

Opened 12 years ago
Closed 10 years ago
#9858 closed bug (fixed)
Ripping CDs -> page fault panic
| Reported by: | ttcoder | Owned by: | nobody |
|---|---|---|---|
| Priority: | high | Milestone: | R1/beta1 |
| Component: | File Systems/cdda | Version: | R1/Development |
| Keywords: | slab | Cc: | |
| Blocked By: | Blocking: | ||
| Platform: | All |
Description
Our CD-ripping/encoding application is more stable with recent hrevs, but we still managed to crash the kernel. It's getting harder to reproduce though, this time it occured after ripping 7 CDs, for dsuden.
Attachments (10)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (52)
by , 12 years ago
| Attachment: | panic_while_ripping_CDs_#9858.JPG added |
|---|
comment:1 by , 12 years ago
| Component: | - General → System/Kernel |
|---|---|
| Keywords: | vm iocache added |
| Owner: | changed from to |
| Status: | new → assigned |
comment:2 by , 12 years ago
| Keywords: | iocache removed |
|---|
comment:3 by , 12 years ago
| Milestone: | R1 → R1/beta1 |
|---|
setting beta1. I (as well as quite a few others i'm guessing) would like to see these vm / memory management issues solved before the next alpha / beta release. As package management is coming, these kinds of things will stand out more and more. (not that I would know how to fix them though _)
comment:4 by , 12 years ago
| Keywords: | slab added; vm removed |
|---|---|
| Owner: | changed from to |
Looks like someone has clobbered the slab allocator's internal data structures. Unfortunately not much more can be said with the available information.
comment:5 by , 12 years ago
| Priority: | normal → high |
|---|
