

Opened 16 years ago
Closed 16 years ago
#3110 closed bug (fixed)
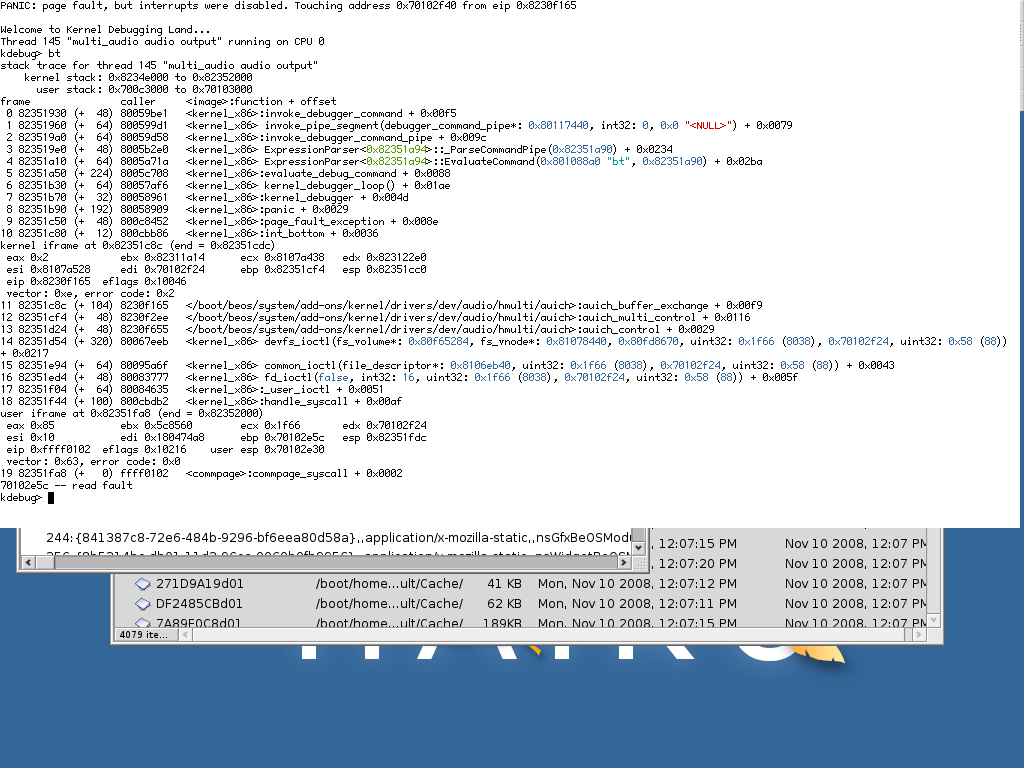
[kernel] PANIC: page still has mappings
| Reported by: | diver | Owned by: | bonefish |
|---|---|---|---|
| Priority: | high | Milestone: | R1/alpha1 |
| Component: | System/Kernel | Version: | R1/pre-alpha1 |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | ||
| Platform: | All |
Description
Happend while I opened Haiku volume in TextSearch and searched for "beos".
