

#6034 closed bug (fixed)
BFS Panics
| Reported by: | bryanv | Owned by: | axeld |
|---|---|---|---|
| Priority: | critical | Milestone: | R1 |
| Component: | File Systems/BFS | Version: | R1/alpha2 |
| Keywords: | Panics | Cc: | agmsmith@… |
| Blocked By: | Blocking: | #7815 | |
| Platform: | x86 |
Description
I have an IMAP account with 20,000+ emails stored.
During synchronization (downloading from the IMAP server to the local disk) I reliably get a BFS Panic. The stack traces are always similar to the one attached.
Let me know if there's anything else I can do in the KDL to gather information on this one.
Oh, and this occurs in VirtualBox _and_ on the bare hardware.
Attachments (3)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (30)
by , 15 years ago
| Attachment: | BFS_Panic.png added |
|---|
follow-up: 2 comment:1 by , 15 years ago
That one looks to have been triggered by haiku/trunk/src/add-ons/kernel/file_systems/bfs/BPlusTree.cpp#L1170.
comment:2 by , 15 years ago
Replying to anevilyak:
That one looks to have been triggered by haiku/trunk/src/add-ons/kernel/file_systems/bfs/BPlusTree.cpp#L1170.
With 20,000+ emails files created in the inbox folder, could we bet BPLUSTREE_MAX_KEY_LENGTH limit is hit here?
comment:3 by , 15 years ago
Quite possibly, bear in mind though, that's just for the length of a single key (keys are 256 bytes w/ null terminator just like filenames), it's not a limit on the number of files in the directory per se.
comment:4 by , 15 years ago
There are not that many files in one folder, that's my entire mailbox (all subdirectories, etc.).
It downloads (successfully) about 100 files (each time) before it fails.
comment:5 by , 15 years ago
Yeah, the problem appears to be that it tries to generate a new unique key to put in the index, but overruns the key length limit in the process. Axel can confirm for sure when he gets back tomorrow though, I'm guessing this is only an issue with (extremely) long file names that are already close to the BFS filename length limit.
follow-up: 7 comment:6 by , 15 years ago
| Priority: | normal → critical |
|---|
This looks like a bug in the BPlusTree code. Can you add some debug output that reveals the variables involved? Something like:
panic("Volume: %p, header: %p, droppedKey: %p, in: %u, node: %p, newLength: %u\n",
fStream->GetVolume(), &fHeader, ...);
And then in KDL, it would be nice to see the output of:
bfs_btree_node <node> <header> <volume>
comment:7 by , 15 years ago
I was using the pre-built R1A2 image, and don't have a build environment setup at the moment...
comment:8 by , 15 years ago
Bummer, but would you be able to test this when I provide the changed bfs add-on here?
comment:11 by , 13 years ago
| Resolution: | → duplicate |
|---|---|