by , 12 years ago
| Attachment: | oneCD_panic_DSC03323.JPG added |
|---|
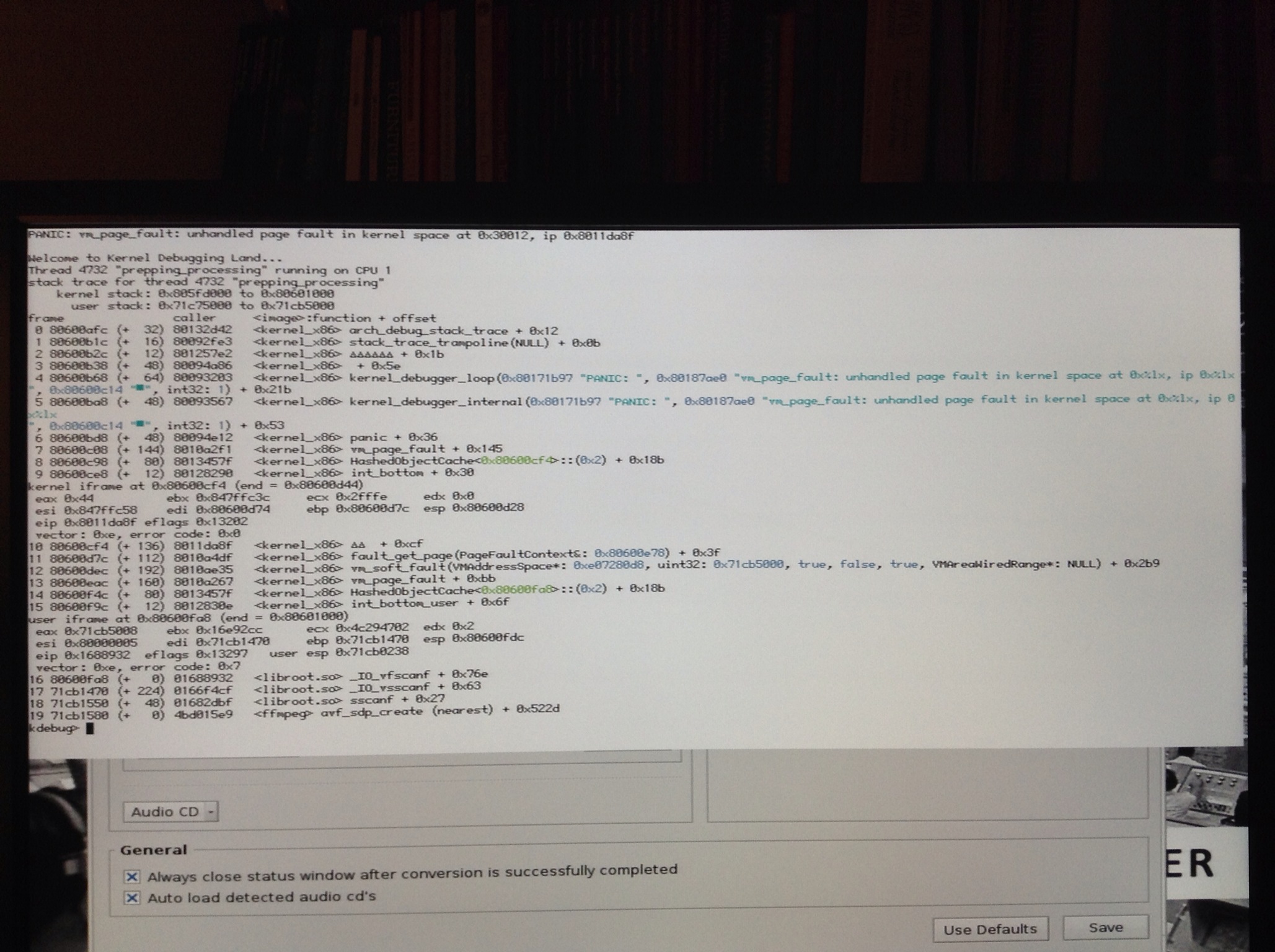
Toward the end of first CDDA rip (panic from Tracker thread)
by , 12 years ago
| Attachment: | oneCD_lots-of-vnodes.jpg added |
|---|
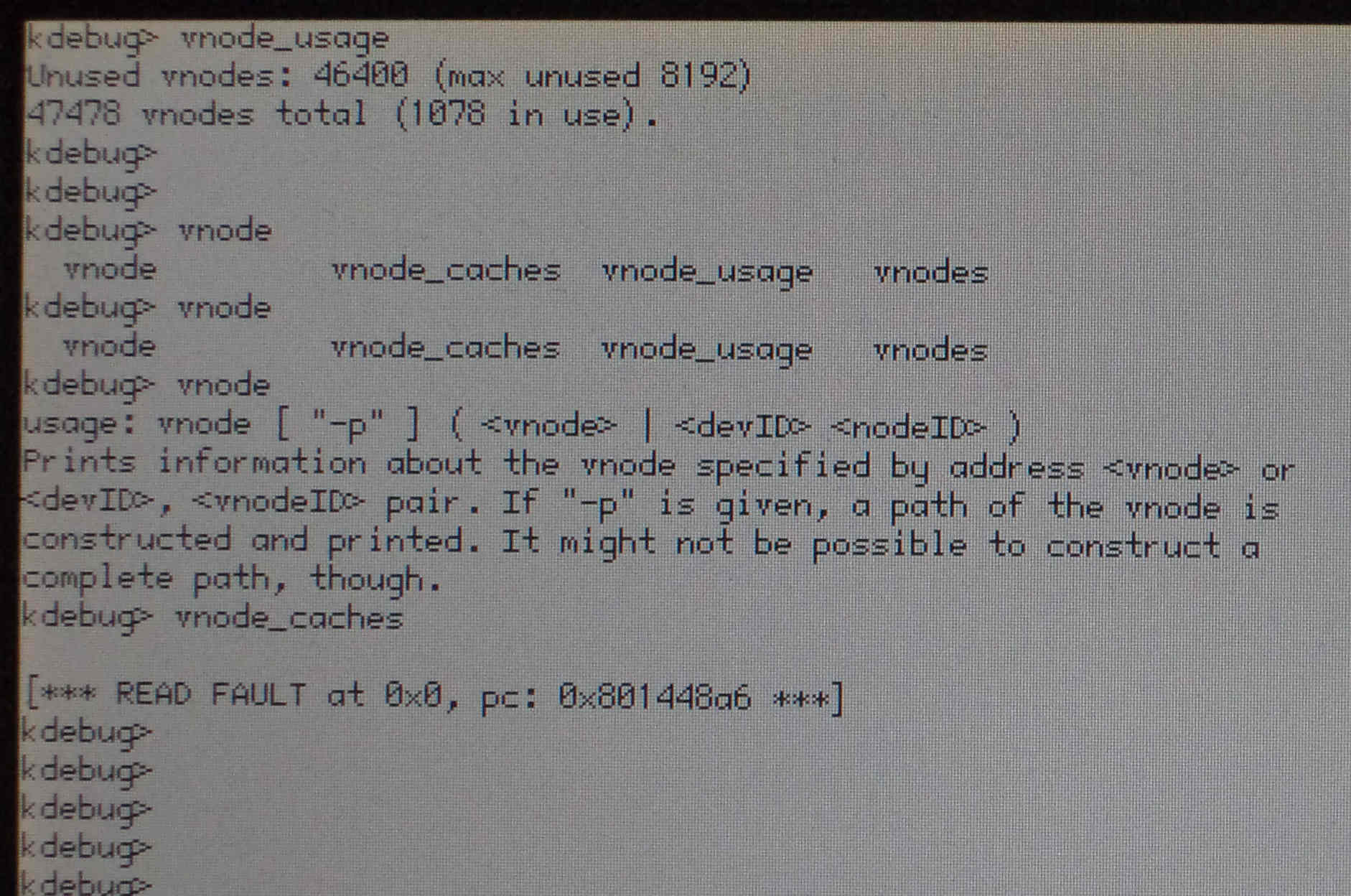
One-CDDA panic: there were 46'000 vnodes
by , 12 years ago
| Attachment: | oneCD_dozens-of-pages-listing.jpg added |
|---|
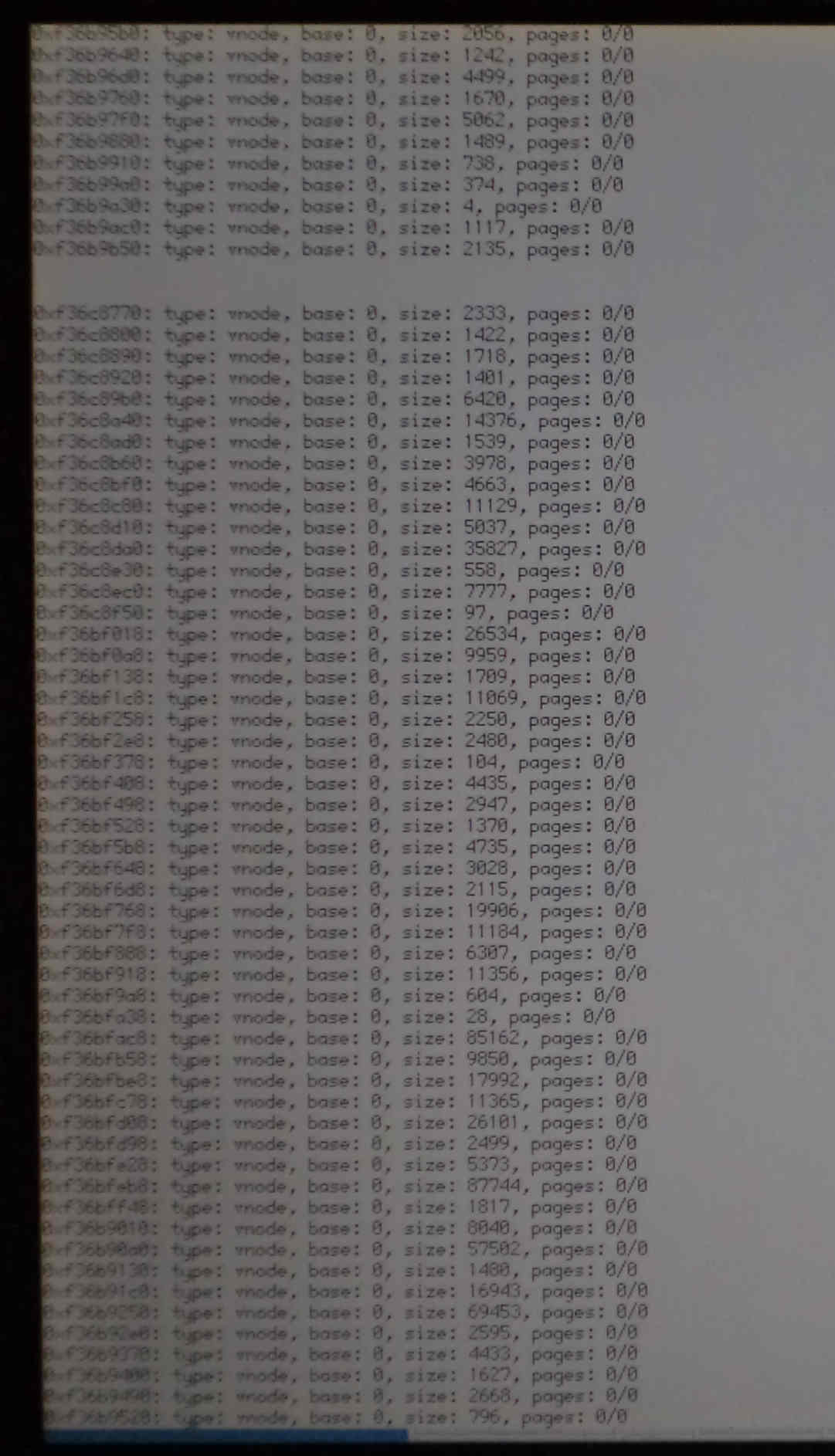
One-CDDA panic: endless listing
comment:6 by , 12 years ago
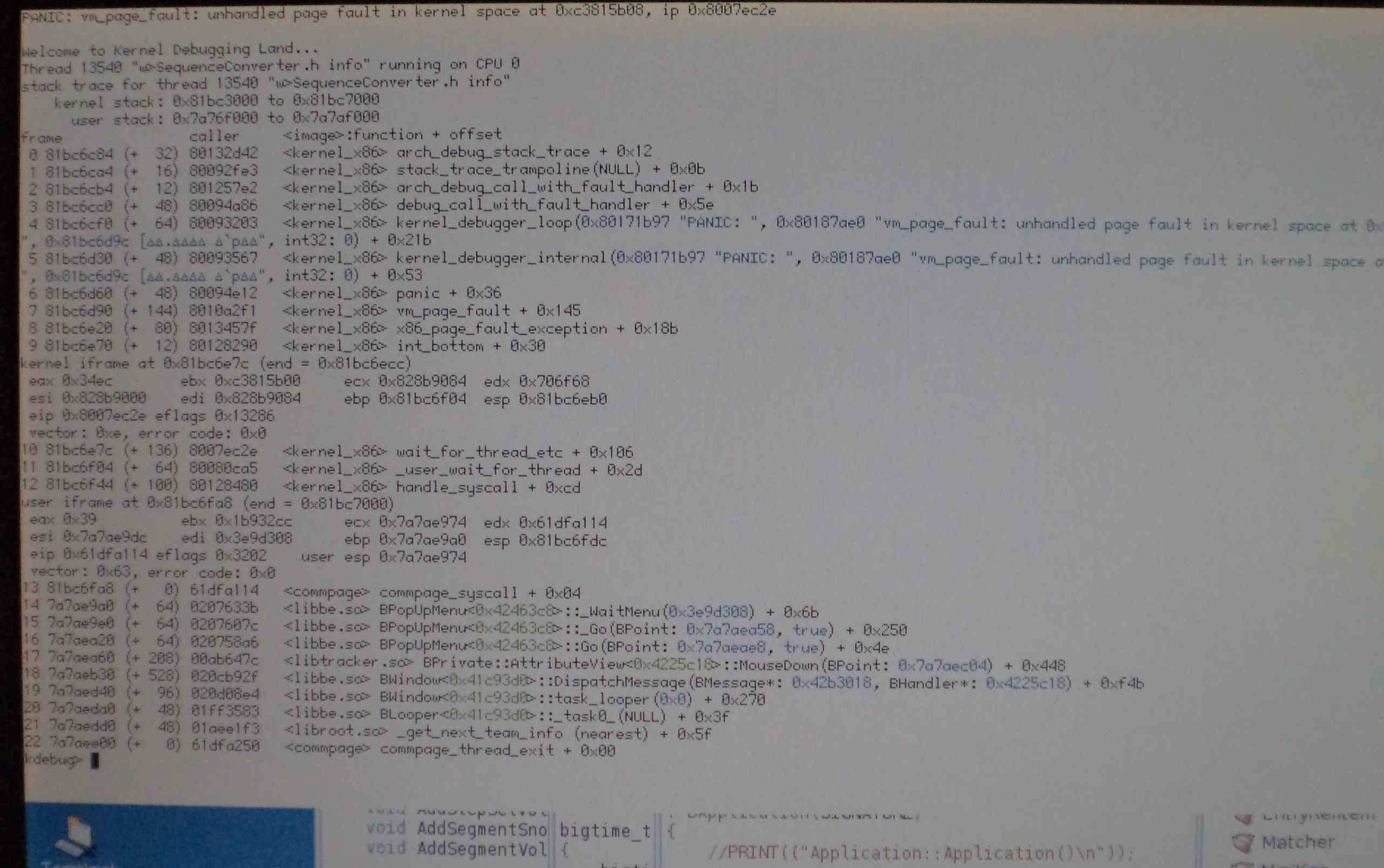
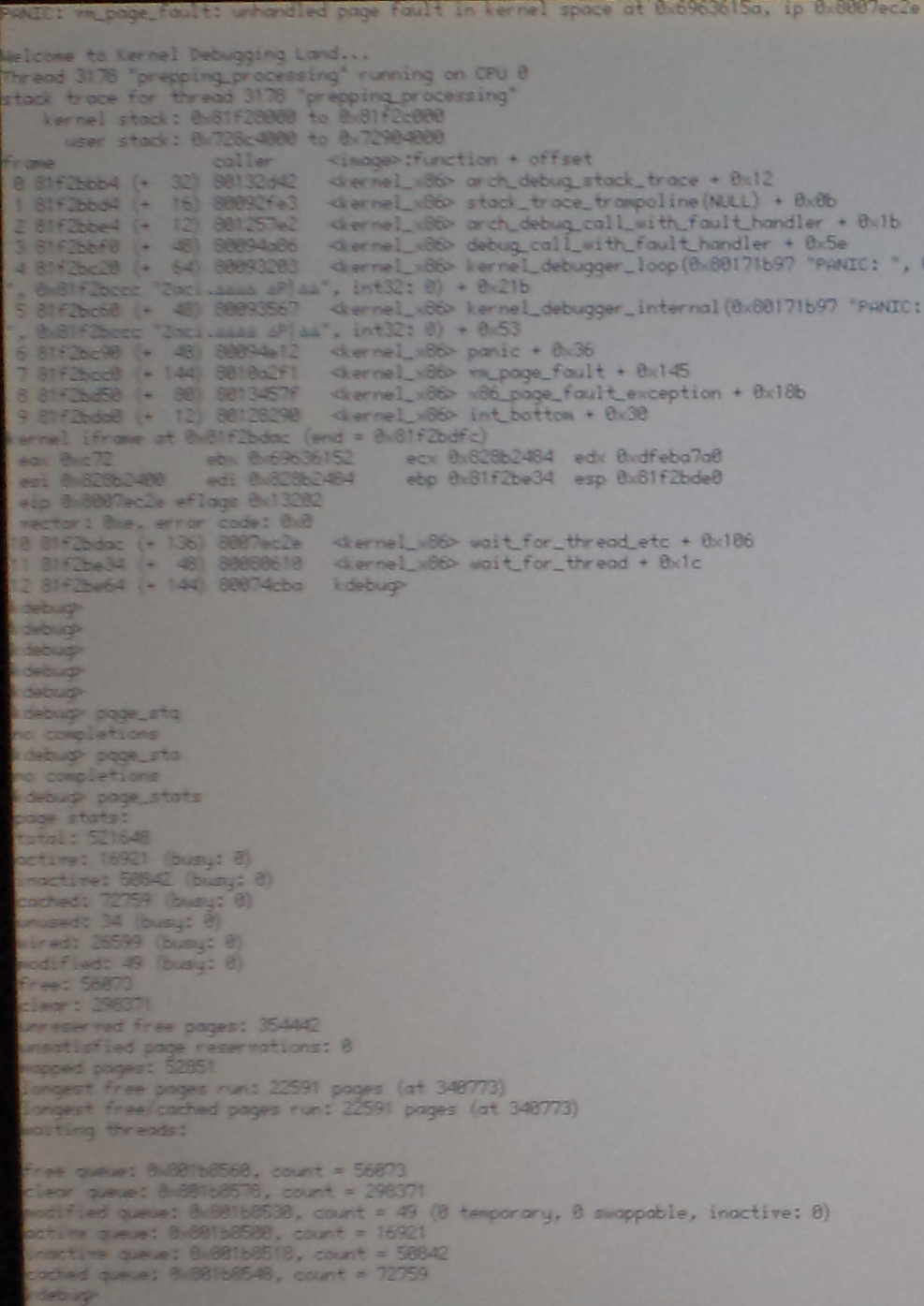
Tried it here and managed to panic toward the end of the very first CD rip, as I was not so gentle as dsuden (MediaPlayer playing music in background, toying with the tracker "Get Info" panel of a header file ..etc). This time the kernel crash comes from a different userland thread than the ripping one (tracker get-info panel) but ends up with a VM pagefault panic too. Historically, using Tracker at the same time as the rip goes on, has been a relatively surefire way to trigger a panic.
Not sure if that's useful, but I toyed a bit with KDL not knowing what I was doing... and realized there was an awful lot of listed vnodes (46'000).. could a resource leak in the application possibly be related to the panic ? File Descriptors maybe ?
comment:7 by , 12 years ago
Since this only happens during ripping, the more likely culprit is a bug in cddafs itself.
follow-up: 9 comment:8 by , 12 years ago