Attachments (6)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (29)
by , 16 years ago
comment:1 by , 16 years ago
by , 16 years ago
| Attachment: | kdl_new.png added |
|---|
comment:2 by , 16 years ago
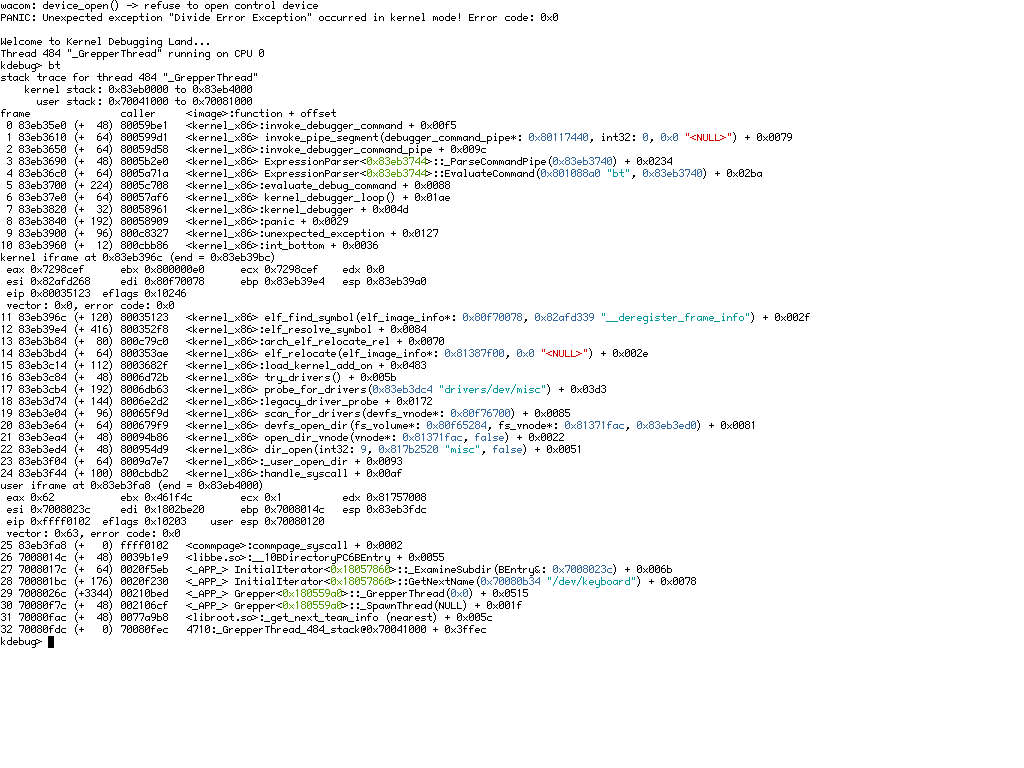
While trying to reproduce I get another kdl with strangly auich driver. Maybe another bug?
comment:4 by , 16 years ago
I just ran into this one as well while closing Firefox after it segfaulted...interestingly it was unable to backtrace into userspace, stopping with a read fault after the iframe. trace looked identical to kdl.png otherwise though.
comment:5 by , 16 years ago
Since then I've updated VirtualBox from 2.0.2 to 2.1.2 and now when I try to reproduce this issue VirtualBox with haiku just close itself.
comment:6 by , 16 years ago
I've encountered these a few times with hybrid hrev29195 on vmware when doing
nc -l -p 2222 >filename
Sometimes in the thread of nc: with Cache::Delete, vm_delete_area (one area), kernel_exit_handle_signals in the backtrace and an kdl error message about a circular stack.
Sometimes in the thread of sh: with Cache::Delete, vm_delete_areas (many areas), _user_exec and a proper backtrace into userland (but without symbol names).
