

Attachments (2)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (18)
by , 11 years ago
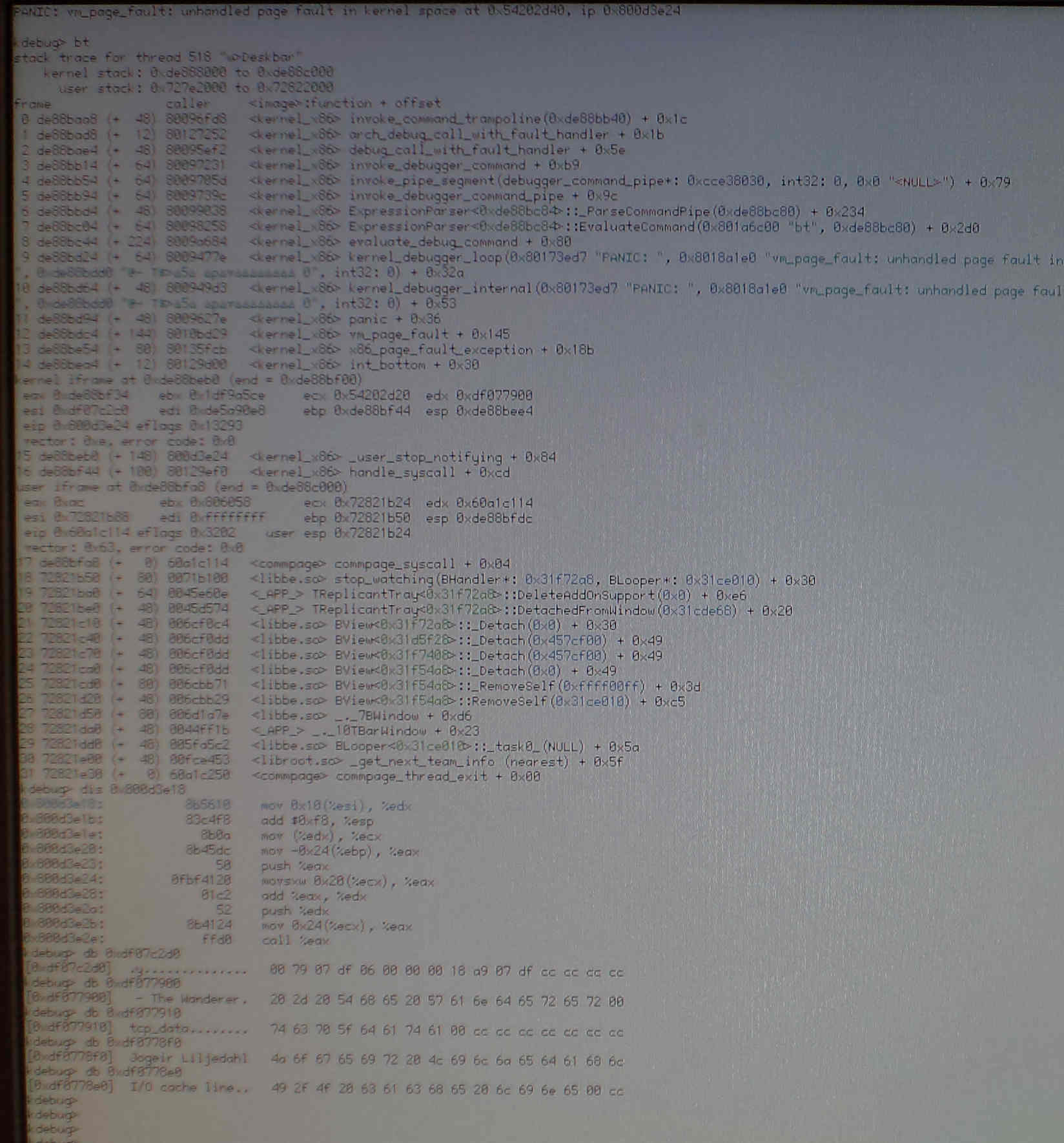
| Attachment: | KDL_ripping_cdda_Ascii_string_in_structures.jpg added |
|---|
comment:1 by , 11 years ago
Seems to be somewhere in
_kern_stop_notifying(port, token);
called from http://haiku.it.su.se:8180/source/xref/src/kits/storage/NodeMonitor.cpp#113
comment:2 by , 11 years ago
In the interest of making this ticket more attractive :-) here's some explanations that could be useful:
Walk-through of my wannabe KDL session: (I'm new at this so don't hesitate to criticize/advise/tell me I'm all wrong in the following analysis)
- the faulty address
0x54202d40seems to come from register ecx plus an offset of 0x20, so I thought about looking at asm to know where that value comes from; luckily enough "dis" exists and seems to be pre-configured with the current ip address by default. - I ran it on an address a few bytes before (the attached screenshot is a cleaned-up session done once I had all my ducks in a row) to get the full context:
- the
mov 0x20(ecx), eaxat ip0x800d3e24triggers a panic because ecx==0x54202d20 - ecx was affected that a little higher up by the line
mov(edx), ecx, and edx ==0xdf077900, which uses the beginning of the string " - The Wanderer" aka20 2d 20 54(that's the title of the audio CD I'm trying to rip! What is it doing at address 0xdf077900 ?) at that address. - as to edx itself, it was affected by the line
mov 0x10(esi), edx, and esi ==0xdf07c2c0
Any of the above helps pinpoint the problem ?
Use-case:
- ran the CD ripping application
- let it ran on all tracks of "/jogeir liljedahl - the wanderer", compressing them with lame.
- closed down that app
- ejected the CD (with the tower's button, not in software)
- invoked "Shutdown & restart" in the deskbar
- got the above KDL / kernel panic.
EDIT: improved KDL log to make more sense.
comment:3 by , 11 years ago
Kernel function _user_stop_notifying(port_id port, uint32 token) http://haiku.it.su.se:8180/source/xref/src/system/kernel/fs/node_monitor.cpp#1257
comment:4 by , 11 years ago
Regarding that part of the backtrace,
_user_stop_notifying + 0x84