| Status: | new → closed |
This should be resolved with Axel's recent BFS changes. checkfs also can repair BTree's now.
If anyone still encounters this issue post hrev43930, please let us know so we can re-open this bug.
comment:12 by , 13 years ago
| Resolution: | duplicate |
|---|---|
| Status: | closed → reopened |
comment:13 by , 10 years ago
| Cc: | added |
|---|
by , 10 years ago
| Attachment: | 20141022 BFS Panic when writing attributes.jpeg added |
|---|
BFS Panic when Writing Indexed Attributes 20141022
comment:14 by , 10 years ago
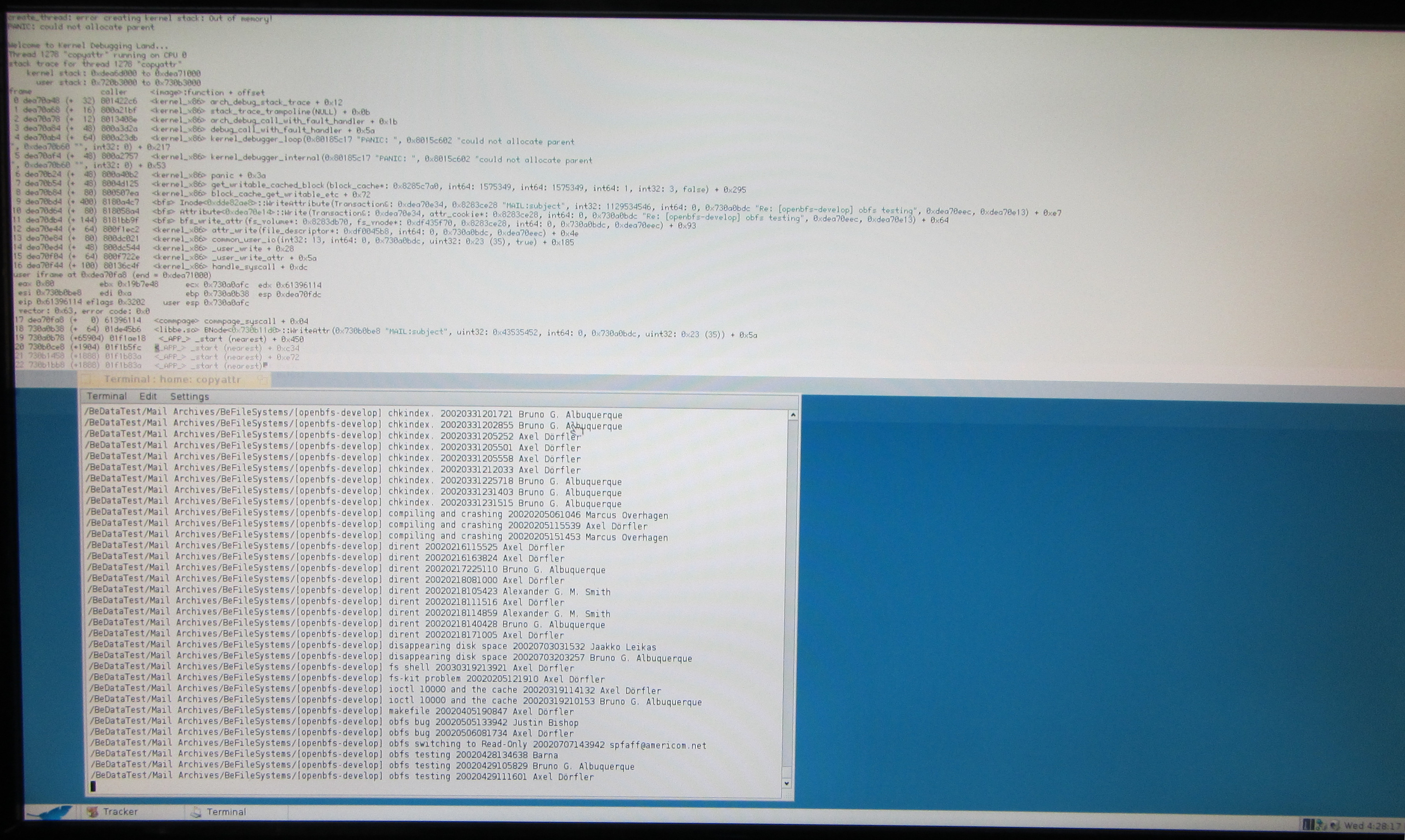
It's still reliably suffering from a Panic when writing files in BFS. Usually I get something in the BTree code, but this time it's in the block cache. Running on hrev48061 with real hardware. I was copying my e-mail collection to a freshly formatted BFS volume, with e-mail indices set up.
The debugger crashed during the stack crawl, going into an infinite loop printing out something about bad command lines followed by many lines of zeros, over and over again, but that's a different bug.
comment:15 by , 10 years ago
That last panic report is mostly due to something else - mounting a raw disk image file on ext4 containing a BeOS disk volume seems to corrupt the kernel memory list. Guess loopback mounting doesn't work well with those file systems. Tried again with a real disk partition for the BeOS BFS source data.
But I still get bugs copying e-mail to Haiku. It looks like something is wrong with BPlusTree or the way it writes data (caching?). It manages to mangle the attribute index while copying files (just did a copyattr -r -d -v of a few thousand old e-mails). The destination was a freshly formatted install of hrev48061, with mail indices created. This is what the log looks like, mixed with output from the file copying and a later checkfs:
/boot/home/Mail Archives/Champlain Speaker/Mail System Error - Returned Mail 20070912213055 Mail Administrator /boot/home/Mail Archives/Champlain Speaker/Mail System Error - Returned Mail 20071126212315 Mail Administrator KERN: bfs: invalid node [0xf3923400] read from offset 343040 (block 8103), inode at 5588 KERN: bfs: KERN: BPlusTree::_SeekDown() could not open node 343040, inode 5588 KERN: bfs: Insert:1692: General system error KERN: bfs: Update:279: General system error KERN: bfs: invalid node [0xf3923400] read from offset 343040 (block 8103), inode at 5588 KERN: bfs: KERN: BPlusTree::_SeekDown() could not open node 343040, inode 5588 KERN: bfs: Insert:1692: General system error KERN: bfs: Update:279: General system error [zillions more of the same, a pause, then the file copying continues, then it happens again]
~> checkfs /boot/ MAIL:to (inode = 5588), invalid b+tree Recreating broken index b+trees...