That certainly leaves us some room to manoeuver: we plan to try reducing usage of cddafs as much as possible (in case a different usage pattern no longer triggers the bug), and if that still does not work we'll remove it from the equation entirely and read the CD data another way. I tried the /bin/cdda2wav command but it crashes when reading the very first track (seems to be an old alpha3 build so maybe that's the reason it does not work on recent nightlies?), so I'll have to replicate its behavior, hacking in the /dev/atapi hierarchy.
Dane got another KDL today, trying the strategy 1 outline up here (reducing usage of cddafs to straight copying the files in one pass). The photo is blurry and the first steps of the backtrace are the same, so no point in posting it I suppose. The last step is a failed assert in X86VMTranslationMapPAE.cpp:231
comment:9 by , 12 years ago
Replying to ttcoder:
Dane got another KDL today, trying the strategy 1 outline up here (reducing usage of cddafs to straight copying the files in one pass). The photo is blurry and the first steps of the backtrace are the same, so no point in posting it I suppose. The last step is a failed assert in X86VMTranslationMapPAE.cpp:231
That would be ticket:8345.
comment:10 by , 12 years ago
| Summary: | Ripping CDs -> page fault panic (via sscanf() in ffmpeg) → Ripping CDs -> page fault panic |
|---|
So #8345 leads to #7904 and to 1) trying to use only one core and 2) try to reproduce the TranslationMapPAE crash with installoptionalpackage. I've never had any problem with installoptionalpackage on any hrev, so I focused on 1), which was more fruitful -- documenting today's extensive testing:
I set out to test 2x2 tactics: disabling my second CPU core; and copying files to HDD and rip from there, rather than rip directly from CD.
