

Opened 9 years ago
Closed 7 years ago
#12306 closed bug (fixed)
Haiku intermittently won't shutdown
| Reported by: | vidrep | Owned by: | nobody |
|---|---|---|---|
| Priority: | high | Milestone: | R1/beta1 |
| Component: | System | Version: | R1/Development |
| Keywords: | shutdown detailed address_space | Cc: | |
| Blocked By: | Blocking: | #10883 | |
| Platform: | All |
Description
Recent builds of Haiku will often be very slow to shutdown. Today, it wouldn't shutdown at all. Syslogs attached.
Attachments (21)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (85)
by , 9 years ago
by , 9 years ago
| Attachment: | previous_syslog added |
|---|
by , 9 years ago
| Attachment: | syslog.old added |
|---|
comment:1 by , 9 years ago
comment:2 by , 9 years ago
Today, it wouldn't shutdown at all.
What does this mean? Does it close all apps/services, but never turns off? Or does it hang on trying to close apps?
comment:3 by , 9 years ago
Sorry for the poor description. Haiku never turns off, even after waiting more than 15 minutes. There is not any message about an application or service that needs to be terminated - only a blue screen.
comment:4 by , 9 years ago
| Milestone: | Unscheduled → R1/beta1 |
|---|---|
| Priority: | normal → blocker |
I don't see anything in the syslogs, but I suspect it's (yet another) launch_daemon regression.
comment:5 by , 9 years ago
Would capturing serial data help at all? The problem is intermittent, but happens often enough that there is a chance of maybe getting something useful. Any suggestions of steps to take?
comment:6 by , 9 years ago
The launch_daemon currently has nothing to do with the shutdown process at all; while it's planned to change this, it's unlikely to be the cause of any issues there at this time.
comment:7 by , 9 years ago
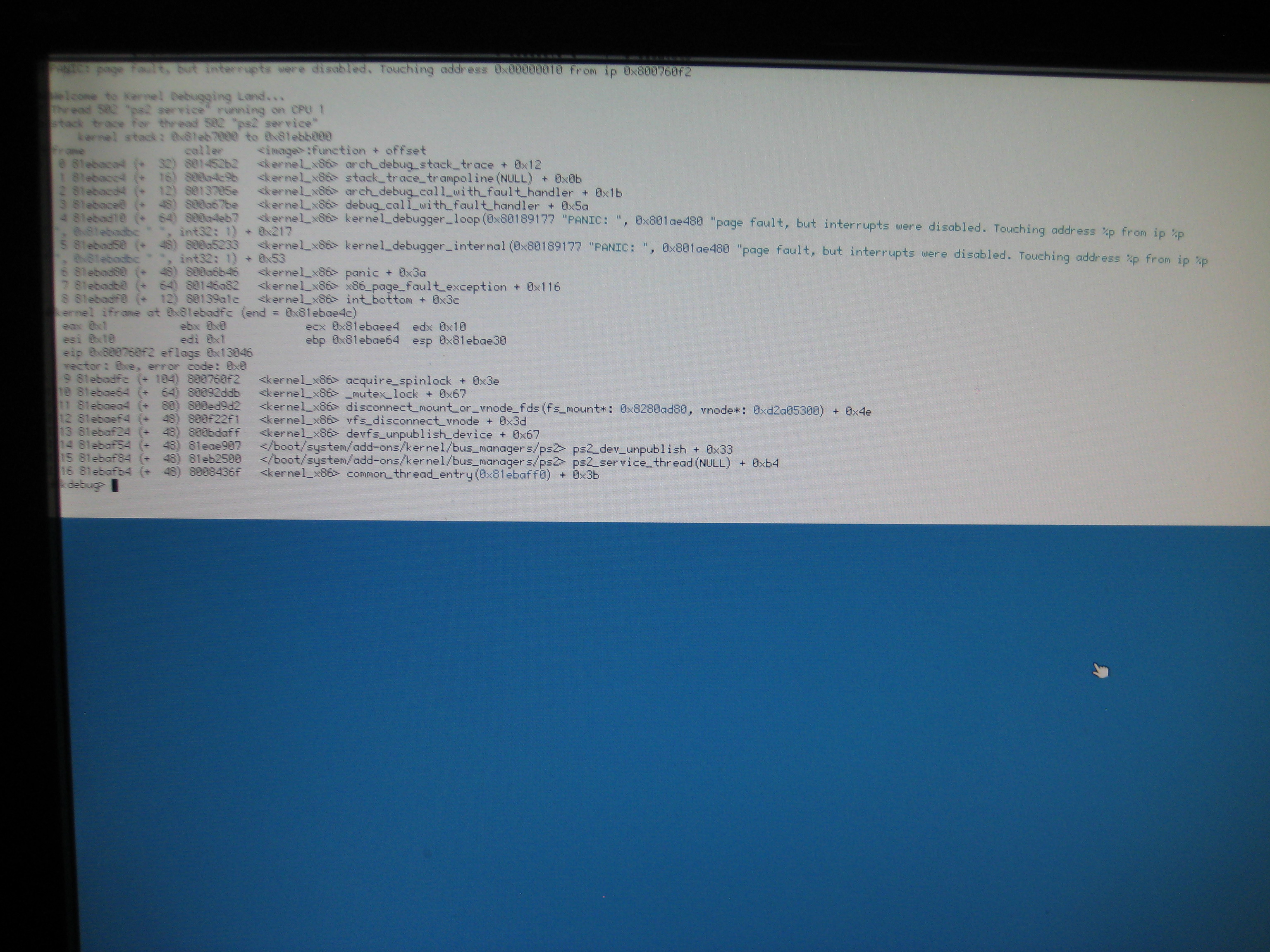
It's happening now with hrev49573 x86_gcc2. It wouldn't shut down. I had to power off and cold boot. Upon boot it immediately went into KDL. I am at the KDL screen now. Any steps to take?
