Priority: | critical | Milestone: | R1/beta1 |
| Component: | System/Kernel | Version: | R1/Development |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | #9139, #9153 | |
| Platform: | x86 |
Description
Getting a page fault during boot on both my test machine (RTL8101E/RTL8102E) and QEMU with an RTL8139 enabled. GCC4 build, hrev44285 (latest).
vm_soft_fault: va 0x0 not covered by area in address space
vm_page_fault: vm_soft_fault returned error 'Bad address' on fault at 0x0, ip 0x82436c9d, write 0, user 0, thread 0x3b
PANIC: vm_page_fault: unhandled page fault in kernel space at 0x0, ip 0x82436c9d
Welcome to Kernel Debugging Land...
Thread 59 "net_server" running on CPU 0
stack trace for thread 59 "net_server"
kernel stack: 0x81da4000 to 0x81da8000
user stack: 0x7efef000 to 0x7ffef000
frame caller <image>:function + offset
0 81da77ec (+ 32) 8010402f <kernel_x86>:arch_debug_stack_trace + 0x000f
1 81da780c (+ 16) 800824be <kernel_x86> stack_trace_trampoline(void*: NULL) + 0x000b
2 81da781c (+ 12) 80108bd6 <kernel_x86>:arch_debug_call_with_fault_handler + 0x001b
3 81da7828 (+ 48) 80082f02 <kernel_x86>:debug_call_with_fault_handler + 0x0050
4 81da7858 (+ 80) 80083b8f <kernel_x86> kernel_debugger_loop(char const*: 0x0 "<NULL>", char const*: 0x8017bb60 "�xځ", char*: 0x81da78e8, int32: -2146943520) + 0x0210
5 81da78a8 (+ 64) 80083e0b <kernel_x86> kernel_debugger_internal(char const*: 0x0 "<NULL>", char const*: 0x80000000 "ELF", char*: 0x81da7908, int32: -2146942914) + 0x0108
6 81da78e8 (+ 32) 80084052 <kernel_x86>:panic + 0x0023
7 81da7908 (+ 160) 800eac00 <kernel_x86>:vm_page_fault + 0x0129
8 81da79a8 (+ 96) 80104e78 <kernel_x86> page_fault_exception(iframe*: 0x81da7a14) + 0x0165
9 81da7a08 (+ 12) 80109b8d <kernel_x86>:int_bottom + 0x003d
kernel iframe at 0x81da7a14 (end = 0x81da7a64)
eax 0x0 ebx 0x824a4e68 ecx 0x3 edx 0x0
esi 0x0 edi 0x0 ebp 0x81da7a84 esp 0x81da7a48
eip 0x82436c9d eflags 0x13246
vector: 0xe, error code: 0x0
10 81da7a14 (+ 112) 82436c9d </boot/system/add-ons/kernel/bus_managers/pci> PCI<0x0>::FindDevice(int32: 0, uint8: 0x0 (0), uint8: 0x3 (3), uint8: 0x0 (0)) + 0x002b
11 81da7a84 (+ 96) 82438fd1 </boot/system/add-ons/kernel/bus_managers/pci> pci_get_msi_count(uint8: 0x0 (0), uint8: 0x3 (3), uint8: 0x0 (0)) + 0x0079
12 81da7ae4 (+ 32) 81acde7d </boot/system/add-ons/kernel/drivers/dev/net/rtl81xx>:pci_msi_count + 0x004b
13 81da7b04 (+ 96) 81acaea6 </boot/system/add-ons/kernel/drivers/dev/net/rtl81xx>:re_attach + 0x015f
14 81da7b64 (+ 32) 81aceeed </boot/system/add-ons/kernel/drivers/dev/net/rtl81xx>:device_attach + 0x002a
15 81da7b84 (+ 80) 81ad0029 </boot/system/add-ons/kernel/drivers/dev/net/rtl81xx>:_fbsd_init_drivers + 0x013e
16 81da7bd4 (+ 48) 81accdb4 </boot/system/add-ons/kernel/drivers/dev/net/rtl81xx>:__haiku_handle_fbsd_drivers_list + 0x002c
17 81da7c04 (+ 32) 81accdfa </boot/system/add-ons/kernel/drivers/dev/net/rtl81xx>:init_driver + 0x001e
18 81da7c24 (+ 48) 800a1efb <kernel_x86> load_driver(_GLOBAL__N_1::legacy_driver*: 0xcdb6f000, legacy_driver: 0x0, 0xffffffff) + 0x0109
