

#8454 closed bug (fixed)
Very low network performance on some Marvell Yukon cards.
| Reported by: | bga | Owned by: | nobody |
|---|---|---|---|
| Priority: | normal | Milestone: | R1/beta2 |
| Component: | Drivers/Network/marvell_yukon | Version: | R1/Development |
| Keywords: | Cc: | luroh, jstressman@… | |
| Blocked By: | #8743 | Blocking: | #8928 |
| Platform: | All |
Description
It has been a long time since I last used Haiku but I recently started using it again. I noticed there has been a huge network performance regression (more likelly, with my specific card as someone else would have noticed it if the problem was more general).
Here is my card:
/dev/net/marvell_yukon/0
Hardware type: Ethernet, Address: 00:1e:8c:3a:65:24
Media type: 1 GBit, 1000BASE-T
inet addr: 192.168.0.11, Bcast: 192.168.0.255, Mask: 255.255.255.0
inet6 addr: fe80::21e:8cff:fe3a:6524, Bcast:
ffff:ffff:ffff:ffff::, Prefix Length: 64
MTU: 1500, Metric: 0, up broadcast link auto-configured
Receive: 5880 packets, 0 errors, 4661150 bytes, 0 mcasts, 0 dropped
Transmit: 2737 packets, 0 errors, 253011 bytes, 0 mcasts, 0 dropped
Collisions: 0
As you can see it is connected to a Gigabit ethernet network and the speed is not getting even close to that. And when I say not even close I do not say I am getting 10 Mbits or something. I am getting amazing 425 Kbits! or 52 kb/s in the local network. The same machine also runs Linux and when booted to it, I get around 40 mb/s of transfer speed.
Also, ping times are surreal:
[/boot/home]> ping 192.168.0.1 PING 192.168.0.1 (192.168.0.1): 56 data bytes 64 bytes from 192.168.0.1: icmp_seq=0 ttl=64 time=333.856 ms 64 bytes from 192.168.0.1: icmp_seq=1 ttl=64 time=334.960 ms 64 bytes from 192.168.0.1: icmp_seq=2 ttl=64 time=336.313 ms 64 bytes from 192.168.0.1: icmp_seq=3 ttl=64 time=337.703 ms 64 bytes from 192.168.0.1: icmp_seq=4 ttl=64 time=339.046 ms 64 bytes from 192.168.0.1: icmp_seq=5 ttl=64 time=340.501 ms 64 bytes from 192.168.0.1: icmp_seq=6 ttl=64 time=341.911 ms 64 bytes from 192.168.0.1: icmp_seq=7 ttl=64 time=343.321 ms 64 bytes from 192.168.0.1: icmp_seq=8 ttl=64 time=344.734 ms 64 bytes from 192.168.0.1: icmp_seq=9 ttl=64 time=346.066 ms 64 bytes from 192.168.0.1: icmp_seq=10 ttl=64 time=347.479 ms --- 192.168.0.1 ping statistics --- 11 packets transmitted, 11 packets received, 0% packet loss round-trip min/avg/max/std-dev = 333.856/340.535/347.479/4846.743 ms
On Linux on the same machine, the same ping results in sub-ms reply time, so this is aroung 500 times slower!
Also notice this card use the FreeBSD compatibility layer. It is possible that the problem is there.
Attachments (6)
{kind=link}
{kind=link}
Change History (72)
comment:1 by , 13 years ago
comment:2 by , 13 years ago
| Cc: | added |
|---|
comment:3 by , 13 years ago
Similar issues here, Marvel Technology Group Ltd. 88E8056 PCI-E Gigabit Ethernet Controller [11ab:4364]
follow-up: 5 comment:4 by , 13 years ago
Did the problem start around hrev43744?
After running a fresh coverity scan, it seems it has detected a bad conditional check in the new HAIKU_CHECK_DISABLE_INTERRUPTS() code:
if (status == 0 || status == 0xffffffff ||
Where status is apparently a uint16, so the second condition will always be false.