The result is that I need both tactics to avoid crashing:
- neither strategy in use: KDL, as established before.
- second core disabled, ripping directly from CD: KDL.
- second core disabled, two-stage ripping: I was good for half a dozen CDs!
- re-enabled the second core, continued two-stage ripping: KDL'ed at the end of the very current in-progress CD rip, when quitting MediaPlayer.
Both KDLs were of the page fault panic-in-kernel sort. The first KDL had a very short backtrace (Addon, x86_int, page_fault, panic/trampoline), triggered when I invoked the filetypes tracker add-on. Second was triggered when quitting MediaPlayer and the backtrace involved BKernel::Thread::Deletetimers so it seems again a kernel structure was conpromised. Neither backtrace seemed worth grabbing for posting.
Now that I'm sure how to crash the thingy, i'm going to focus on not crashing :-) , i.e. confirm on 10 or 20 CDs that it indeed won't crash with a core disabled and two-stage file processing. If it won't crash for 20 CDs, then I'll just have to code that work-around in my app, in theory it should work: disable all but one cores in BApp ctor, re-enable in BApp dtor (using again _kern_set_cpu_enabled(..)), and copy files to HDD to encode from there.
follow-up: 12 comment:11 by , 12 years ago
I assume you didn't actually try to disable SMP (in the boot loader or via kernel settings)? The disable CPU feature just tells the scheduler not to schedule any threads but the idle thread on that CPU. Interrupts can still be processed on it. So it's not like disabling all but one CPU actually disables SMP.
Moreover it is entirely possible (maybe even likely) that CD ripping doesn't actually trigger the bug, but just makes it visible. Reading the whole CD simply causes a large cache turnover (essentially the whole CD is read into RAM). So if some paging related structures got corrupted or a page was erroneously marked free before, using a lot of pages makes it rather likely to run into the issue. So even if SMP could actually be disabled live, running into the problem after doing that doesn't necessarily mean that isn't purely SMP related.
Long story short, it would be nice if you could test with SMP disabled.
comment:12 by , 12 years ago
Replying to bonefish:
I assume you didn't actually try to disable SMP (in the boot loader or via kernel settings)? The disable CPU feature just tells the scheduler not to schedule any threads but the idle thread on that CPU. Interrupts can still be processed on it. So it's not like disabling all but one CPU actually disables SMP.
FWIW MSI interrupts seem to only target the first CPU (see here the destination).
by , 12 years ago
| Attachment: | panic_DisabledSMP.jpg added |
|---|
Disabling SMP makes it more difficult to panic, but it's still possible
comment:13 by , 12 years ago
Ingo, long story short -- SMP makes a bit of difference quantatively, but not qualitatively, Also I did a "page_stats" in case you want to take a look.
@korli & bonefish: in case that matters, when I toyed with Pulse to disable a core I always disabled the second one, leaving only the first CPU running. As to the disabled SMP case, I notice Pulse and ProcessController behave as if there is only one CPU in the system at all, so I dunno which it is (probably same situation, it's CPU # 0 that's running and handling interrupts?).
The long version: After Ingo's explanation I rebooted and picked "Disable SMP" in the boot menu. Ended up with only one CPU gauge in the deskbar ..etc as should be. Started ripping, reading the news, listening to ripped tracks (quitting/restarting/quitting/restarting MediaPlayer each time, so as the "mutate" the kernel structures as much and as often as possible), doing Alt-A select all and "Get Info" in tracker ..etc. After 4 CDs the thing was still running like a champ so I started to feel excited, "wow this test is hammering the machine in an unprecedented way yet it won't crash with SMP disabled, so we have uncovered an SMP-specific bug in Haiku"-style. On the fifth CD it KDL'ed though, sigh! So SMP is not the culprit it seems.
I've seen in the "sister" tickets that Ingo recommended using "page_stats" too, so I did (see attached screen grab).
Also I noticed this in my syslog, but it's there even when not ripping CDs so probably not significant: mark_page_range_in_use(0x0, 0xa0): start page is before free list
by , 12 years ago
| Attachment: | panic_DisabledSMP.png added |
|---|
Take two, as a PNG (previous was a JPEG2000 generated in hrev45824)
comment:15 by , 12 years ago
That would be why, for future reference, the web standard is normal JPEG, it's not interchangeable or compatible with JPEG2000.
comment:16 by , 11 years ago
Realized after the fact that W+ (like N+), not being native, it does not use the haiku Translators to decode images... Not that it should necessarily do so either.
Status update:
hrev46188 (which includes bonefish's stability fix(es)), testing on the asus f2a55m system: I'm unable to trigger any misbehaving. I'm now north of 15 audio CDs encoding. We will continue testing in different conditions in the coming weeks. Will also crosspost to #8345 (EDIT: <strike>8545</strike>) if further unable to reproduce either type of crash, which would be great news.
comment:17 by , 11 years ago
The recent fix for #8545 doesn't fix anything serious and I don't see how it would be related to the crashes in this ticket. Those seem to be caused by memory corruption.
by , 11 years ago
| Attachment: | 15CDs_corrupted_BKernel_list_quitting-encoder.jpg added |
|---|
Winding down after the 15 CDs encoding session
comment:18 by , 11 years ago
(fixed the 'peer' ticket number to 8345 in my previous message, my bad)
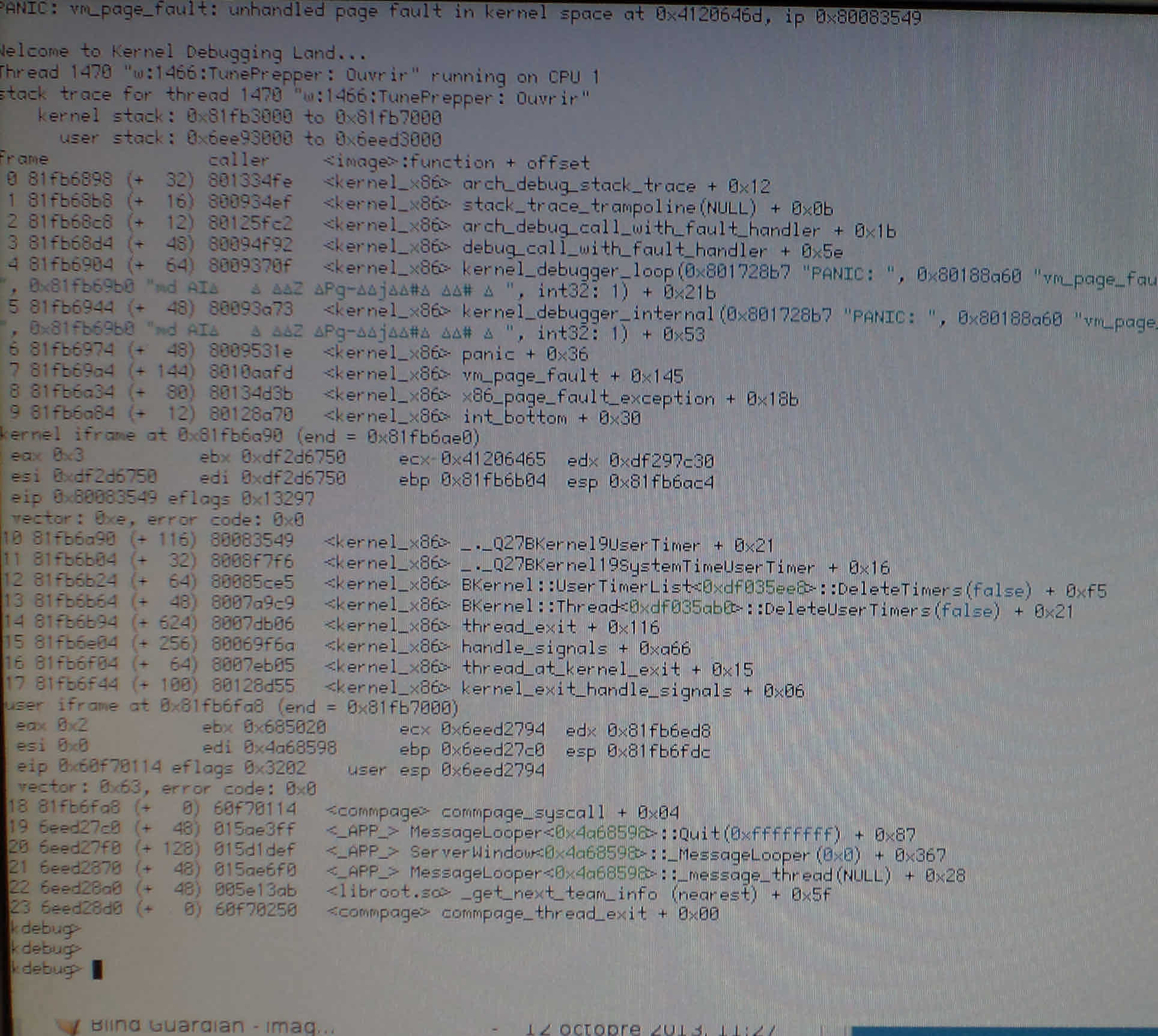
Guess you're right bonefish, seems the problem is still there in 46188.. I actually got a KDL a while after writing my triumphant comments this morning.. It was after everything was completed and I did Alt-Q on TP, the ripping application. Attached: a bad pointer (?) in the kernel UserTimerList stumbled upon as the app's Open filepanel was being destructed.