comment:8 by , 9 years ago
Unfortunately I have to go now. I'll attach the syslogs and a photo of the KDL later.
comment:9 by , 9 years ago
Attached syslog and photo of KDL output. If this happens again, what steps can I take at the KDL screen to get useful information?
by , 9 years ago
by , 9 years ago
| Attachment: | IMG_0125.JPG added |
|---|
comment:10 by , 9 years ago
comment:11 by , 9 years ago
The crash in ps2_dev_unpublish is already being tracked in another ticket but I was unable to find which one.
comment:13 by , 9 years ago
This is till happening in hrev49627 x86_64. Is there anything I can do when the shutdown sequence is hanging? I am able to drop into KDL using Alt-SysRq-D. Are there any commands I can execute to get something useful for resolving this issue?
comment:15 by , 9 years ago
hrev49653 x86_gcc2 Shutdown -> Power Off Shutdown Status -> Shutting Down...
Attached are photos of syslog | tail, teams, and threads
by , 9 years ago
| Attachment: | syslog_tail added |
|---|
by , 9 years ago
by , 9 years ago
comment:16 by , 9 years ago
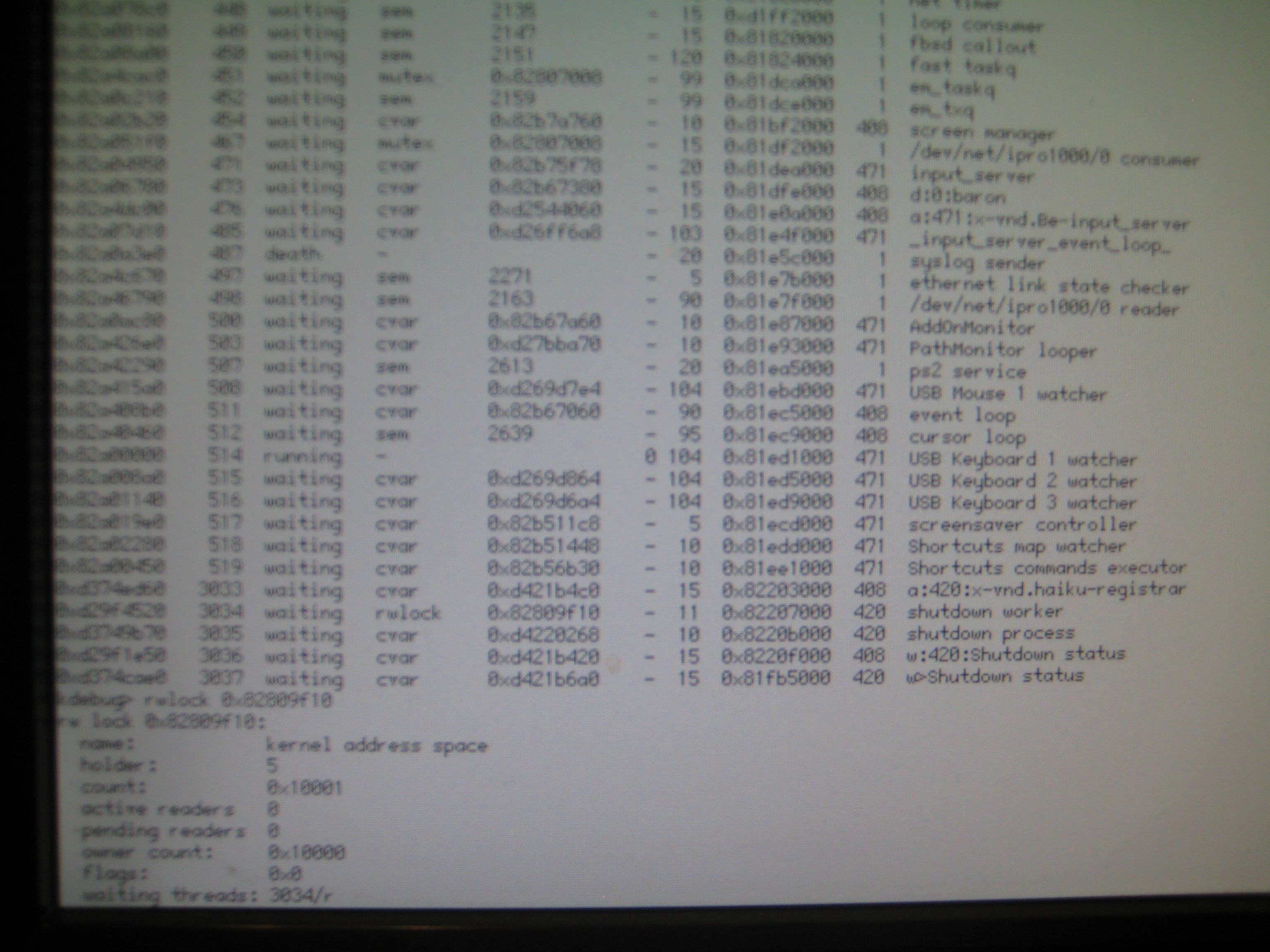
Happened again Dropped into KDL and ran rwlock command on the suspect thread Photo attached (rwlock)
by , 9 years ago
by , 9 years ago
| Attachment: | IMG_0136.JPG added |
|---|
comment:18 by , 9 years ago
Thanks, easier to read online if it has the .JPG extension ;-)
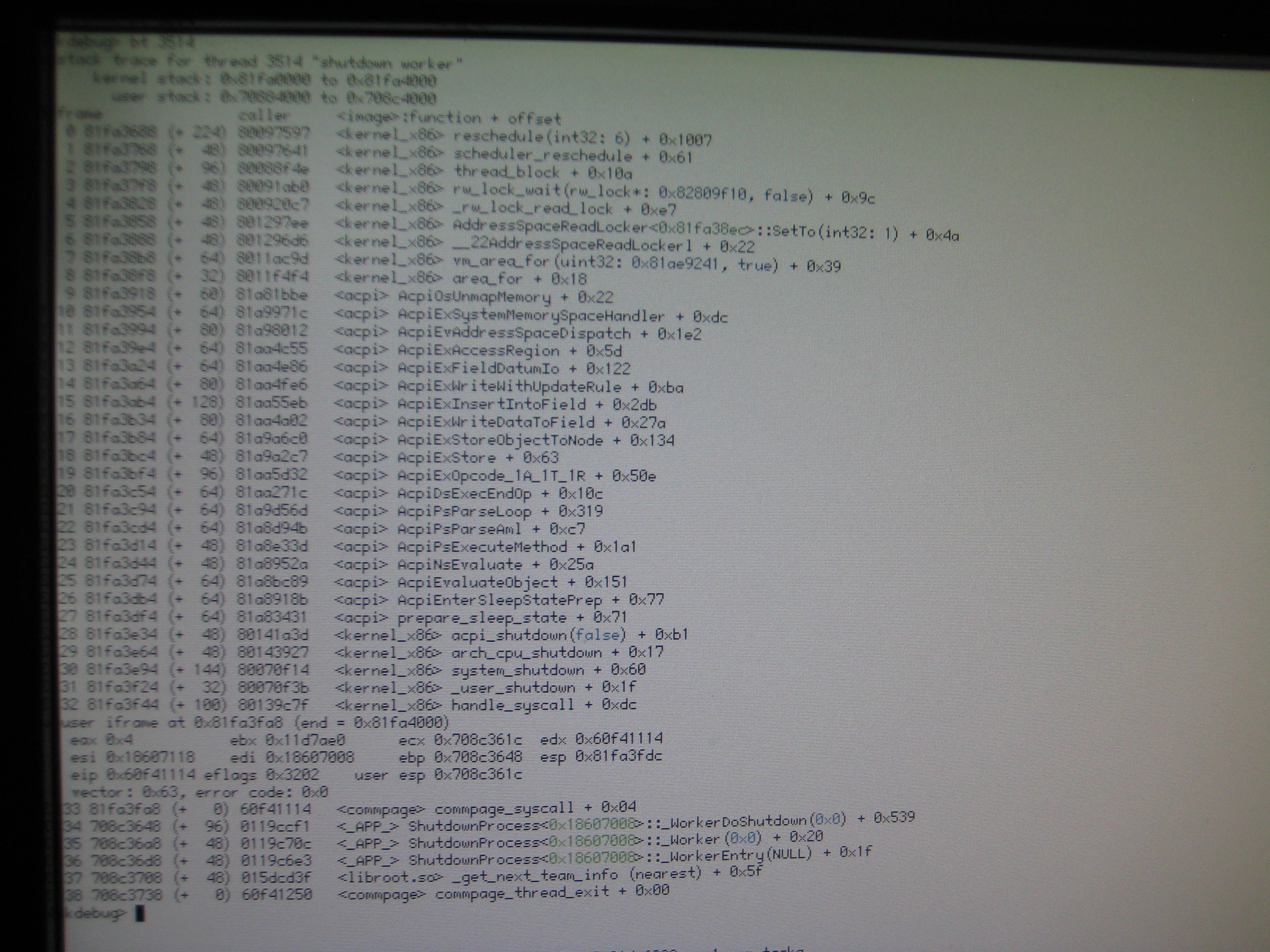
Seems the read-write lock at address 0x82809f10 is the culprit indeed since the same "shutdown worker" thread was stuck on that same lock in the previous instance of the bug (previous screenshot you uploaded).