comment:7 by , 16 years ago
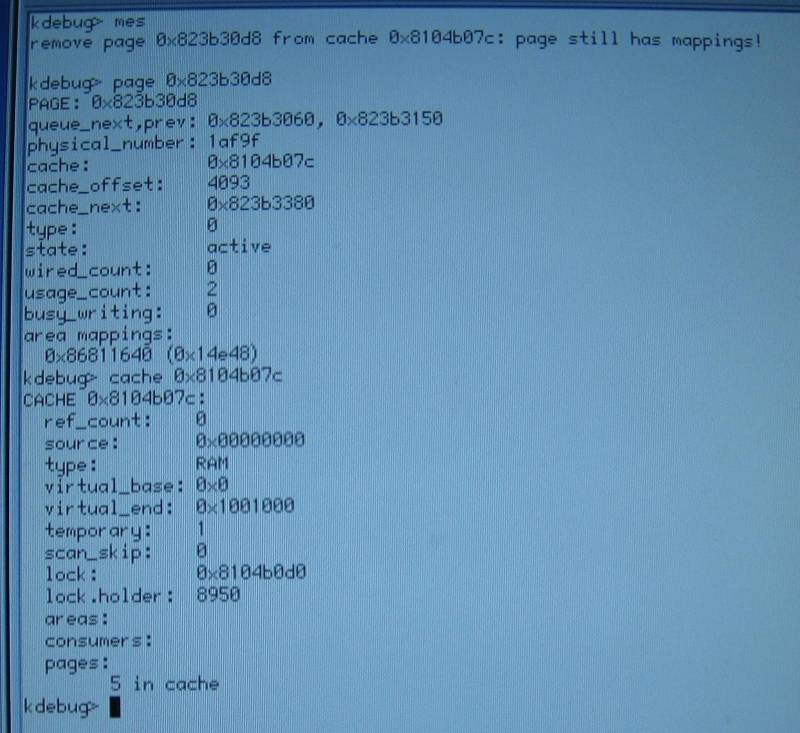
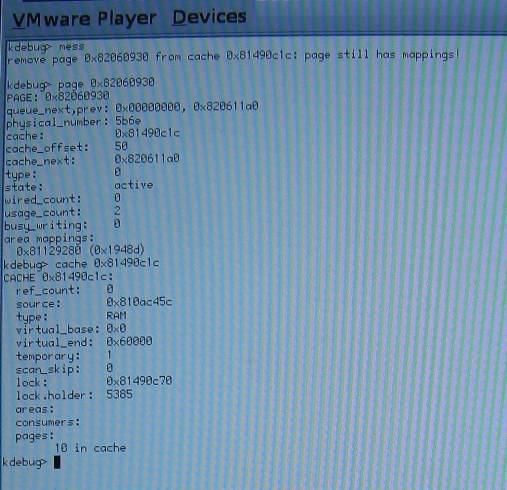
The panic message was "remove page (stuff) from cache (stuff): page still has mappings!"
by , 16 years ago
| Attachment: | page still has mappings.jpg added |
|---|
by , 16 years ago
| Attachment: | page still has mappings.2.jpg added |
|---|
comment:8 by , 16 years ago
page still has mappings.jpg: in nc thread
page still has mappings.2.jpg: in sh thread
comment:9 by , 16 years ago
Just ran into this one while compiling here....specifically:
PANIC: remove page 0x8236b0c8 from cache 0x812f1a2c: page still has mappings!
Welcome to Kernel Debugging Land...
Thread 10652 "cc1plus" running on CPU 0
kdebug> bt
stack trace for thread 10652 "cc1plus"
kernel stack: 0xa13f6000 to 0xa13fa000
user stack: 0x7efee000 to 0x7ffee000
frame caller <image>:function + offset
0 a13f9914 (+ 48) 8005f1b9 <kernel_x86>:invoke_debugger_command + 0x00f5
1 a13f9944 (+ 64) 8005efa9 <kernel_x86> invoke_pipe_segment(debugger_command_pipe*: 0x80127060, int32: 0, 0x0 "<NULL>") + 0x0079
2 a13f9984 (+ 64) 8005f330 <kernel_x86>:invoke_debugger_command_pipe + 0x009c
3 a13f99c4 (+ 48) 800608e0 <kernel_x86> ExpressionParser<0xa13f9a78>::_ParseCommandPipe(0xa13f9a74) + 0x0234
4 a13f99f4 (+ 64) 8005fd1a <kernel_x86> ExpressionParser<0xa13f9a78>::EvaluateCommand(0x80117aa0 "bt", 0xa13f9a74) + 0x02ba
5 a13f9a34 (+ 224) 80061d08 <kernel_x86>:evaluate_debug_command + 0x0088
6 a13f9b14 (+ 64) 8005d0aa <kernel_x86> kernel_debugger_loop() + 0x01ae
7 a13f9b54 (+ 32) 8005df39 <kernel_x86>:kernel_debugger + 0x004d
8 a13f9b74 (+ 192) 8005dee1 <kernel_x86>:panic + 0x0029
9 a13f9c34 (+ 96) 800c283f <kernel_x86> VMCache<0x812f1a2c>::Delete(0x812f1a2c, 0x812f6780, 0x282) + 0x0077
10 a13f9c94 (+ 64) 800c2d00 <kernel_x86> VMCache<0x812f1a2c>::Unlock(0x812f0000, 0x812ff0cc, 0x0) + 0x0124
11 a13f9cd4 (+ 48) 800c2e07 <kernel_x86> VMCache<0x812f1a2c>::ReleaseRef(0x812f6788, 0xa13f9d54, 0x246, 0x812ff0a0) + 0x002b
12 a13f9d04 (+ 48) 800bbb62 <kernel_x86> delete_area(vm_address_space*: 0x812f6780, vm_area*: 0x812ff0a0) + 0x00aa
13 a13f9d34 (+ 48) 800be22d <kernel_x86>:vm_delete_areas + 0x0079
14 a13f9d64 (+ 48) 800c23a7 <kernel_x86>:vm_delete_address_space + 0x0033