It's CID 11358 if anyone is interested in checking on it.
comment:5 by , 13 years ago
Replying to umccullough:
Did the problem start around hrev43744?
After running a fresh coverity scan, it seems it has detected a bad conditional check in the new HAIKU_CHECK_DISABLE_INTERRUPTS() code:
if (status == 0 || status == 0xffffffff ||Where status is apparently a uint16, so the second condition will always be false.
It's CID 11358 if anyone is interested in checking on it.
Looking again at the code, it should be: uint32_t status;
comment:7 by , 13 years ago
Unfortunately, that did not help. I am still seeing the same abysmal performance.
comment:8 by , 13 years ago
comment:9 by , 13 years ago
looks like the concept of "status" is a bit overloaded in this driver. There seem to be at least 2 interrupt handlers:
static void
msk_intr_phy(struct msk_if_softc *sc_if)
{
uint16_t status;
msk_phy_readreg(sc_if, PHY_ADDR_MARV, PHY_MARV_INT_STAT);
status = msk_phy_readreg(sc_if, PHY_ADDR_MARV, PHY_MARV_INT_STAT);
/* Handle FIFO Underrun/Overflow? */
if ((status & PHY_M_IS_FIFO_ERROR))
device_printf(sc_if->msk_if_dev,
"PHY FIFO underrun/overflow.\n");
}
and
static void
msk_intr_gmac(struct msk_if_softc *sc_if)
{
struct msk_softc *sc;
uint8_t status;
sc = sc_if->msk_softc;
status = CSR_READ_1(sc, MR_ADDR(sc_if->msk_port, GMAC_IRQ_SRC));
/* GMAC Rx FIFO overrun. */
if ((status & GM_IS_RX_FF_OR) != 0)
CSR_WRITE_4(sc, MR_ADDR(sc_if->msk_port, RX_GMF_CTRL_T),
GMF_CLI_RX_FO);
/* GMAC Tx FIFO underrun. */
if ((status & GM_IS_TX_FF_UR) != 0) {
CSR_WRITE_4(sc, MR_ADDR(sc_if->msk_port, TX_GMF_CTRL_T),
GMF_CLI_TX_FU);
device_printf(sc_if->msk_if_dev, "Tx FIFO underrun!\n");
/*
* XXX
* In case of Tx underrun, we may need to flush/reset
* Tx MAC but that would also require resynchronization
* with status LEs. Reinitializing status LEs would
* affect other port in dual MAC configuration so it
* should be avoided as possible as we can.
* Due to lack of documentation it's all vague guess but
* it needs more investigation.
*/
}
}
As you can see, status is 8 bits in one, 16 bits in the other and the last CL changed the status somewhere else to 32 bits. i wonder if this is not causing the issues.
In any case, I am not familiar with the FreeBSD compatibility layer. Any ideas which of the interrupt handlers should I be checking the status in? My guess would be the second one.
comment:10 by , 13 years ago
The interrupt handler of interest is the one passed to bus_setup_intr() which is msk_intr.
comment:11 by , 13 years ago
If it's of any help, a kernel thread called "mskc intr handler" is consuming ~40% CPU on my machine, causing a noticable general slowdown and UI sluggishness. Lowering its priority from "Real-time" to "Lowest" gets rid of the sluggishness, but has a further negative impact on the network performance.
comment:12 by , 12 years ago
I just noticed the cpu usage by "mskc intr handler". This is a new development though as when I reported the bug, that did not happen. Maybe it was the change in the status code that caused it?