What's needed now is to draw the attention of one of the kernel devs, drawing their attention to the rwlock named kernel address space not being relinquinshed by thread 5 (-> ?), hence thread 3034 (-> "shutdown worker") being unable to complete its work. Maybe they can interpret the "count" field also, I have no idea what that one means
comment:19 by , 9 years ago
I'm constantly switching between Alpha 4.1, x86_gcc2 and x86_64 builds while testing, so that's probably why I see this issue as much as I do - usually every few shutdown events. Somebody just needs to guide me on what steps to take to get useful information so the bug can be resolved. Thanks again Cedric!
comment:20 by , 9 years ago
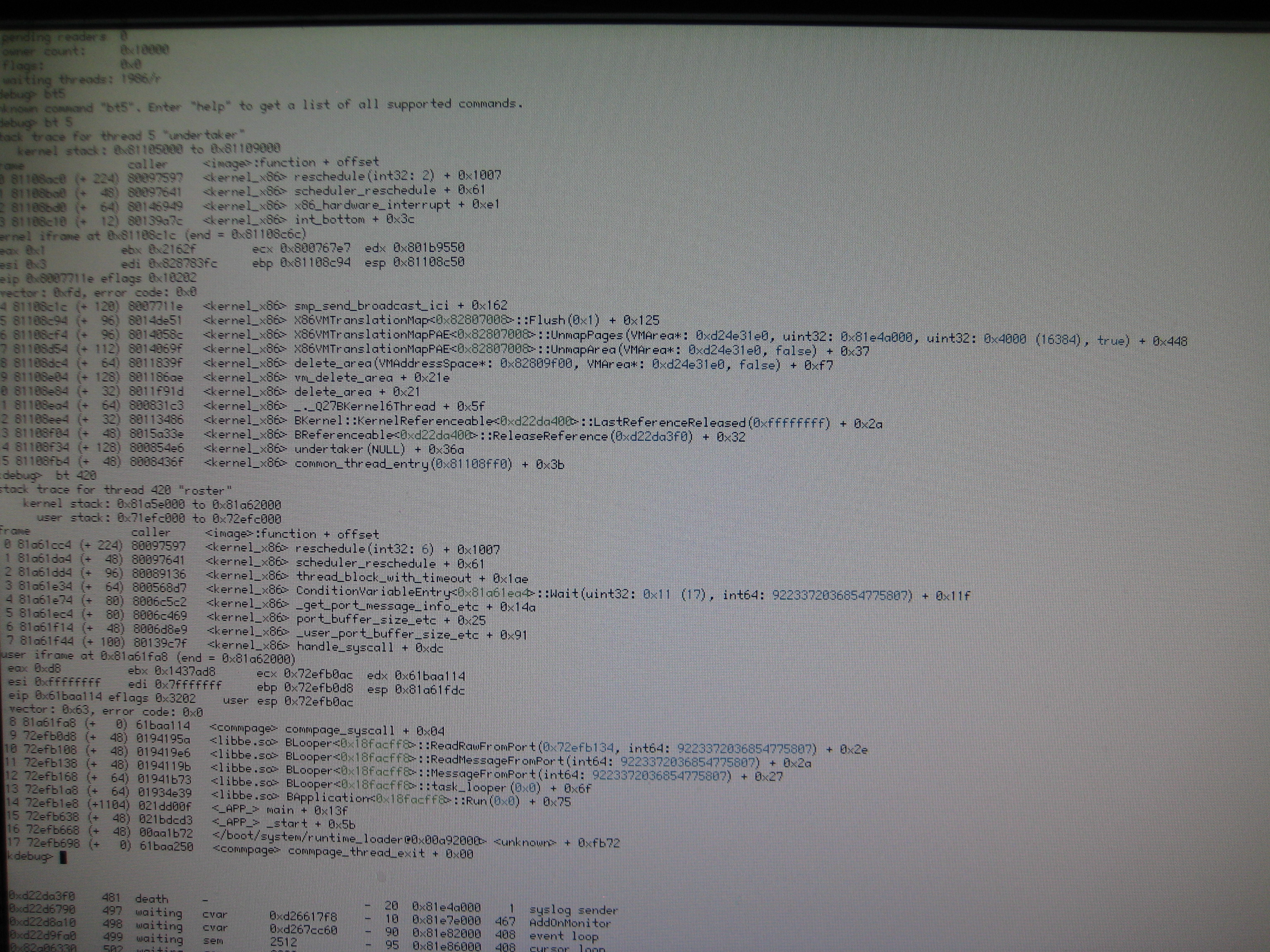
It happened again today. This time I got a backtrace on thread 5 (rwlock) and 420 (shutdown worker). Photo attached (IMG_0132)
by , 9 years ago
| Attachment: | IMG_0132.JPG added |
|---|
comment:21 by , 9 years ago
I may have backtraced the wrong thread. Fortunately it happened on the next shutdown attempt, and I was able to get the proper backtrace for the shutdown worker. Attached photos IMG_1033 and IMG_0134.
by , 9 years ago
| Attachment: | IMG_0133.JPG added |
|---|
by , 9 years ago
| Attachment: | IMG_0134.JPG added |
|---|
comment:22 by , 9 years ago
shutdown-worker's backtrace locates it in rw_lock_wait(), sounds consistent with with the threads command listing is as being stuck waiting on an read-write lock
undertaker's backtrace is more interesting: it seems it acquired the same lock indeed (since its bt is deep in "areas" functions and the lock it presumably acquired does deal with areas) but never got around to releasing it since it's sitting idle in smp_send_broadcast_ici()
I can't find it now, but unless I'm mixing up tickets I seem to recall one of the screenshots you had posted showed you had 3 cores disabled (1, 2, and 3) and only one (0) remaining active.
Maybe smp_send_broadcast_ici() fails whenever it's called with the other cores disabled, which happens sometimes for you for some reason ?? Just guessing, not kernel savvy, you need to get on the horn on IRC ..etc and bribe/beg/steal a solution or at least a true analysis from a real kernel dev, giving them a pointer to this backtrace stuff :-)