10264 nodes checked, 0 blocks not allocated, 0 blocks already set, 0 blocks could be freed
files 10105 directories 161 attributes 39 attr. dirs 28 indices 24
direct block runs 10456 (2.10 GiB) indirect block runs 362 (in 9 array blocks, 5.94 GiB) double indirect block runs 0 (in 0 array blocks, 0 bytes)
~> KERN: bfs: invalid node [0xf3923400] read from offset 343040 (block 8103), inode at 5588 KERN: inode 5588: node at 343040 could not be read: Bad data KERN: inode 5588: node at 6144 has wrong left link 306176, expected 38912! KERN: inode 5588: node at 30720 has wrong right link 249856, expected 344064! KERN: inode 5588: node at 344064 has wrong left link 253952, expected 30720! KERN: inode 5588: visited 234 from 351 nodes. KERN: bfs: ReadAttribute:1070: No such file or directory KERN: Last message repeated 987 times.
comment:16 by , 10 years ago
Are you to able to in some way provide an image of the source filesystem that reliably reproduces this problem? Also, you're certain that the described source partition isn't also corrupted in some way? That happened to me on numerous occasions with R5, so it's certainly not immune to such problems as well.
comment:17 by , 10 years ago
I was thinking of making anonymized versions of the e-mails for a repeatable test, but ran into the problem of the sorting order of the e-mails changing if I modified To/From/etc in the attribute values. So, no convenient public test data.
Yes, I'm pretty sure the source data is fine. Though I could try zipping up the e-mails in 4GB chunks (Zip file limit) and unzipping to avoid worries of old BFS being a problem. Hmmm, I'll try that right now, and test as well with a Haiku BFS volume with no indices (just in case it is a simpler attribute writing problem). More later...
comment:18 by , 10 years ago
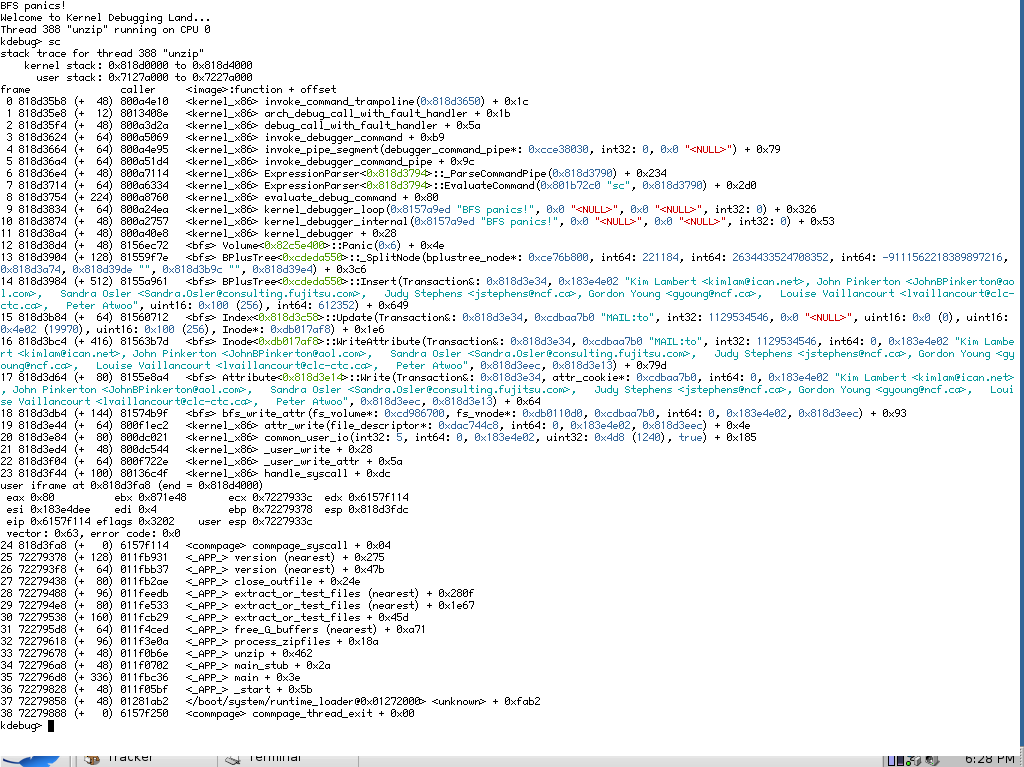
Yes, it happens even if unzipping e-mail files from an MSDOS disk volume to the Haiku volume. So it's not the source data. And it doesn't happen if the Haiku volume has no indices (formatted without query support). I was able to capture a crash where the debugger was still working, and this one is in BPlusTree::_SplitNode (see attached screen shot).