comment:13 by , 12 years ago
Ok, I think I partially figured it out. And right now I have no high CPU usage when nothing is happening nor do I have the huge network slowdown:
~> ping -c 10 192.168.0.1 PING 192.168.0.1 (192.168.0.1): 56 data bytes 64 bytes from 192.168.0.1: icmp_seq=0 ttl=64 time=0.471 ms 64 bytes from 192.168.0.1: icmp_seq=1 ttl=64 time=0.412 ms 64 bytes from 192.168.0.1: icmp_seq=2 ttl=64 time=0.406 ms 64 bytes from 192.168.0.1: icmp_seq=3 ttl=64 time=0.434 ms 64 bytes from 192.168.0.1: icmp_seq=4 ttl=64 time=0.410 ms 64 bytes from 192.168.0.1: icmp_seq=5 ttl=64 time=0.386 ms 64 bytes from 192.168.0.1: icmp_seq=6 ttl=64 time=0.379 ms 64 bytes from 192.168.0.1: icmp_seq=7 ttl=64 time=0.377 ms 64 bytes from 192.168.0.1: icmp_seq=8 ttl=64 time=0.386 ms 64 bytes from 192.168.0.1: icmp_seq=9 ttl=64 time=0.390 ms --- 192.168.0.1 ping statistics --- 10 packets transmitted, 10 packets received, 0% packet loss round-trip min/avg/max/std-dev = 0.377/0.405/0.471/0.213 ms
From around 340 ms to 0.4 ms ping times. Not bad. :)
But not everything is perfect:
~> scp bga@blindio:Misc/Backup.zip . bga@blindio's password: Backup.zip 100% 103MB 5.4MB/s 00:19
Transfer speeds are a lot better, but they can improve more (I get up to 40 mb/s with Linux). Also, when transfering I see high CPU usage from the interrupt handler.
Also, while I was writting this, CPU usage spiked and syslog is showing lots of errors:
KERN: [marvell_yukon] (mskc) Rx descriptor error KERN: [marvell_yukon] (mskc) Tx descriptor error KERN: Last message repeated 6807 times. KERN: [marvell_yukon] (mskc) Rx descriptor error KERN: [marvell_yukon] (mskc) Tx descriptor error KERN: Last message repeated 34751 times. KERN: [marvell_yukon] (mskc) Rx descriptor error KERN: [marvell_yukon] (mskc) Tx descriptor error KERN: Last message repeated 33358 times. KERN: [marvell_yukon] (mskc) Rx descriptor error
So something is still broken.
In any case, what I did was simply remove the interrupt disabling code at the top of msk_intr(). If I understand this correctly, this is now handled by HAIKU_CHECK_DISABLE_INTERRUPTS() which had identical code.
Korli, can you comment on this? note this was simply a wild guess when I saw the duplicated code.
comment:14 by , 12 years ago
So, although I removed the interrupt disabling code, I forgot to remove the code that reenabled them. I did that and now the errors stopped. *BUT* ping is up now (around 200 ms) and the netowkr performance went down the drain again (altough it is also betetr than with the original code).
Taking this into consideration, could it be that we are not reenabling interrupts somewhere when we should? Mode specifically, I did notice that the glue code does not have any code to reenable interrupts. Maybe it should have?
by , 12 years ago
| Attachment: | marvell_yukon.patch added |
|---|
comment:15 by , 12 years ago
Ok. Attached patch seems to fix everything. Performance is still sub-optimal, but it seems to be as good as it ever was (before it got really really bad). I did not set up git for Haiku development yet, so i need someone else to apply this. Thanks.
comment:16 by , 12 years ago
| patch: | 0 → 1 |
|---|
follow-up: 30 comment:17 by , 12 years ago
*sigh*
Do not apply the patch. I just got the errors again and the high CPu usage (probably due to the errors. I will continue investigating, but I am out of ideas.