comment:23 by , 9 years ago
If the undertaker (or whatever thread) doesn't return from smp_send_broadcast_ici, it's probably either a bug in the ICI mechanism or some other thread is stuck somewhere else with interrupts disabled. It would be good to get stack traces for all currently running threads (get the list via running).
comment:24 by , 9 years ago
Since this bug is reproducible on my system, can somebody give me a step-by-step on what to do next time it occurs? e.g.
- Invoke KDL > Alt-SysRq-D
- threads
- rwlock 0x82809f10
- bt 5
- bt 3514
- running???
comment:25 by , 9 years ago
I guess that would be:
- Invoke KDL > Alt-SysRq-D
runningbt xbt ybt z
Where 'x' 'y', 'z' and so on, are to be replaced with the thread numbers returned in the output of the running command (based on your previous posts we can guess that the first number might be 514 or 516; you'll have to figure out the other numbers from the output on screen); there should not be many of them don't worry, depending on how many cores your computer CPUs have.
comment:26 by , 9 years ago
Is there any way to capture the output of the KDL session to a log file or output through a serial port?
comment:27 by , 9 years ago
IIRC, debug_server writes KDL session to the syslog a few moments after you escape KDL.
comment:28 by , 9 years ago
So, wouldn't the same data be output through the serial port, if the system was set up for serial debugging? It appears only shutdown is affected. If I type in the "reboot" command from KDL then it reboots.
comment:30 by , 9 years ago
I managed to capture the KDL debug output (attached) using a serial connection to a Windows PC. I hope there is something useful in the information provided. Let me know if I can try any other steps.
by , 9 years ago
| Attachment: | KDL_serial_log.txt added |
|---|
comment:31 by , 9 years ago
@bonefish
All three of his "idle thread" are listed as being inside smp_send_broadcast_ici(), with some sort of interrupt occuring therein (?)