It's a bit reminiscent of my previous encouters with this, which occured in the middle (rather than the end) of my ripping session, as I started/quitted MediaPlayer or Tracker windows as the ripping occured in the background.
Maybe this time the kernel structure got corrupted earlier and I just dodged the change until the end as I didn't quit the impacted app until the end.
Next I'll test on my old Core2 development laptop, where the corruption seems a bit easier to trigger, and I'll remember to start/quit some new threads and teams during the ripping time. If I find an "easy" way to trigger the KDL that'll make me courageous enough to find a method to the madness :-) again and go "divide and conquer".. divide the problem in terms of drivers being used, steps involved in the ripping process (CD access, LAME pipe() and so on).
P.S. 0x4120646d translates to 'A dm' in ASCII, what for it's worth.. Which is probably not much, since previous KDLs did not have ascii contents in the page-faulty addresses that I remember...
by , 11 years ago
| Attachment: | dsuden_f2a55m_hrev46188__shifted_0xdeadbeef!.jpg added |
|---|
Different KDL message and (interestingly) the bad address is -> 0xdeadbeef <- !
comment:19 by , 11 years ago
Possible breakthrough warning (if we're lucky). Please take a look and tell me if my expectations are inflated or not :-)
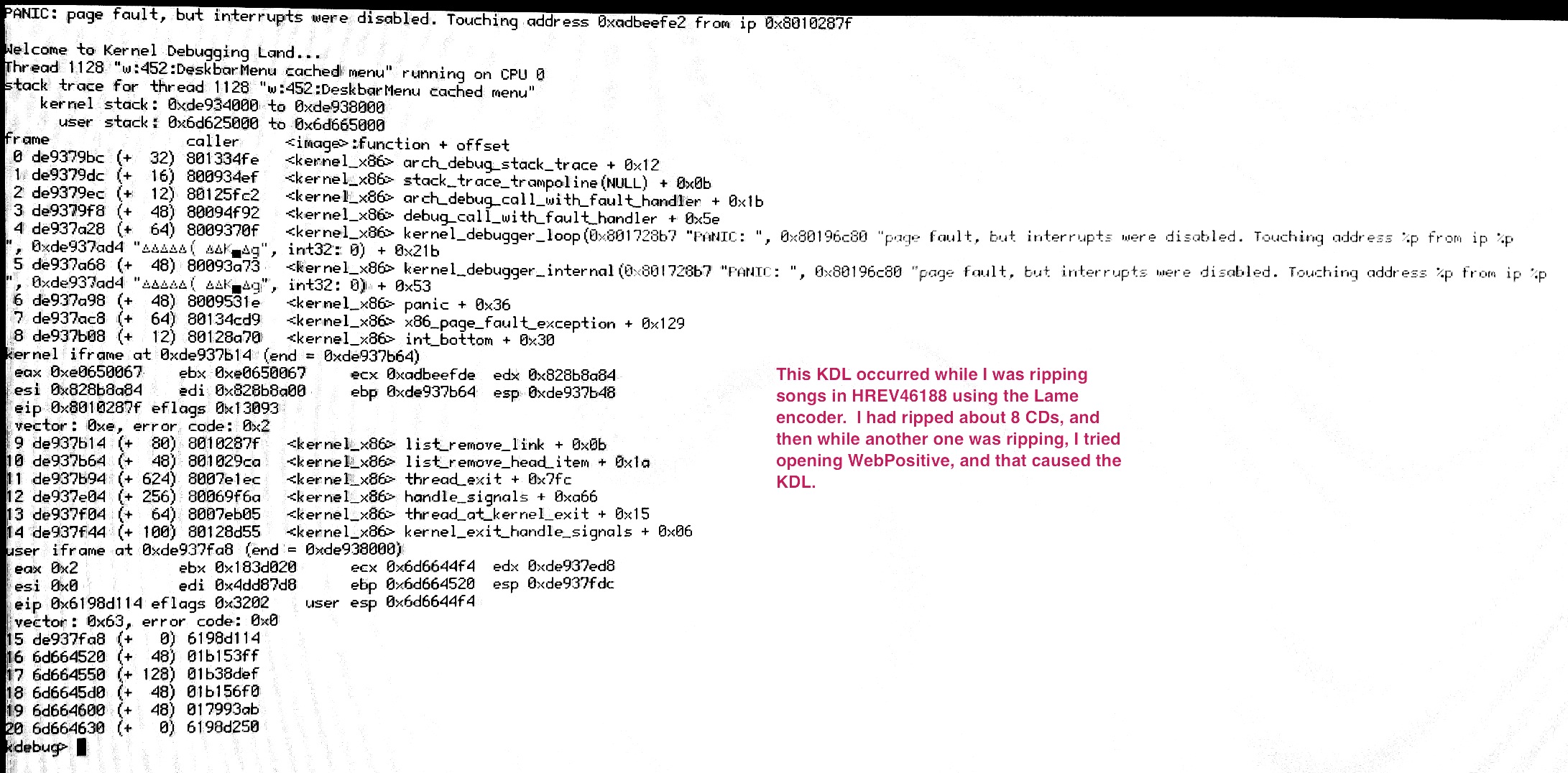
I enrolled dsuden in the test with a recent nightly, he had a much easier time than me reproducing the KDL. First two backtraces/message are similar, "unhandled page fault in kernel space". The third one made me fall off my chair though. Here it is typed to text for emphasis:
PANIC: page fault, but interrupts were disabled. Touching address 0xadbeefe2 from ip 0x8010287f
If it gets the spidey sense tickling in a userland guy like me, maybe it will really interest kernel-savvy people :-)
So why is there a shifted/mangled deadbeef in there.. Seems related for sure to the ecx register, with an almost "clean" deadbeef value. Seems like there were two 0xdeadbeef values back to back, and list_remove_link() tried to access an address across the two.