I'm getting the feeling that the code has "gone into the weeds". It makes no sense that it would take 130+ bytes of machine code to implement a two-line C function when it takes less than 60 bytes for stop_watching(), and reading the disassembly for stop_watching() makes sense to me (with some effort) whereas the disassembly for the purported user_stop_notifying() makes no sense at all; so that would support the "gone crazy" idea but maybe I'm missing something..
If the ip register has gone to the weeds then nothing can be trusted in the registers and the stack pointer ..etc and it will be very difficult to determine what went wrong from this KDL... and I'm fscked again, sigh.
comment:5 by , 11 years ago
For what it's worth, the disassembly for "simple" functions can often wind up being significantly more complex than it looks if the compiler decides to inline some of the functions it calls into, which appears to be the case here; at least looking at the actual disassembly for _user_stop_notifying() from kernel_x86 directly yields about 100 lines of disassembly for me, and said code does in fact contain the contents of NodeMonitorService::RemoveUserListeners().
comment:6 by , 11 years ago
| Component: | - General → File Systems/cdda |
|---|---|
| Owner: | changed from to |
| Status: | new → assigned |
From a quick look at cddafs, it's to_utf8() looks a bit suspect: in the c < 0x800 case ( http://cgit.haiku-os.org/haiku/tree/src/add-ons/kernel/file_systems/cdda/cdda.cpp#n63 ), it increments out by two, which, if out happens to be at 254 at the time, would cause us to miss our end of string break condition and keep happily decoding characters, overwriting parts of the stack in the process. Haven't looked more closely elsewhere but it might generally be worth a more thorough review, as the driver does quite a bit of string manipulation.
by , 11 years ago
| Attachment: | KDL_cdda--memory_dumps.jpg added |
|---|
The pointed-to string and the pointer to (the middle of) that string, both in context
comment:7 by , 11 years ago
That out == sizeof... test (instead of >= ) seems super dangerous and worth fixing indeed, there might be a use-case which triggers it; but if triggered, wouldn't it become a "runaway" (extensive) memory corruption crashing immediately, rather than a limited one which is stumbled upon by somebody else as occurs here?