by , 10 years ago
| Attachment: | 20141022 BFS Panic with Attribute Writing.png added |
|---|
BFS Panic in BPlusTree::_SplitNode when writing attributes.
follow-up: 22 comment:19 by , 10 years ago
What you could do is the following:
- strip down the mail selection in the zip as much as possible so that it will still trigger the bug.
- truncate all the mail files.
- remove all attributes that do not trigger the bug, ie. in this case everything but
MAIL:to.
If the final data can still reproduce the issue, and you're willing to trust me your meta data, you could make that zip available to me.
follow-up: 21 comment:20 by , 10 years ago
I'm not sure this is triggered by the attribute data itself. At least the photo in the second attachement leaked the syslog output "error creating kernel stack: out of memory" into the KDL output, followed by the panic "could not allocate parent" (a block cache panic). So the circumstances may be the same as in #10312, the block cache using up all the address space (not the actual pages) after reading/writing enough blocks. Outputting the low resource state in KDL at that point would verify this.
A theory I recently discussed with Rene would be that in such a situation some allocations may fail, but those failures not properly leading to aborting the transactions. In such a case incomplete or bogus transactions might be written back.
I was not able to reproduce the out of address space errors when running in a memory constrained VM, because there the low resource handler for pages kicks in first and cleans out stuff so the situation is never reached. When running checkfs on the real machine directly, I was easily able to trigger the out of address space errors because there are enough pages for the address space shortage to trigger first. It should be possible to waste some address space by allocating big B_NO_LOCK areas, which then should make these situations more easy to trigger and investigate.
comment:21 by , 10 years ago
Replying to mmlr:
I'm not sure this is triggered by the attribute data itself. At least the photo in the second attachement leaked the syslog output "error creating kernel stack: out of memory" into the KDL output, followed by the panic "could not allocate parent" (a block cache panic).
That was due to mounting a file on an ext2 volume (rather than a device) as a BFS volume. The file was a dump of my old BeOS disk partition. Something's gone goofy there, corrupting the kernel memory system and making it be out of memory immediately.
The panic and problems with attribute indices is something else, happens even without odd mounted file systems.
- Alex
comment:22 by , 10 years ago
Replying to axeld:
What you could do is the following:
Done. Check your e-mail for a 10 megabyte message, with a 7 megabyte .zip file attached. It has just the MAIL:to attribute for each e-mail (17000 of them) and obfuscated file names and no other content. Please keep it private.
It reliably causes the BFS indexing failure (watch the syslog while unzipping for corrupted node messages), not necessarily always causing a panic. Checkfs also finds those corrupted nodes. Of course, you need the MAIL:to index on the volume you are unzipping the e-mails to, otherwise it works without problems. Unzipping under BeOS works just fine.
follow-up: 24 comment:23 by , 10 years ago
| Status: | reopened → in-progress |
|---|
Just FTR: I've solved the issue in my working tree, but haven't gotten around to clean it up and commit yet. The problem is in BPlusTree::_SplitNode() that does not take the current key length into account when distributing the keys to the two target nodes. If the two last keys are very long, they can be longer than the 1024 bytes of the node, and even clobber the memory afterwards.
comment:24 by , 10 years ago
Replying to axeld: Speaking of long keys, watch out for string keys that are UTF-8 and have a multibyte character split at the 256 byte index truncation limit. Comparing those strings may read past the end of the buffer even if you stuck a NUL byte at the end. Should be safe with 4 NULs appended when doing the comparison. I don't know if the existing code handles that case.
comment:25 by , 10 years ago
| Resolution: | → fixed |
|---|---|
| Status: | in-progress → closed |
Fixed in hrev48702.
BFS doesn't do UTF-8 aware string comparison yet.
comment:26 by , 10 years ago
I was able to copy my mail collection to a fresh partition in Haiku hrev48702, and it didn't crash! Though query parsing is broken, but that will be a different ticket.
KDL stack strace