IIRC 0xdeadbeef is written when a pointer is free()d (or whatever the kernel-land equivalent of free() is), is that right ? That should get us closer to finding the problem, with some luck ?
Also gotta note that the KDL message is similar to #7889 rather than to this ticket.. But that latter ticket's backtrace is very different, so for now I'm filing this .jpeg here. I could even file a third ticket.. Might make sense since this KDL smells of a different problem than the others, possibly related to heap/malloc corruption instead of plain old memory corruption ?
Feedback eagerly anticipated, crossing fingers to not be like "actually that deadbeef thing does not tell us much useful stuff at all, continue testing some more". *g*
comment:20 by , 11 years ago
The kernel free() does indeed fill the freed memory with "deadbeef". I don't think that is relevant in this case, though. From the back trace and the corresponding disassembly one can infer that in list_remove_link() the line
link->next->prev = link->prev;
crashes. At this point link is in eax and link->next in ecx. Since ecx is a bad pointer, the
mov %edx,0x4(%ecx)
instruction causes a page fault. The reason why the "deadbeef" in ecx is rotated, is that eax is not 4-byte aligned. link in this case refers to the head element of the Team::dead_threads list. The list element pointers should always be properly aligned. My conclusion is that either the list anchor (i.e. part of the Team structure) or one of the list elements has been corrupted.
comment:21 by , 11 years ago
I think I understand.. The memory-corrupting bad guy did not necessarily write "deadbeef" in the chained-list itself. Maybe it wrote something else, that happened to be in a valid page, so the linked-list routine followed that corrupted (but memory-valid) pointer and read what it thought was the next linked-list item at that address, which in that very place, contained deadbeef by sheer chance. That is consistent with the fact that I only ever saw one KDL with "deadbeef" in it thus far.
So we still have no clue on who the bad guy is yet.
But I'm making (slow) progress on crafting a reproducible case though: Luckily I've found some steps to reproduce the KDL quickly, in just 2 CDs. I've had 3 times the same KDL in 3 attempts (with corrupted address = 0xb and instruction pointer IP = 0xb, called from userland stop_watching, each single time). So I now consider it triggerable reliably. My next steps will be to reduce the list of steps needed to trigger it, and then make these steps "portable" to you bonefish et alia.
comment:22 by , 11 years ago
Just realized that my "new" KDL is actually very similar to #9528 ; time will tell if this one and that one are two separate issues or not..
comment:23 by , 11 years ago
Just got two (grainy, hard to read) KDL photos from customers, similar to this ticket's.
In both cases the KDL was triggered seemingly without involving cdda-fs at all: it was SoundPlay reading a hard-drive file, ending up in VMCache::LookupPage(), which paniced on a bad pointer.
As to me, I'm knocking my head against walls as I can't reproduce the KDL with the supposed fail-safe steps I mentionned above, sigh :-( . Will try some more.
EDIT both clients seemingly use the old Alpha4.1 hrev though
comment:24 by , 11 years ago
In each of these instances, was the Inode count still high, and was cddafs still being used? Maybe it still is CDDAFS's problem...
comment:25 by , 11 years ago
Unfortunately over the years I've spread out CDDA crashing symptoms over a constellation of tickets before realizing recently that they could be consolidated into a couple bugs it seems. The inode count lead I've completely dropped but I did a survey of my tickets and here's a summary in case you feel like banging your head against the wall ;-)
House keeping:
- apply Jerôme's fix here ; did it locally; it didn't fix the crashes, but at least I know I'm no longer leaking an fd for each attribute bundle :-)..
- maybe also the
to_utf8infinite loop risk, though as I said that code is little to never exercised (and commented out in my builds) but can't hurt I guess.
R&D/head banging on my todolist, or for anyone with thte spare time:
- look into answering the question here though I have no idea if I've touched something important or completely benign there..
- review #10259, which has a good description of the "text string as pointer" lead that I'm following in priority.
- the current/best lead that I have on solving the text-string-as-pointer crash is not in 10259 , but instead it starts with this comment and further down. I'll look into it as time permits. I'll e.g. completely disable free()/delete calls throughout kernel_interface.cpp, in case the KDL is caused by a heap corruption after a double-free. Or maybe the string is copied into system structures (talking of the CD's label/name here), so I'll hack a custom version of Volume::Name() that returns a sequential number (cd01, cd02) each time it's called, to determine which copy ends up in the KDL screen into the edx register.. INdeed, currently if Name() returns 7a7a7a7a7a.. then that "address" ends up displayed in the KDL screen, but Name() is called several times so it will be itneresting to know which call starts off the chain of destruction..
The closest I have to a reproducible case BTW, is opening/closing the (Tracker) window of the AudioCD as it's being concurrently accessed from another application, hence the attributes being read/Written with time pressure, some sort of race condition.
My intuition is that the heap corruption occurs at that time, as "cookies" are allocated for accessing attributes. In the syslog with my extra tracing I can see that there are "cross-overs" between free_cookie() and allocate_cookie(), maybe the code is getting confused there.. esp. confused with regard to the fName label that ends up being interpreted as a pointer instead of a text string.. Dunno. I'm not nearly skilled enough to debug this efficiently.
EDIT-n: failing all the above, in the future I might still take a look at creating a recipe for the "cdda2wav" utility, which fails to run on HaikuPM currently, fix it up and re-organize our application to use that command-line tool instead of the cdda filesystem.. But that's a long shot.
comment:26 by , 10 years ago
| Component: | System/Kernel → File Systems/cdda |
|---|
comment:27 by , 10 years ago
In hrev48285 I fixed a buffer overrun in the cdda code. I still get panics after this change but they seem slightly harder to trigger. I'm continuing to test to see if I can find some useful information.
During my testing I noticed some things that are worth noting:
- The panics occur at random places (I don't think I saw twice the same), which points to some kind of memory corruption that is only detected when it corrupts something else. That's not easy to debug, but the buffer overrun in the cdda code was just that kind of bug (it overwrites memory outside the allocateed buffer).
- In the various related tickets there seem to be some confusion between cdtext and cddb. So to make things clear, cdtext is stored on the CD, while cddb data is downloaded from the internet after computing an ID for the CD. To test cdtext, you need a CD that has some cdtext data, and to be sure, you probably want to disable cddb (either kill the cddb_daemon, or just work on a machine with no internet access).
- I got one panic with the cddb daemon trying to write the Album:Title attribute to one of the tracks on the CD, apparently in the final strdup in the cddb_create_attr function which hit a corrupted heap. But I didn't find any obvious bugs in that function.
- I tried enabling the guarded heap, but it's not possible to use it with the package manager, the system runs out of memory before it's done booting. Maybe a more minimal system (with less packages) would still work.
- I tried enabling the debug heap too, and I didn't hit a panic with that enabled yet. But I'm continuing to test...
So, I'm interesting in reports of
- Ripping CDs with a nightly later than hrev48285. Can you still KDL it?
- Same with the debug heap enabled (see build/config_headers/kernel_debug_config.h and the ReadMe next to it on how to do that)
follow-up: 29 comment:28 by , 10 years ago
1- I've put dsuden on the case, my Grand Fromage is much better than me at triggering the KDL, he can do it in 3 runs of tuneprepper when it takes me 10 or more, we'll have news soon hopefully :-)
2- A moderately-strong suggestion from me, that might get you closer to the guilty party:
Volume::~Volume()
{
...
+ memset(fName, 'z', strlen(fName));
free(fName);
}
Recompile cdda with that memset() in; the change is harmless in itself, in that it will not turn correct code into incorrect code: it is legit to write whatever one wants in a char* buffer before returning it to the system. The interest lies in the fact that the written string sometimes does end up in the KDL message.. (address 0x7a7a7a7a, ascii for "zzzz"). ! It'd be interesting if that is true in your testing as well as in mine.
Anyway that suggestion is based on the assumption that knowing which variable [ 's contents] contains the corrupting buffer, is useful in identifying the code that is guilty of copying that contents into a wild place. Maybe one does not lead to the other and that assumption is wrong though..