=====
I've shut down the concerned computer this morning, but only after collecting a memory dump of the suspect areas, showing what's before and after to get a sense of what might be out of place. EvilYak motivated me into thinking that it might be possible to collect useful data after all, there's no certainty at all that the code has gone to the weeds higher up, it could well be only the data segments which are affected but not code segments.
Looking at the memory dumps might ring a bell for someone more familiar with the haiku internals.
Some commentary/thinking out loud..
- to recap, the starting point of it all is indirection on invalid "pointer"
54202d40which is in fact a series of ascii chars from CD volume name "jogeir... - the wanderer". - that volume name string is stored at address
df0778f0. - the _user_stop_notifying() code collected what it thought was a pointer, in the middle of that volume name string (a few bytes further down, at address
df077900), because it indirected a pointer located at addressdf07c2d0that points there. - I did a contextual memory dump around the volume name string, to see if it seems out of place, and a contextual dump around the pointer that (incorrectly) indirects into that string, to see if it could be out of place too.
- the
df077900pointer is surrounded by other, similar values, in what appears to be an array of structs of size 32 bytes: you can see valuedf077920,df077960..etc; the memory at addressdf077920..etc, is located just below the "wanderer.." string and contains values like801a9fe0; assuming these are legit, this would validate the idea that there used to be a similar value on the three lines above, which were clobbered by the "wanderer.." string (and also the "tcp data" string..?), and thedf077900pointer would just be innocent/legit: when it tried to access the pointer there to perform its stop-notifying() chore, the pointer was gone and replaced by 'T - ' instead, an ascii string. Trying to indirect it -> Boom. - on the other hand, the "- The wanderer..." string seems to be just an strdup()ed string in the middle of other strdup()ed strings (suspiciously close to the bottom "edge" of that bunch of strings tho, but let's suspend disbelief), so maybe it is not out of place, and it is the
df077900pointer which has gone bad, or even the whole set of pointers beside it on or aboutdf07c2d0which are out of place.
There are more scenarios that one can come up with of course.. For instance a "memory used after being free()d" classic case: maybe the call to strdup() on "jogeir.. wanderer.." (like this one here ) allocates and writes to that 32 bytes chunk of memory after it was mistakenly free() by startwatching/stopwatching et al (which would explain why this bug is hard to reproduce: a 32 bytes string is not going to fit in the same places as a smaller or bigger one, and in a multi-threaded OS it's hard to predict where memory chunks are going to be allocated and in what order, so the free()d memory structure can survive for a long time or a short time depending on butterfly-effect changes...)
comment:8 by , 11 years ago
I would approach the problem by starting with an objdump of _user_stop_notifying() to find out exactly what kind of object gets corrupted. Then the node monitoring code could be scrutinized wrt. to the management of those objects.
If that doesn't turn up any suspects, assuming that this issue is reproducible, certain debugging features of our slab allocator (SLAB_ALLOCATION_TRACKING in kernel_debug_config.h and SLAB_OBJECT_CACHE_TRACING[_STACK_TRACE] in tracing_config.h) can be enabled. If the tracing buffer is large enough for that case (MAX_TRACE_SIZE -- I'd recommend at least several hundred MiB), it will be possible to track down the code allocating and freeing the respective chunk of memory.
comment:9 by , 11 years ago
Not a direct answer to Ingo's kernelland question, but I just noticed this gci student ticket about a vulnerability in StartWatching():...
... reporting that in a certain error case a method may be called on a deleted object like thus:
watcher->Insert(handler);
Even if assuming that this is the same StartWatching() that is accessible from applications including mine, I'm probably going on a limb though when wondering if the above userland call to BOpenHashTable::Insert() on a deleted object could be able to trigger a kernelland crash (due to long word 0x54202d40 being written in the wrong place) later...