15 a13f9d94 (+ 112) 80051e56 <kernel_x86>:team_delete_team + 0x0276
16 a13f9e04 (+ 192) 800558f7 <kernel_x86>:thread_exit + 0x03af
17 a13f9ec4 (+ 64) 8004a94d <kernel_x86>:handle_signals + 0x03d5
18 a13f9f04 (+ 64) 80055d74 <kernel_x86>:thread_at_kernel_exit + 0x0090
19 a13f9f44 (+ 100) 800d281b <kernel_x86>:kernel_exit_handle_signals + 0x0006
user iframe at 0xa13f9fa8 (end = 0xa13fa000)
eax 0x0 ebx 0x532ad4 ecx 0x7ffedde0 edx 0x246
esi 0x0 edi 0x415007 ebp 0x7ffede0c esp 0xa13f9fdc
eip 0xffff0104 eflags 0x207 user esp 0x7ffedde0
vector: 0x63, error code: 0x0
20 a13f9fa8 (+ 0) ffff0104 <commpage>:commpage_syscall + 0x0004
7ffede0c -- read fault
kdebug> vm
no completions
kdebug> cache
cache cache_info cache_tree caches
kdebug> cache 0x812f1a2c
CACHE 0x812f1a2c:
ref_count: 0
source: 0x00000000
type: RAM
virtual_base: 0x0
virtual_end: 0x1720000
temporary: 1
scan_skip: 0
lock: 0x812f1a7c
lock.holder: 10652
areas:
consumers:
pages:
5880 in cache
kdebug> cache_tree 0x812f1a2c
0x812f1a2c <--
kdebug> cache_info 0x812f1a2c
name: ÌÌÌÌ8/8/
lock: 0x812f1a54
object_size: 0
cache_color_cycle: 5880
used_count: 3435973632
empty_count: 2148653760
pressure: 3422552064
slab_size: 24248320
usage: 0
maximum: 0
flags: 0x0
cookie: 0xdeadbeef
kdebug> thread 10652
THREAD: 0x84199000
id: 10652 (0x299c)
name: "cc1plus"
all_next: 0x841c6800
team_next: 0x8418f800
q_next: 0x841ba800
priority: 20 (next 20, I/O: -1)
state: running
next_state: ready
cpu: 0x801374c0 (0)
sig_pending: 0x100000 (blocked: 0x0)
in_kernel: 1
fault_handler: 0x8005f1d4
args: 0x812f6ca8 0x00000000
entry: 0x80050430
team: 0x8119e198, "kernel_team"
exit.sem: 623256
exit.status: 0x0 (No error)
exit.reason: 0x1
exit.signal: 0x0
exit.waiters:
kernel_stack_area: 307181
kernel_stack_base: 0xa13f6000
user_stack_area: -1
user_stack_base: 0x7efee000
user_local_storage: 0x7ffee000
kernel_errno: 0x0 (No error)
kernel_time: 125913
user_time: 5972668
flags: 0x1
architecture dependant section:
esp: 0xa13f9df8
ss: 0x00000010
fpu_state at 0x841993e0
kdebug> mutex 0x812f1a7c
mutex 0x812f1a7c:
name: vm_cache
flags: 0x0
holder: 10652
waiting threads:
kdebug>
Leaving this box in KDL for now in case there's any other useful information I can pull out of this.