comment:19 by , 12 years ago
Thanks korli, no perceivable difference with the patch here unfortunately. [11ab:4362]
comment:20 by , 12 years ago
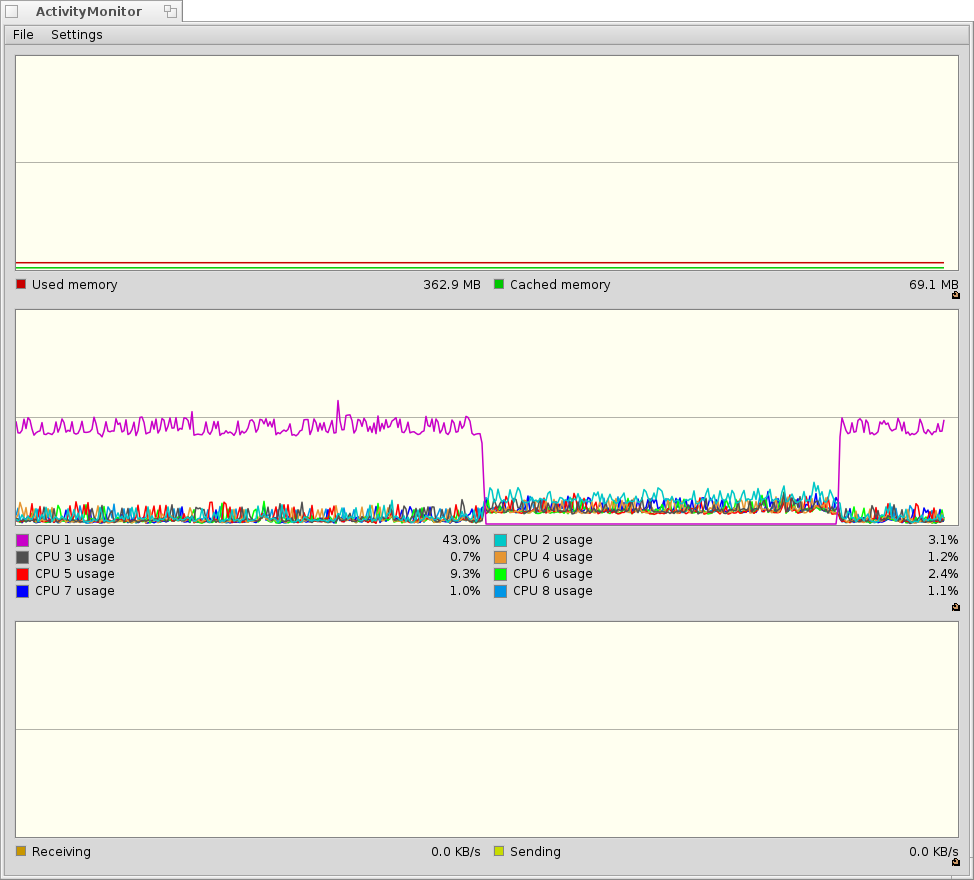
I wanted to add a note to this regarding some odd behavior with the CPU load in relation to this problem as well... (hrev44293 clean install)
I'm running a multi-core system, but the load is only going on the first core. The other 7 are left essentially totally idle. If I disable the first core, the load appears to go back to normal with the load being balanced over all my cores.
(See attached image where it's obvious the span where I disabled the first core momentarily and then re-enabled it.)
by , 12 years ago
| Attachment: | haiku-cpu-bug1.png added |
|---|
temporarily disabled the first core which caused the load to go back to normal balancing
comment:21 by , 12 years ago
| Cc: | added |
|---|
comment:22 by , 12 years ago
To hopefully alleviate some of the inconvenience, I am attaching the last known good drivers, extracted from nightly images hrev43722.
comment:23 by , 12 years ago
| Blocked By: | 8743 added |
|---|
comment:24 by , 12 years ago
I'm still seeing the same high CPU load on hrev44370
I've gone back to the old driver again and things work correctly with it. I'll try again when someone thinks they have this fixed.