(does kernelland have anything like the "watch-point" feature in userland debugger, to detect when a write -- or as the case may be here, a read! -- occurs into a memory area?) (if yes we could point it to the memory area pointed by fName, see who reads its contents to write it elsewhere where it should not be)
comment:29 by , 10 years ago
Replying to ttcoder:
(does kernelland have anything like the "watch-point" feature in userland debugger, to detect when a write -- or as the case may be here, a read! -- occurs into a memory area?)
In KDL you have the commands watchpoint (set/clear) and watchpoints (list). You can set the watchpoints programmatically via the kernel private API arch_set_kernel_watchpoint() (declared in <arch/user_debugger.h>).
comment:30 by , 10 years ago
Have you tried the guarded heap on a 64 bit Haiku? It might just run out of address space. Also, having lots of RAM will help then, too :-)
comment:31 by , 10 years ago
Right, I tried this on a 32bit system with "only" 4GB of RAM. I can build a 64bit version, but my machines with 8GB RAM have no CD drive...
comment:32 by , 10 years ago
I tried a 64bit build with 8GB of RAM, and that still isn't enough to boot even a standard nightly system. No way to use the guarded heap for me then.
by , 10 years ago
| Attachment: | 48297_classic_ascii_crash.jpg added |
|---|
Fairly classic as per the "ascii data corrupts kernel structure" behavior, this time in "enteruserspace()"
comment:33 by , 10 years ago
dsuden is back (from the flu) and kicking; he upgraded to hrev48297 and... managed to crash cdda in just 2 CDs (told you he was good *g*).
Highlights and appetizers for all you hackers-that-be out there :-)
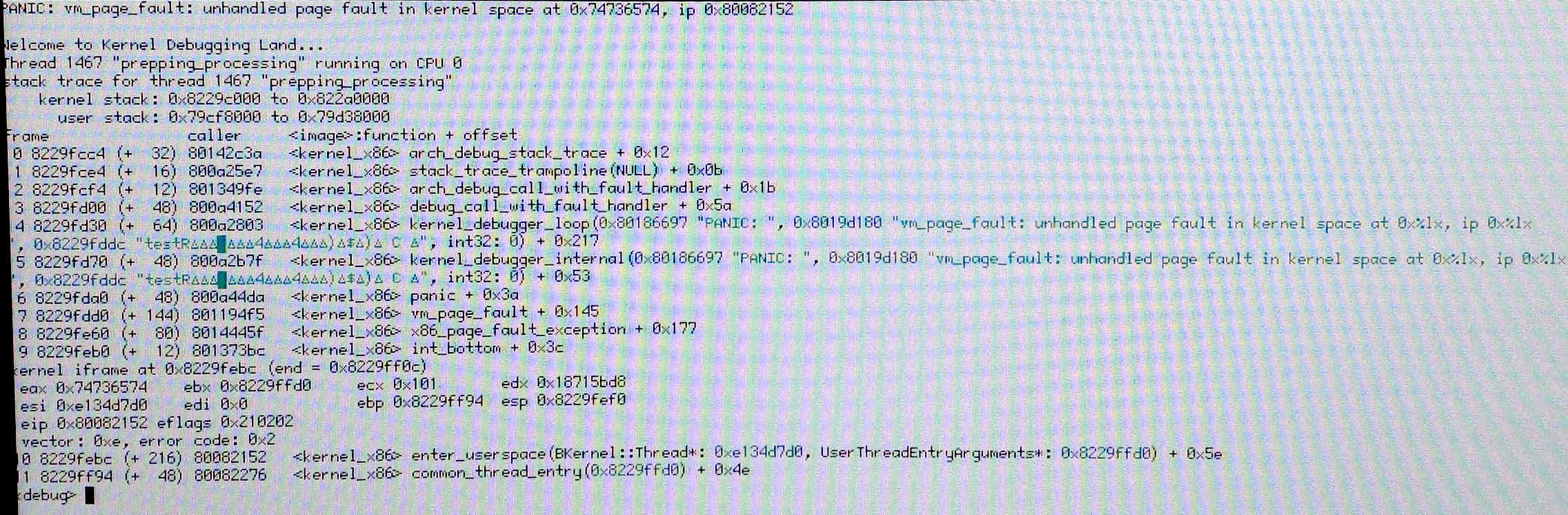
- the second ripped CD's title (hence its
fNamein class Volume I presume) was "Greatest hits". - the dereferenced bogus address 0x74736574 translates to ascii "test"
- that's thus what we here consider a "classic" cdda crash, especially so as the thread that crashes is the prepping_processing thread itself (usually 8 or 9 times out of ten the corruption it makes ends up being tripped by someone else than himself).
- the interesting oddity (to me) of this stack trace is how brief it is, however: `enter_userspace()', and boom, indirection on the bogus pointer.
So there. If his backtrace differs from yours pulkomandy and you want him to type commands at the KDL prompt, fire away while he's setup and motivated ;-)
comment:34 by , 10 years ago
Could you try this with CDDB disabled? (start from a clean install or delete the cached cdda entries, and disconnect the machine from the network so it can't access the CDDB database). Since the panics tend to involve strings, let's try to remove those from the mix.
Did he first or second CD include cd-text? was support enabled? (you mentionned disabling/commenting this in a previous comment, I think).
comment:35 by , 10 years ago
That makes the system unstable after 6+ CD rips, in a slightly different way. Let's try to summarize:
- emptied config/settings/cdda and rebooted
- after boot-up, killed cddb_daemon (as an alternative to unplugging from the LAN).
- it seems clear dsuden was at that point really without artist/title strings (he no longer uses my custom builds BTW, cdda comes straight from haiku), both for the tracks and the "Audio CD" base volume name.
- to be extra confident there is no CD-Text involved (since the baseline cdda driver has that code enabled indeed) despite the fact that no artist/title was showing, I also asked for the output of
grep 'Audio:' /var/log/syslogsince I understand dump_cdtext() outputs lines like that, and the result came up empty.
After ripping 6 CDs that way, the system was in a kind of resource exhaustion situation:
- TunePrepper stopped working, ran through all tracks with the same error, "Error: Failed to initialze the media file"
- opening apps wouldn't work, i.e. couldn't open Terminal to type "sysinfo" and have a count of semaphores available ..et; the Processcontroller replicant didn't show any unusual memory consumption or CPU usage.
- he then tried to close an app to free up resources, and KDL'ed closing W+ (see attached).