comment:10 by , 16 years ago
Further info from debug session with Ingo for reference:
kdebug> page 0x8236b0c8 PAGE: 0x8236b0c8 queue_next,prev: 0x8285e468, 0x823856d0 physical_number: c205 cache: 0x812f1a2c cache_offset: 3921 cache_next: 0x00000000 type: 0 state: active wired_count: 0 usage_count: 2 busy_writing: 0 area mappings: 0x812afe60 (0x1697) kdebug> area 0x1697 AREA: 0x812afe60 name: 'libtracker.so_seg0ro' owner: 0xb2 id: 0x1697 base: 0x595000 size: 0x195000 protection: 0x15 wiring: 0x0 memory_type: 0x0 cache: 0x81272d14 cache_type: vnode cache_offset: 0x0 cache_next: 0x00000000 cache_prev: 0x00000000 page mappings: 285 kdebug> cache_tree 0x81272d14 0x8127f348 0x81281364 0x8128b554 0x812a65d0 0x812db554 0x81272d14 <-- 0x81272b24 kdebug> area address 0x812ff0a0 AREA: 0x812ff0a0 name: 'heap' owner: 0x299c id: 0x4b015 base: 0x18000000 size: 0x1720000 protection: 0x33 wiring: 0x0 memory_type: 0x0 cache: 0x812f1a2c cache_type: RAM cache_offset: 0x0 cache_next: 0x00000000 cache_prev: 0x00000000 page mappings: 0
comment:11 by , 16 years ago
Might be fixed in hrev29992. Since I couldn't reproduce it, I'm leaving the ticket open for the time being. If anyone still encounters the bug, please add a comment.
comment:12 by , 16 years ago
| Milestone: | R1 → R1/alpha1 |
|---|---|
| Priority: | normal → high |
Just ran into it with hrev30345. Bumping priority and milestone.
comment:13 by , 16 years ago
Eliminated a possible cause in hrev30605. When a mapped file was shrunk, pages could be freed without removing their mappings. That would fit the reported case where the mapping was in a "libtracker.so_seg0ro" area, *if* libtracker.so was re-compiled and a program using it was still running. The other reported cases (TextSearch, nc) don't seem to fit, though. So I'm leaving the ticket open. I've introduced a new panic()ing check in hrev30606 which will hopefully trigger earlier.
comment:14 by , 16 years ago
I can reproduce this with kqemu. I've re-ported the current qemu version (0.10.4, using native APIs) and the corresponding kqemu. QEMU and kqemu work fine as long as they are running, but as soon as I close QEMU this panic happens. This package is hacked up a bit (QEMU requiring a more current GCC I compiled everything of QEMU with GCC4 but then used GCC2 for the native stuff, since QEMU is pure C however this does work). It's of course also possible that my kqemu driver is bogus, but I don't exactly understand how a driver would provoke this panic. The driver does use create/delete_area, lock/unlock_memory and get_memory_map. Could a lock_memory without a matching unlock_memory trigger this? You can get the package at http://haiku.mlotz.ch/qemu-0.10.4-haiku.zip for testing. You can view the driver source at http://haiku.mlotz.ch/kqemu-haiku.c . It is based on the previous BeOS version and doesn't make use of any Haiku specifics except for user_memcpy(). Just tell me if you want me to test anything in that regard.
follow-up: 16 comment:15 by , 16 years ago
Never mind, it's of course a bug in my kqemu. The initial lock_memory() runs in the context of the QEMU team, but later when the driver is closed the unlock_memory() is triggered from the kernel. Therefore the team_id has to be stored and unlock_memory_etc() has to be used.