19 81da7c54 (+ 144) 800a2789 <kernel_x86> add_driver(char const*: 0xcd8599c0 "����", int32: -2116387308) + 0x01ce
20 81da7ce4 (+ 16) 800a2bb3 <kernel_x86>:legacy_driver_add + 0x0013
21 81da7cf4 (+ 320) 800a3698 <kernel_x86>:legacy_driver_probe + 0x0732
22 81da7e34 (+ 80) 8009f033 <kernel_x86> scan_for_drivers_if_needed(devfs_vnode*: 0x401) + 0x00e5
23 81da7e84 (+ 48) 8009f9c5 <kernel_x86> devfs_open_dir(fs_volume*: 0x829a84a0, fs_vnode*: 0xcd8232a8, void**: 0x81da7ed8) + 0x004c
24 81da7eb4 (+ 64) 800c3e8a <kernel_x86> open_dir_vnode(vnode*: NULL, false) + 0x002a
25 81da7ef4 (+ 32) 800c8f42 <kernel_x86> dir_open(int32: -845023976, char*: 0x401, false) + 0x0034
26 81da7f14 (+ 48) 800cdf33 <kernel_x86>:_user_open_dir + 0x00a4
27 81da7f44 (+ 100) 80109e40 <kernel_x86>:handle_syscall + 0x00cd
user iframe at 0x81da7fa8 (end = 0x81da8000)
eax 0x69 ebx 0x4ab3d0 ecx 0x7ffee62c edx 0xffff0114
esi 0x215316 edi 0x0 ebp 0x7ffee658 esp 0x81da7fdc
eip 0xffff0114 eflags 0x203212 user esp 0x7ffee62c
vector: 0x63, error code: 0x0
28 81da7fa8 (+ 0) ffff0114 <commpage>:commpage_syscall + 0x0004
29 7ffee658 (+ 48) 003d3e6b <libbe.so> BDirectory::BDirectory(char const*: 0x7ffee810 "��J") + 0x004d
30 7ffee688 (+ 576) 0020d075 <_APP_> NetServer<0x7ffeed24>::_ConfigureDevices(char const*: 0x215316 "/dev/net", BMessage*: NULL) + 0x002d
31 7ffee8c8 (+ 336) 0020d48f <_APP_> NetServer<0x7ffeed24>::_BringUpInterfaces() + 0x0223
32 7ffeea18 (+ 96) 0020d54c <_APP_> NetServer<0x7ffeed24>::ReadyToRun() + 0x0046
33 7ffeea78 (+ 544) 002eee67 <libbe.so> BApplication<0x7ffeed24>::DispatchMessage(BMessage*: 0x1801ab40, BHandler*: 0x7ffeed24) + 0x02b7
34 7ffeec98 (+ 80) 002f7ce0 <libbe.so> BLooper<0x7ffeed24>::task_looper() + 0x01a2
35 7ffeece8 (+ 32) 002ee01a <libbe.so> BApplication<0x7ffeed24>::Run() + 0x005e
36 7ffeed08 (+ 608) 0020bfe2 <_APP_>:main + 0x0076
37 7ffeef68 (+ 52) 00209fe9 <_APP_>:_start + 0x0051
38 7ffeef9c (+ 64) 00105f9b </boot/system/runtime_loader@0x00100000>:unknown + 0x5f9b
39 7ffeefdc (+ 0) 7ffeefec 1954:net_server_59_stack@0x7efef000 + 0xffffec
kdebug>
Attachments (1)
{kind=link}
{kind=link}
Change History (25)
comment:1 by , 12 years ago
comment:2 by , 12 years ago
Also only happens booting an anyboot image. A raw HD image appears to work fine.
comment:3 by , 12 years ago
| Version: | R1/alpha3 → R1/Development |
|---|
comment:4 by , 12 years ago
Just tried gcc2 and gcc4 anyboot images and so far I couldn't reproduce it.
comment:5 by , 12 years ago
Yes, it's strange, I'm only getting it on builds I've done (I checked, it happens with a GCC2 build as well). I wonder if there could be anything broken on my host system (Fedora 17) that means the anyboot image is being generated incorrectly?
comment:6 by , 12 years ago
My desktop machine is using the same driver, and I have Fedora 17 on my laptop -- I'll give it a try in the next few days unless I forget :-)
comment:7 by , 12 years ago
OK, so it's happening only on CD boots (anyboot or ISO image).