There are several calls to that function, maybe this is the one that is referred to in the backtrace: http://code.metager.de/source/xref/haiku/src/system/kernel/arch/x86/paging/X86VMTranslationMap.cpp#108
And the function seems to be defined here: http://code.metager.de/source/xref/haiku/src/system/kernel/smp.cpp#1208
comment:32 by , 9 years ago
The stack traces look all pretty normal (@ttcoder: Not sure what you're seeing. The idle threads are in the idle loop and the interrupt they are handling is the ICI throwing them into KDL). I don't have the disassembly of the kernel in question, but I suppose the "undertaker" thread is pre-empted at the moment it re-enables interrupts at the end of smp_send_broadcast_ici().
I can imagine two possible error scenarios: 1. The thread is never continued (a scheduler issue). 2. The thread is in an infinite loop in X86VMTranslationMapPAE::UnmapPages(). Both can be tested fairly easily via the kernel debugger by setting a breakpoint at the respective return instruction and exiting KDL. If all is well, the thread should reach the breakpoint (immediately) which would trigger KDL. If not, KDL is not entered.
So the whole procedure is:
- Enter KDL as usual, get the threads and the "undertaker" stack trace.
- The stack trace contains two interesting lines. In the attached output those are frames 5 and 7 (first number in the line), listing
X86VMTranslationMap<...>::Flush()andX86VMTranslationMapPAE<...>::UnmapArea()respectively. The last numbers in either line (before the "<kernel_x86>") are the respective return addresses where to set a breakpoint. In the attached output the addresses are8014de51and8014069frespectively. Unless another kernel is installed, they should remain the same (but it doesn't harm to check). - Test the first hypothesis (note the "0x" to prepend to the address):
breakpoint 0x8014de51 co
If KDL reappears right away, probably mentioning that a breakpoint or debug exception has been encountered, the hypothesis is refuted and the next one must be checked. Otherwise we have found the culprit. If KDL reappears, but only after a noticeable delay, that could point to an entirely different issue. - Test the second hypothesis:
breakpoint 0x8014de51 clear breakpoint 0x8014069f co
Again, a reappearing KDL refutes the hypothesis.
comment:33 by , 9 years ago
Bonefish,
Since Haiku refuses to shutdown 50% of the time, it should be easy for me to get the information as per your instructions. I should have a log for you later today.
comment:34 by , 9 years ago
Bonefish, As usual, it refused to shutdown on only the second attempt. I went through the steps as described in comment 32. The log is attached (10032015_1.txt) In both instances it returned to the KDL prompt immediately.
by , 9 years ago
| Attachment: | 10032015_1.txt added |
|---|
follow-up: 37 comment:36 by , 9 years ago
I just noticed I was looking at the wrong lock. The lock acquired in X86VMTranslationMapPAE::UnmapPages() is actually the translation map lock, not the address space lock. The address space lock is acquired in vm_delete_area() i.e. farther down the stack. Could you try the breakpoint procedure with the return address from vm_delete_area() to delete_area()? In your attached logs that would be stack frame number 10 or address 8011f91d.
In case the thread doesn't return, please go up the stack one by one repeating the procedure up to frame number 8 or until the thread returns to KDL. The full procedure would be:
breakpoint 0x8011f91d co ... breakpoint 0x8011f91d clear breakpoint 0x801186ae co ... breakpoint 0x801186ae clear breakpoint 0x8011839f co
comment:37 by , 9 years ago
Replying to bonefish:
I just noticed I was looking at the wrong lock. The lock acquired in X86VMTranslationMapPAE::UnmapPages() is actually the translation map lock, not the address space lock. The address space lock is acquired in
vm_delete_area()i.e. farther down the stack. Could you try the breakpoint procedure with the return address fromvm_delete_area()todelete_area()? In your attached logs that would be stack frame number 10 or address 8011f91d.In case the thread doesn't return, please go up the stack one by one repeating the procedure up to frame number 8 or until the thread returns to KDL. The full procedure would be:
breakpoint 0x8011f91d co ... breakpoint 0x8011f91d clear breakpoint 0x801186ae co ... breakpoint 0x801186ae clear breakpoint 0x8011839f co
I did as you instructed. I have attached the resulting log file to the ticket. Like last time, the prompt returned without delay.
by , 9 years ago
| Attachment: | 10152015.txt added |
|---|
comment:38 by , 9 years ago
Have not seen this problem in about a week. Usually I'd see it every 2nd or 3rd shutdown attempt. Today, I attempted at least 12 shutdowns without issue, as a final test, using both x86_gcc2 and x86_64 builds. Let's consider the bug fixed. I will reopen the ticket if I see it again.
comment:39 by , 9 years ago
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
comment:40 by , 9 years ago
Please reopen this ticket. I spoke too soon about a fix :(. Last night the problem manifested itself twice. I was able to invoke Kernel Debugger and get a back trace on a rwlock. It appeared to be different than what I was getting before. Unfortunately, I was not able to save a log.