by , 10 years ago
| Attachment: | 48297_Sans-Attributes_resource_exhaustion_w+_crash.jpg added |
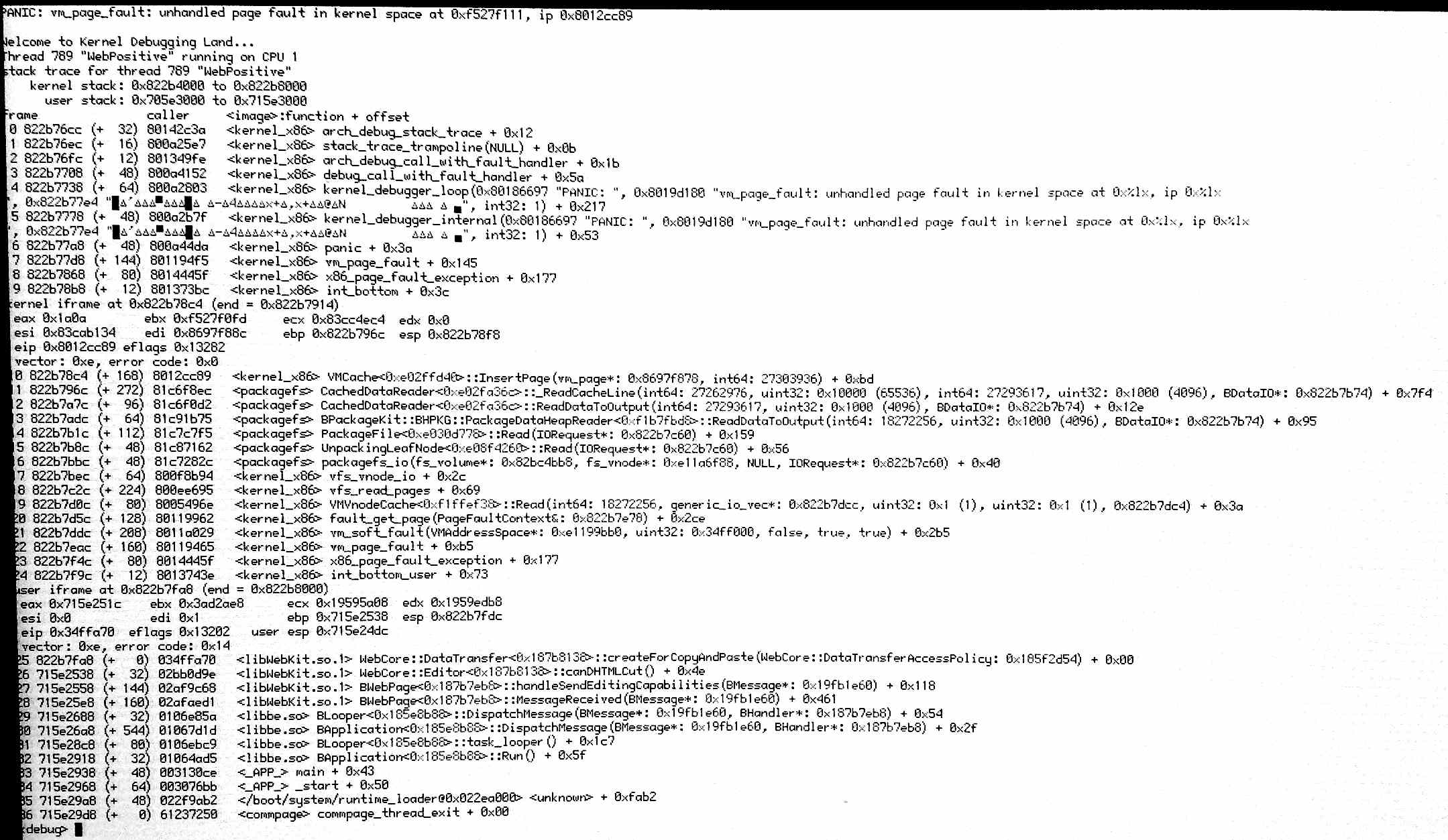
|---|
VMCache::Insertpage() panic when quitting Web+
comment:36 by , 10 years ago
Hi, Today I tried using the userlandfs with cdda to see if I could reproduce the crash in Userland. But instead I still got to KDL. Here is what I did:
Compiling:
jam -q "<userland>cdda" cp cdda ~/confiig/non-packaged/add-ons/userlandfs/cdda
Running (running the userlandfs server this way allows to get the debug output from the cdda add-on, which in this case doesn't get to the syslog since it runs in userlandl):
pkgman install userland_fs /system/servers/userlandfs -d cdda
Mounting (make sure to disable automatic mounting in Tracker prefs to avoid any confusion):
mkdir /audiocd mount -t userlandfs -p cdda /dev/disks/scsi/0/1/0/raw /audiocd
You can then rip the CD and unmount as usual. cddb seems to not work here in that setup. Things went fine until the first CD with cdtext, which triggered a KDL in malloc called from userlandfs.
If this is the same bug, it means it is not an issue directly in the cdda code (that would have crashed on userland side). It can be a problem in the ATAPI commands and the way they are handled by the SCSI driver, or some issue somewhere in the VFS or disk/partitioning system.
comment:37 by , 10 years ago
Thanks for the setup explanation, crystal clear! Some results here too:
CDDB-daemon:
Does not work either here:
..> /system/servers/cddb_daemon ... Skipping device with id 14. Skipping device with id 15. Skipping device with id 16.
I believe the reason for that is it checks against "cdda" for the driver name; indeed if I run the df command in Terminal I find the audio CD is mounted with the 'parent' driver, "userlandfs", ont what it expects. Same issue in my ripping application, I have to drag the audio volume's icon to it to load it up, as it won't detect the volume as being an audio CD.
I'll try to make a custom build of CDDB-daemon with that check disabled/tweaked and report.. Even though it seems you can reproduce the kernel crash without it, but still, ya never know! (want to post the .kdl.jpg for bonefish to take a look here Adrien?)
Stability:
Could not crash the dang thing here, fully stable over the 8 CDs I tried (maybe because none have Cd-Text ? but we have ruled out Cd-Text as being the cause of the KDL before hmm). So I'm delegating that task to Dane again ("here boss, that's the driver.. please take your best shot and break it to pieces" *g*).
edit:
Indeed with a tweaked build of cddb_daemon I get proper attribute values/online lookup now; some remarks though: 1) the lack of Tracker notification of volume renaming is more acute than with the kernelland cdda, it occurs 100% of the time now (maybe it'll be easier to debug? when I have time I'll try to implement this), and 2) when inserting a CD that has already been looked up before, the daemon outputs lots of lines like Failed renaming entry at index 0 to "01 gimme all your lovin'.wav". , not sure if that's the case with kernelland cdda too..
Still can't crash the darn thing either :-) .. Anxiously waiting for dsuden's test results..
Also.. I tried to use this setup from Tracker instead the command-line, but no go:
- blacklisted add-ons/kernel/filesystems/cdda, and checked that it indeed no longer appears
- re-enabled "automount all disks" in Tracker settings
- tried inserting an audio CD and.. nothing happens.
The CD does not get listed in the Mount menu either. Maybe userlandfs does not interact with the system in the same way as cdda does, and Tracker does not "know" to query it ? Or userlandfs does not send notifications or something
comment:38 by , 10 years ago
Well I got it to crash twice with this setup (after 6 or 7 CDs) and each time I got different backtraces, so I'm sot sure they are of much use. I'll remove cdtext CDs from my test set to see if that makes a difference.
comment:39 by , 10 years ago
Good news: dsuden has been at it for 1+ hour, ripped 11 CDs (and counting), and no crash, works perfectly.
That's without the hacked cddb-daemon (gotta send him my copy) but in my/our experience we were able to crash cdda/kernelland regardless of looked-up attributes anyway.
Well so.. This is bad news in that we can't provide data to help resolve this ticket.. But on the upside, we're now thinking of using userlandfs/cdda for production (until now we were -- painfully -- sticking to KDL-prone cdda and recommending users to use a spare computer that can be rebooted at will).. And that will enlarge the scope of use, and improve the odds of providing good data for this ticket.
To that end.. How do we integrate userlandfs so that it appears in the Mount menu of Tracker and cooperates with Auto-Mount ?
(also will provide more feedback on testing as testing continues)
EDIT: 16 CDs without a hitch
EDIT2: With the userlandfs workaround going so well for us (#11718 set aside) I'd say this can be downgraded to 'normal' priority.. I'll wait until we move this to production before breathing a sigh of relief and volunteering to push back the milestone to R2 or Unscheduled though ;-)
comment:40 by , 10 years ago
So with more flawless testing done today it's official, FWIW we consider this to be normal priority.. and maybe milestone R1 rather than R1/b1. YMMV but for us that's that.
comment:41 by , 10 years ago
A workaround was found, but the root cause of this is still unidentified and the results (corruption of random things in kernel memory) is worrying enough to leave it in the beta1 todo list.
comment:42 by , 10 years ago
| Resolution: | → fixed |
|---|---|
| Status: | assigned → closed |
This one fits perfectly with hrev48946. Please reopen if you can still reproduce.
KDL on the seventh CD rip