What I've found is that it's seeing that bus_managers/pci/x86/v1 is unused in module_init_post_boot_device, but the PCI module image is not unloaded. Then when the FreeBSD driver tries to get the x86 PCI module, a new copy of the PCI module image gets loaded, and pci_init doesn't get called on that copy so gPCI in it will be NULL, hence the NULL access.
What's strange is why this isn't happening everywhere...
follow-up: 9 comment:8 by , 12 years ago
| Blocking: | 9139 added |
|---|
comment:9 by , 12 years ago
comment:11 by , 12 years ago
| Blocking: | 9153 removed |
|---|
(In #9153) Ok: i see https://dev.haiku-os.org/ticket/9139#comment:10 sorry for duplicate. Is very sad that an official release has this bug!
comment:12 by , 12 years ago
| Blocking: | 9153 added |
|---|
(In #9153) Probably a bug due to the recent Trac updates.
follow-up: 16 comment:13 by , 12 years ago
Seeing this issue on at least one of my machines booting with ISO or Anyboot.
So far, of the two machines I've tested, one boots (with ipro1000 chipset), one fails (with RTL8111/8168B chipset).
I'll attempt to get a serial log from the failing one shortly in the event that it helps track it down. I can pull the syslog from the working machine if that's of any use?
comment:14 by , 12 years ago
| Component: | Drivers/Network/rtl81xx → System/Kernel |
|---|---|
| Owner: | changed from to |
| Priority: | normal → critical |
Just to clarify: This happens only when MSIs are supported by the driver in general, the driver tries to use them for the given hardware and MSIs are enabled. For MSIs to be enabled, the local APIC is required, so disabling it in the safemode settings works around the problem (as has been mentioned earlier). Since the local APIC is required for inter processor interrupts, disabling them also disables SMP. It also obviously isn't triggered if the system doesn't have a local APIC at all. Hence it is possible that it cannot be reproduced on some systems. Pretty much every modern system does have local APICs (as needed for APIC timers, IO-APICs and SMP) and most cuerrent network hardware supports MSIs and many of the drivers for the most common hardware do too. Overall this makes it pretty severe.
comment:15 by , 12 years ago
| Milestone: | R1 → R1/beta1 |
|---|
If it was still an option, I'd personally declare this an alpha4 blocker, but...
I'm thinking that if this can be resolved in a very short time, I would even release an Alpha 4.1 at this point.
comment:16 by , 12 years ago
Replying to umccullough:
So far, of the two machines I've tested, one boots (with ipro1000 chipset), one fails (with RTL8111/8168B chipset).
The one that fails is a Core 2 Duo, while the (now 2) succeeding are single-core pentium 4 machines.
So, the SMP support may certainly be contributing to the cause in my case.
comment:17 by , 12 years ago
Continued testing yields the follwing results for me (all with anyboot/iso CD):
single-core pentium 4 with ipro100 boots single-core pentium 4 with ipro1000 boots dual-core core2duo with rtl8168 fails dual-core corei5 with ipro1000 fails dual-core amd x2 with nforce boots dual-core atom330 with rtl8102 fails
That's about all I have at my immediate disposal to test with... unless I fix a couple machines (missing PSUs, no RAM, etc.) sitting around my office here.