comment:41 by , 9 years ago
| Resolution: | fixed |
|---|---|
| Status: | closed → reopened |
comment:42 by , 9 years ago
It happened tonight with hrev49857 x86_gcc2 shutdown->power off shutdown status->shutting down hangs at this message I have attached a KDL_report of the rwlock backtrace
by , 9 years ago
| Attachment: | KDL_report added |
|---|
comment:43 by , 9 years ago
This is still happening with hrev49913 x86_64. However, it is much more intermittent than before. Last time was 4 weeks ago. Previously, it was happening on every 2nd or 3rd shutdown. So, if it's ever going to get resolved, we might have to fall back on those earlier builds or get lucky with recent builds.
follow-up: 45 comment:44 by , 9 years ago
| Priority: | blocker → high |
|---|
Obviously only affects some systems - I haven't seen this yet.
comment:45 by , 9 years ago
Replying to axeld:
Obviously only affects some systems - I haven't seen this yet.
Would it be worth the effort to install an earlier build?
comment:46 by , 9 years ago
From the KDL_report it looks like AddressSpaceReadLocker is already held by something when using area_for in ACPICAHaiku.cpp:
void
AcpiOsUnmapMemory(void *where, ACPI_SIZE length)
{
DEBUG_FUNCTION_F("mapped: %p; length: %lu", where, (size_t)length);
delete_area(area_for(where));
}
Not sure how this could be. Any ideas?
comment:47 by , 9 years ago
Only thing ACPI related I can see is that we allow unloading ACPI module. Is that a bad thing?
comment:48 by , 9 years ago
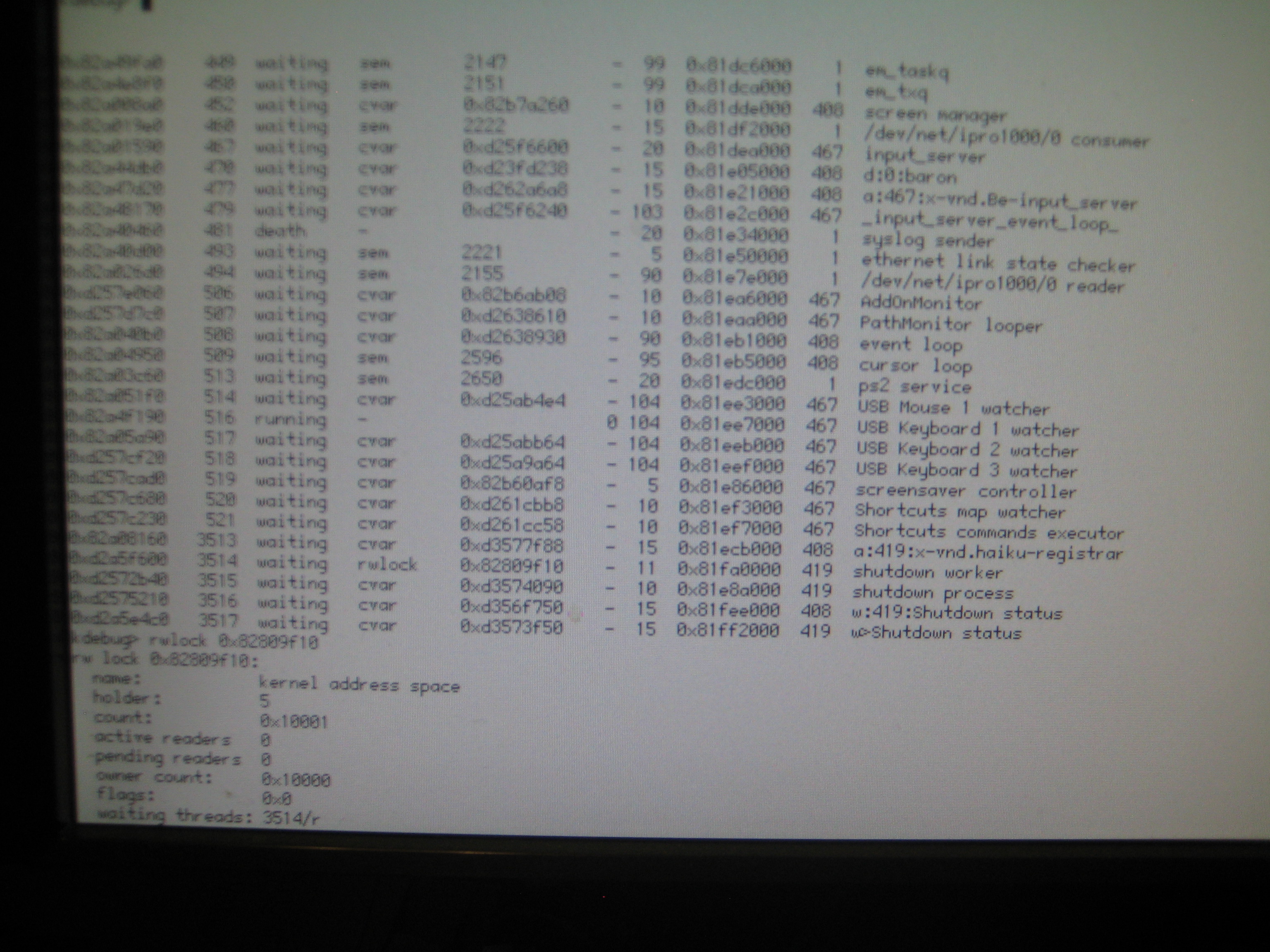
It happened today on hrev50156 x86_gcc2. Attached is a photo of the back trace for the rwlock.