The strange thing is that this exact same (broken) method worked before with the old kqemu of the old QEMU. My theory is that previously the driver was properly closed by QEMU when shutting down the emulation (so again inside the QEMU team context). This would also explain why this panic would occure when the emulation crashed (I think I remember to have seen it in that context). Right now it seems that the driver is not properly closed but instead the kernel cleans it up when the team goes down. This is probably related to some changes I need to adapt my port to again. Sorry for the noise.
The same kind of error could be responsible for this bug though. Seeing that it seems to always be triggered on program termination where the kernel would potentially clean up open handles. In case this is really the case debug output in unlock_memory() indicating the failed unlock should reveal that.
comment:16 by , 16 years ago
Replying to mmlr:
The same kind of error could be responsible for this bug though. Seeing that it seems to always be triggered on program termination where the kernel would potentially clean up open handles. In case this is really the case debug output in unlock_memory() indicating the failed unlock should reveal that.
lock_memory() increments the page's wired_count. In the instances of this bug where we've had a closer look at the page, it still had a mapping in a completely unrelated area, though, so they can't be lock_memory() related.
That aside, there are also still TODO's in lock_memory_etc() which should be tackled eventually. E.g. currently it is possible to delete or shrink an area with locked memory, which will create wired free pages. Unless caused on purpose, it's rather unlikely that this happens in practice, though.
follow-ups: 18 19 comment:17 by , 16 years ago
I can confirm that this still happens as of hrev30852 in the gcc2 build and can consistently reproduce the trip to KDL by compiling a project with a build of Paladin compiled from within Haiku.
comment:18 by , 16 years ago
comment:19 by , 16 years ago
Replying to darkwyrm:
I can confirm that this still happens as of hrev30852 in the gcc2 build and can consistently reproduce the trip to KDL by compiling a project with a build of Paladin compiled from within Haiku.
Great! Can you give detailed instructions how to reproduce it, including all the necessary files, please.
comment:20 by , 16 years ago
Absolutely. Tested with hrev30907:
1) Download and install Paladin RC6 -- http://www.bebits.com/bob/22146/Paladin1.0rc6.pkg.zip 2) Create /boot/home/projects folder 3) Open a Terminal and go to ~/projects. 4) $ unzip testproject.zip; cd BePhotoMagic 5) $ /boot/apps/Paladin/Paladin BePhotoMagic.pld 6) Hit Alt-M to run a build.
Sometimes it will KDL on the first build attempt after it has progressed most of the way through the build. Sometimes Paladin craps out on an error. In such cases, restarting the build causes it to KDL almost immediately after the restart.
The test rig is a P4 Xeon 3Ghz with Hyperthreading and 1GB RAM in the event SMP is a factor.
comment:21 by , 16 years ago
| Owner: | changed from to |
|---|---|
| Status: | new → assigned |
Sweet, could just reproduce it in VMware. Looking into it.
comment:22 by , 16 years ago
Can't reproduce in hrev30911 anymore. Might be related to the more defensive mapping in vm_soft_fault(). Trying to understand the original problem...
comment:23 by , 16 years ago
| Resolution: | → fixed |
|---|---|
| Status: | assigned → closed |
Analyzed the problem with Paladin: Two threads of the same team simultaneously fault on the same virtual page, one write the other read. The write fault is handled first, the read fault maps the same page again, adding a second page mapping. Then do a fork(), which moves the cache one level lower and changes the page mappings to read-only. Another write fault in the original team unmaps the page -- removing only one mapping! -- and adds a fresh page in the top-most cache. When the child team exec()s, the top-most cache is merge with its source (the one with the "bad" page). Since the page is shadowed it is ignored while merging and removed when the cache is deleted, triggering the panic, since it still has the invalid mapping.
Long story short: Simultaneous page faults are handled gracefully in hrev30911, so this problem is indeed fixed. It also seems like a good enough explanation for the other reported situations, so I'm closing this bug. Since it's already the third fixed bug which triggered the panic(), please create a new ticket, if encountered again.
I reproduced it again after opening and closing random results of that search in Pe about 10-20 times.