comment:18 by , 12 years ago
Testing of R1A4 anyboot image burned to CD:
- dual-core pentium 4 with broadcom570x boots
- dual-core AMD A4 laptop with rtl8188CE wifi / RTL8101E/RTL8102E Eth boots
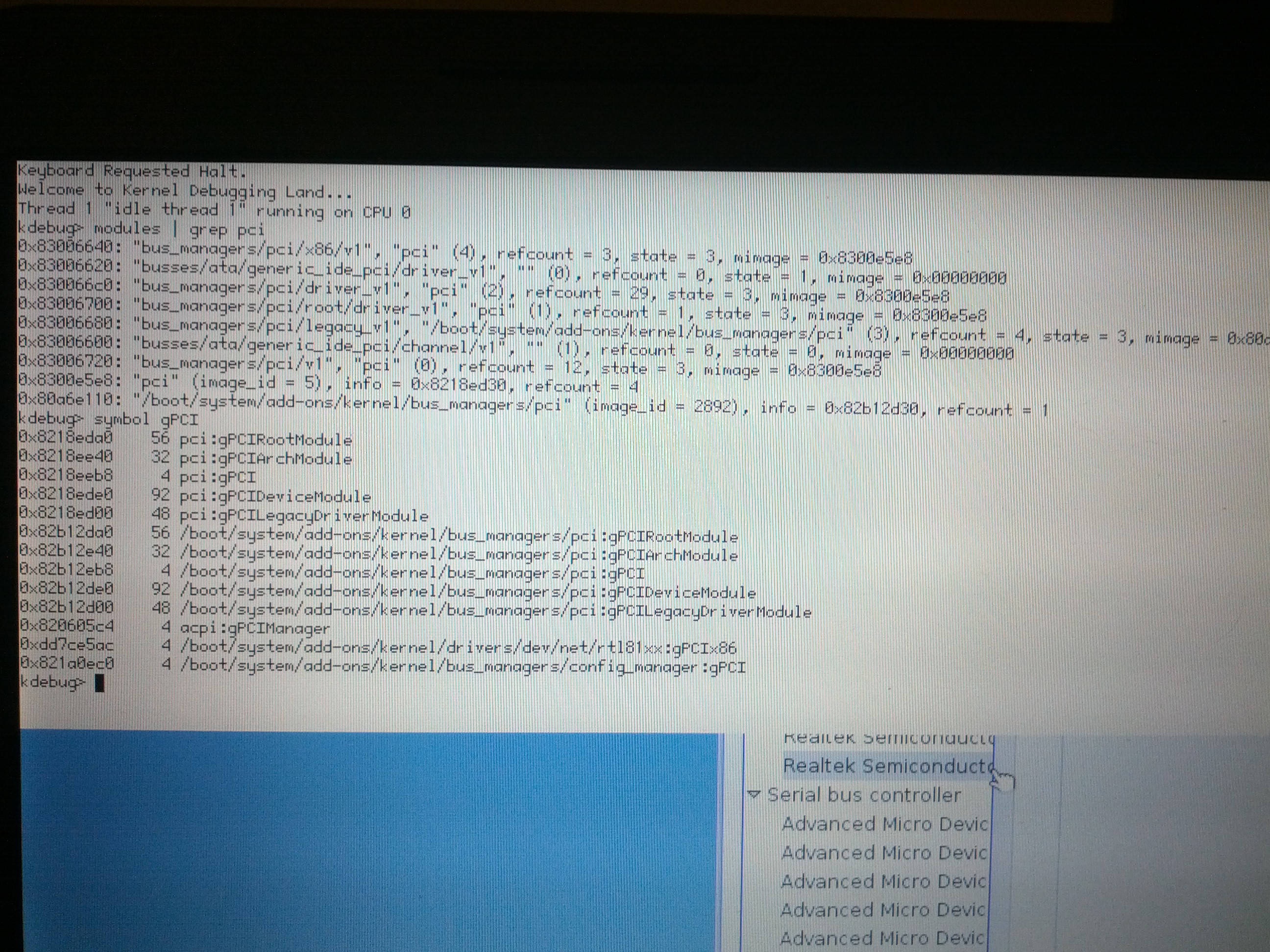
- mmlr pointed out, this machine has a duplicated pci bus manager.. but seems stable.
- screenshot coming soon
by , 12 years ago
| Attachment: | IMG_20121113_220340.jpg added |
|---|
screenshot as per mmlr of duplicate pci_bus manager
follow-up: 20 comment:19 by , 12 years ago
What seems to happen is that the normalization of the preloaded image(s) (at least in this case "pci") to the full path on the boot volume does not take place or doesn't yield the correct result. Additionally, as mentioned above, the pci/x86 (sub-)module isn't used in that stage and its module image is cleared to NULL. When the pci/x86 module is eventually re-used again by the network driver, the module image is looked up by path. Since the normalization of the preloaded image didn't work, the PCI module is still just "pci" instead of "/boot/system/add-ons/kernel/bus_managers/pci" and the module code moves on and reloads a new instance of the PCI module image from that path.