Is there anything else I can do to help get this figured out?
comment:25 by , 12 years ago
I think the performance may be low for all network drivers (at least wlan) based on FreeBSD compability code. Why I don't know.
comment:26 by , 12 years ago
Do you mean it's low since we updated to the FreeBSD 9 drivers, or low in general. At least the latter I can't confirm - I'm still using an older revision, and network speed is quite acceptable (actually better than with Linux on the same machine).
comment:27 by , 12 years ago
Since I havn't been using wlan under Haiku that much before I can't really say. My intel 4965 is not getting better than around 100KB/s at the moment (wget or WebPositive is the same), and some reports is that it is similar with Marvell yukon. CPU usage isn't that high either, I've enabled more debugging in wlan-code and see retransmit messages, but not sure if that is ordinary or not.
I'm away from home right now so can't do that much to investigate.
comment:28 by , 12 years ago
One other thing for me that seemed to really improve responsiveness and performance was to disable my 2 interfaces that I wasn't using.
I disabled atheros0 and marvell_yukon0 and only use marvell_yukon1.
I'd have to do more testing to see if I could give a more solid explanation of this and confirm that it is indeed the case... but Web+ at least seemed to respond considerably quicker and more smoothly once I'd disabled the unused interfaces.
I'm still using the old driver at the moment, so I'd want to retest this to figure out whether it was the new driver or the old driver that I saw this behavior under... and if it's really related to the driver at all, or some kind of bad routing, or just Web+ trying an invalid interface before timing out and trying a good one... or even something like trying an invalid ipv6 route before falling back to a working ipv4... I really have no idea at the moment, but wanted to point out what I thought I saw in case it gives anyone an idea.
One other idea I had was that it was related to the atheros driver spitting out 1kB a second in verbose logs to the syslog, and disabling that interface shut it up and increased performance on my remaining interface(s)?
comment:29 by , 12 years ago
| patch: | 1 → 0 |
|---|
comment:30 by , 12 years ago
Replying to bga:
*sigh*
Do not apply the patch. I just got the errors again and the high CPu usage (probably due to the errors. I will continue investigating, but I am out of ideas.
Obsoleted the patch per request of bga.
follow-up: 35 comment:31 by , 12 years ago
I havn't verified this but I suspect that the freebsd drivers (marvell_yukon, iprowifi4965 and others) that use fake interrupt handlers involving semaphore signaling and a thread doing the real int work are the slow ones. The rtl81xx which uses the int handler directly seems to have pretty good performance. For iprowifi4965 I think rewriting the int handler would be quite easy and would be a good test for this. See http://cgit.haiku-os.org/haiku/tree/src/libs/compat/freebsd_network/bus.c#320 for more info. It will take me a few days before I can get to that though.
comment:32 by , 12 years ago
In the interest of chronicling the misadventures of this driver, I have to report that since hrev44541, the driver now locks up my system when configuring the NIC at boot. The mouse pointer can't be moved but I can get to KDL, where it always seems to be stuck in "mskc intr handler".
comment:33 by , 12 years ago
| Milestone: | R1 → R1/alpha4 |
|---|
Using 'msi_disable = 1' in if_msk.c makes the driver not lock up the system, but otherwise doesn't seem to improve performance in any way.
There's a suggestion to inject binary versions of the last known good drivers into the official R1/A4 images as a workaround, unless this bug has been fixed until release. I'm therefore adjusting the milestone to R1/A4 for now to make it show up on the release radar.
comment:34 by , 12 years ago
| Blocking: | 8928 added |
|---|
follow-up: 37 comment:35 by , 12 years ago
Replying to tqh:
I havn't verified this but I suspect that the freebsd drivers (marvell_yukon, iprowifi4965 and others) that use fake interrupt handlers involving semaphore signaling and a thread doing the real int work are the slow ones. The rtl81xx which uses the int handler directly seems to have pretty good performance. For iprowifi4965 I think rewriting the int handler would be quite easy and would be a good test for this. See http://cgit.haiku-os.org/haiku/tree/src/libs/compat/freebsd_network/bus.c#320 for more info. It will take me a few days before I can get to that though.