by , 9 years ago
| Attachment: | IMG_0150.JPG added |
|---|
comment:49 by , 9 years ago
Had it happen yesterday on hrev50325 x86_gcc2. I initiated a shutdown and left the house. When I came back home 2 hours later Haiku was still in the process of shutting down.
comment:50 by , 8 years ago
Maybe it is because we disable all but cpu 0 before shutdown:
// Make sure we run on the boot CPU (apparently needed for some ACPI
// implementations)
_user_set_cpu_enabled(0, true);
for (int32 cpu = 1; cpu < smp_get_num_cpus(); cpu++) {
_user_set_cpu_enabled(cpu, false);
}
// TODO: must not be called from the idle thread!
thread_yield();
status = acpi->prepare_sleep_state(ACPI_POWER_STATE_OFF, NULL, 0);
if (status == B_OK) {
//cpu_status state = disable_interrupts();
status = acpi->enter_sleep_state(ACPI_POWER_STATE_OFF);
//restore_interrupts(state);
}
Inside prepare_sleep_state we hang.
From https://github.com/haiku/haiku/blob/master/src/system/kernel/arch/x86/arch_cpu.cpp#L112
comment:51 by , 8 years ago
| Blocking: | 10883 added |
|---|
comment:52 by , 8 years ago
This is still happening with hrev50738, using a different HP desktop PC.
comment:53 by , 8 years ago
Haiku hrev 50849
still happens here too. sometimes if I close the wifi-connection... Haiku will shutdown... sometimes difficult to track down the problem! Very difficult to reproduce!
comment:54 by , 8 years ago
Still happening with hrev50861. It only appears to happen on my HP branded PC's (Elite 8100 & Elite 8300). Could this possibly be an issue with the Intel chipset that's used? Bruno, can you attach your listdev for comparison?
by , 8 years ago
comment:55 by , 8 years ago
I had 2 HP branded PC's with the same shutdown problem. I have attached the listdev for each one of them. listdev_HP8100 listdev_HP8300
by , 8 years ago
| Attachment: | listdev_HP8100 added |
|---|
by , 8 years ago
| Attachment: | listdev_HP8300 added |
|---|
comment:56 by , 7 years ago
| Summary: | Haiku won't shutdown → Haiku intermittently won't shutdown on HP brand PC's |
|---|
comment:57 by , 7 years ago
I use a samsung laptop with Haiku... problem is still the same for more than 2 years now... wont close! Have to hold the power button for 4 seconds! After some reboots it goes to kdl! Have to blank the hd and install Haiku from scratch! Strange Bug!
comment:58 by , 7 years ago
could be indeed related to AddressSpaceReadLocke still held by another thread while we disabled all but the boot cpu, leading to a deadlock.
comment:59 by , 7 years ago
| Keywords: | shutdown detailed added |
|---|
comment:60 by , 7 years ago
| Keywords: | address_space added |
|---|
comment:61 by , 7 years ago
| Summary: | Haiku intermittently won't shutdown on HP brand PC's → Haiku intermittently won't shutdown |
|---|
This looks like it is not hardware specific. I can reproduce it quite often by turning off the first CPU and then shutting down. Can't reproduce in QEMU.
comment:62 by , 7 years ago
The last commit by tqh appears to have fixed this issue. I have not had a no-shutdown event since. The only unusual thing I had happen, once, was when shutting down, the HDD sounded like it was still spinning for a couple of seconds after the PC had already shut off. Related to this perhaps?? https://dev.haiku-os.org/ticket/6847
comment:63 by , 7 years ago
Haiku is shutting down cleanly on both x86_gcc2h and x86_64 since the commit. The issue is fixed (in my case at least). Let's close.
comment:64 by , 7 years ago
| Resolution: | → fixed |
|---|---|
| Status: | reopened → closed |
Closing, please comment if it is still a problem. Preferably with syslogs and hardware details to investigate.
hrev49548 x86_gcc2