It doesn't re-initialize the PCI module itself, as that is still around and in use (just with a non-normalized image path). So the problem is that the PCI module image isn't matched with the original (preloaded) image that is still around. It's not an option to simply initialize a second PCI module, as that would obviously clash for control over the hardware.
Now to why this doesn't always crash:
- Right now the pci/x86 module only provides MSI support, hence it is only ever loaded by drivers that want to use MSIs. So if there's no driver using that, no crash.
- The MSI support is checked first thing before doing anything, so even if a driver tries to use MSIs, but MSIs aren't available (missing local APIC, missing MSI support) the problematic gPCI pointer isn't used, so no crash.
- If there is an active user of the pci/x86 when the normalization/clearing happens, then the pci/x86 module doesn't have its module image cleared, hence later on it won't try to reload the image and therefore no crash. Since OHCI uses MSIs now, the likelihood of this being the case, especially on AMD hardware, is rather high, accounting for quite a few systems where the crash can't be reproduced.
The problem itself, that the module path isn't properly normalized should still be present on all CD boots of an r1alpha4 release image. This is evidenced by the kernel debugger output in the attachment above. It just doesn't trigger a crash as long as the pci/x86 module isn't used.
As to why the normalization doesn't work as intended: I have no idea. I tried to reproduce it with self built images and debug output, but I can't seem to produce a situation where this is triggered. All in all the code looks like it should work.
Testing by various people narrowed it down to be the case only for CD boots. It doesn't seem to matter what filesystem is used by the boot volume (i.e. it is triggered for both the normal ISO, as well as for an anyboot image booted from CD). Therefore it seems that the floppy boot image used to boot via El-Torito makes all the difference (this one is used by both the ISO and the anyboot image when burned to CD). If I build an ISO locally everything works fine. If I replace the floppy boot image of my working ISO with the floppy boot image copied off an r1alpha4 release ISO, I can reproduce the failed normalization and eventually the crash (I use kvm to reproduce).
That's what the investigation so far produced. As far as I can tell the floppy boot image as a source really shouldn't matter at the point the normalization happens, since it pretty much just uses find_directory to get to the system/add-ons dir, then appends "kernel/boot" to end up in the boot module symlinks and then adds the image name "pci" (that path then points to the boot module symlink which is normalized to the actual absolute filesystem path). I've cross checked that the PCI module as well as the kernel that is in the boot floppy image are the exact same as the ones on the ISO itself, which indicates that they should be fine.
Since I can't seem to produce a problematic floppy boot image on linux over here, I could only imagine that the build platform used to create the release ISO somehow influences the process. The TAR tool in use on FreeBSD might be the difference, but that's a long shot at best.
follow-up: 21 comment:20 by , 12 years ago
Replying to mmlr:
Since I can't seem to produce a problematic floppy boot image on linux over here, I could only imagine that the build platform used to create the release ISO somehow influences the process. The TAR tool in use on FreeBSD might be the difference, but that's a long shot at best.
Perhaps it is something to do with the order in which the add-ons get loaded from the image, which could be different with different versions of tar or different filesystems on the build machine?
FWIW, I was getting this bug when I was using Fedora 17 as my build system, though IIRC it went away after a while and it never happened when I was building on OS X.
comment:21 by , 12 years ago
| Owner: | changed from to |
|---|---|
| Status: | new → in-progress |
Replying to xyzzy:
Perhaps it is something to do with the order in which the add-ons get loaded from the image, which could be different with different versions of tar or different filesystems on the build machine?
Yes I've figured it out. It is a bug in the khash code. It skips elements in some cases and therefore, as you said, the order in which they are added to the TAR and eventually added to the module list.
I'm working on a fix.
comment:22 by , 12 years ago
Woot! Thanks mmlr.
Ryan and myself discussed this and we've decided to re-release R1A4 to correct this issue (as well as the networking deadlock issue)
Thanks for finding the problem so quickly!
comment:23 by , 12 years ago
| Resolution: | → fixed |
|---|---|
| Status: | in-progress → closed |
Fixed in hrev44835 and hrevr1alpha4-44700 respectively.
comment:24 by , 12 years ago
For completeness this is actually a duplicate of #5936. That one was closed with the assumption of stale objects, due to the randomness and rareness of this.
Strangely, I'm not getting this with the official nightlies. I completely rebuilt everything locally including my cross tools, still happens with my build.