But since a hash table typically deals with ascii strings, and a hashed ascii string seems to be written in the wrong place in the above case (?), and my KDL is about an ascii string being accessed in stead of a pointer, well -- I figured I'd better ask :-)
comment:10 by , 11 years ago
I don't think your assumption that hash tables typically deal with strings is correct. Some in the kernel do, but none related to node monitoring.
follow-up: 14 comment:13 by , 10 years ago
Looks like a buffer re-use optimization done wrong.. (Donald Knuth would have something to say about that, something like "premature optimization is the root(fs) of all evil" 8-).. There's a bit of that in Haiku.. But we still love you guys :-b Anyway big kudos to you Michael; went on a hunt for other tickets/symptoms beside the 3 closed, that you might get credited with fixing too.
I'm guessing the kernel "guarded heap" could have helped find this out-of-bounds write.. But as pulkomandy noted in 11718 it's impossible to run Haiku with it these days, not even with 8 GB RAM in Haiku x64. Maybe that guarded heap could be modified to allow guarding only one part of the OS at a time (probably not easy: malloc looks like malloc looks like malloc, no matter which kernel add-on calls it eh ?)
Or maybe the slab debugger mentionned by bonefish in #comment:8 is the one to use in that kind of situation ?
Also interesting that Coverity did not tag that faulty strcpy, it's probably beyond it's heuristics' powers.. (but I'm biased against static analysis tools anyway).
Next time something like that occurs I have to think of going for broke and make the string suspected of a buffer overrun even bigger: in this ticket's case, renaming the CD to a 250 bytes long name (instead of the puny 30 bytes or so of a typical cdda) would have likely crashed much faster and much more reliably, making it much easier to fix.
comment:14 by , 10 years ago
Replying to ttcoder:
I'm guessing the kernel "guarded heap" could have helped find this out-of-bounds write.. But as pulkomandy noted in 11718 it's impossible to run Haiku with it these days, not even with 8 GB RAM in Haiku x64. Maybe that guarded heap could be modified to allow guarding only one part of the OS at a time (probably not easy: malloc looks like malloc looks like malloc, no matter which kernel add-on calls it eh ?)
The guarded heap did find this one, it's exactly what I wrote it for. It simply is a false assertion that a current Haiku can't be booted fully using it. Due to the waste in address space it most certainly isn't possible with a 32 bit version. With 64 bit only the amount of actually available pages is the limit. With the help of virtualization this limit doesn't really exist either, as the guest memory can be paged out and the limit becomes bound only by the size of your swap file.
The much more difficult part about this particular bug was that qemu (and hence kvm) do not support audio CDs (or any kind of multi track for that matter) and therefore can't be used unmodified to reproduce the issue. That's why I had to resurrect the "-cdtoc" patch from the QEMU BeOS port from 10 years ago and make it emulate audio CDs instead.
Also interesting that Coverity did not tag that faulty strcpy, it's probably beyond it's heuristics' powers.. (but I'm biased against static analysis tools anyway).
That is indeed curious. I would have expected it to find such a case.
Next time something like that occurs I have to think of going for broke and make the string suspected of a buffer overrun even bigger: in this ticket's case, renaming the CD to a 250 bytes long name (instead of the puny 30 bytes or so of a typical cdda) would have likely crashed much faster and much more reliably, making it much easier to fix.
Actually making it crash faster does not necessarily help you if the crashes are in random places due to more random corruption. This way you most often get innocent victims to crash, not the code that actually does the corruption (unless it happens to corrupt across an unallocated page boundary, which a large enough buffer might accomplish more easily indeed). Ultimately to find the place where the corruption happens you need the right tools, for example compiler/virtualizer assisted or hardware based memory guarding.
comment:15 by , 10 years ago
| Blocking: | 6172 added |
|---|
comment:16 by , 10 years ago
Did a 60-discs continuous test today in hrev48958 (had never ever been able to rip so many CDs in one go before, period) stopping only when family/kid went to sleep.. I used kernelland cdda, gloves off, everything has been absolutely rock solid. Dane will take over testing for the next few days as I return to programming. Very grateful, especially seeing that you had to invest time and energy in various ways. More on that later.
First time ever I venture into "dis" and "db", maybe I collected enough data to pinpoint this kernel crash ?