@tqh: Can you take this one and determine if it can be fixed for r1alpha4 or pushed out to the next milestone? Perhaps roll this back to the last know mostly working version?
follow-up: 38 comment:36 by , 12 years ago
Last time I was plodding around with this bug, I remember looking into the possibility of reverting but it seemed to be non-trivial (at least given my limited knowledge). Not only the driver itself but the compat layer as well would need to be rolled back, which would affect all other freebsd Ethernet drivers.
In order to not jeopardize release quality or to risk losing much time over this, I would propose that we simply manually inject the attached working gcc2 binary driver into the release images and defer this ticket to alpha 5, once alpha 4 is out the door.
comment:37 by , 12 years ago
Replying to scottmc:
@tqh: Can you take this one and determine if it can be fixed for r1alpha4 or pushed out to the next milestone? Perhaps roll this back to the last know mostly working version?
No I can't since I don't have the hardware. I've been trying to investigate why some FreeBSD-based drivers are slow and others not. I suspect it is the different int handlers in FreeBSD-code but I havn't managed to prove that. IIRC, Atheros is fast, Realtek is fast, Marvell and i4965 is slow. I'm planning to open an enhancement ticket on networking, but havn't gotten round to it yet.
follow-ups: 39 40 comment:38 by , 12 years ago
Replying to luroh:
Last time I was plodding around with this bug, I remember looking into the possibility of reverting but it seemed to be non-trivial (at least given my limited knowledge). Not only the driver itself but the compat layer as well would need to be rolled back, which would affect all other freebsd Ethernet drivers.
In order to not jeopardize release quality or to risk losing much time over this, I would propose that we simply manually inject the attached working gcc2 binary driver into the release images and defer this ticket to alpha 5, once alpha 4 is out the door.
Given you think reverting the source would be non-trivial and would require changing the compat layer, why would injecting the old binary version work? Is the compat layer compiled into each driver? If it is not, I don't see how the old binary driver could work with the new compat layer.
If the compat layer is compiled in, then I'll explore this option. Unfortunately I don't think I have any hardware I can test on, but maybe I could provide a test image or patch to luroh.
comment:39 by , 12 years ago
Replying to leavengood:
Given you think reverting the source would be non-trivial and would require changing the compat layer, why would injecting the old binary version work? Is the compat layer compiled into each driver?
The old binary does work fine and I believe the reason is indeed that the compat layer is compiled into each driver, adjusted as necessary when we upgrade our drivers from one FreeBSD version to another. It is beyond my meager knowledge to explore this option further myself but I'll gladly test any patches.
comment:40 by , 12 years ago
Replying to leavengood:
If the compat layer is compiled in, then I'll explore this option. Unfortunately I don't think I have any hardware I can test on, but maybe I could provide a test image or patch to luroh.
It is, the compat layer is built into a .a which is statically linked into every freebsd-derived driver (c.f. http://cgit.haiku-os.org/haiku/tree/src/libs/compat/freebsd_network/Jamfile#n15 ).
comment:41 by , 12 years ago
I suspect the older ones will have other problems with port sensing and such, unless you try to compile old driver with new compability layer. Someone with good knowledge about interrupt handling and locking in FreeBSD could probably try to improve our layer's interrupt handling. Otherwise I think it would be good to discuss on how to improve at BG.
comment:42 by , 12 years ago
| Milestone: | R1/alpha4 → R1/beta1 |
|---|
We are too close to R1A4 to fix this now. It looks like this won't be fixed until post-R1A4 :(
comment:43 by , 12 years ago
As I don't have the hardware I can't really test it, but from what I gathered from the discussion here and how I understood HAIKU_CHECK_DISABLE_INTERRUPTS() the duplicated entry in the interrupt handler needs to be disabled (as the original patch from Bruno did). However the patch did just remove the duplicate code, which should have left the status variable empty and the rest of the interrupt handler moot.
As with the duplicate code in place things broke, I would guess that it is possible that reading the status twice might return different results. Since reading the register also has the side effect of masking further interrupts (as indicated by the comment), this seems possible as well. Since I don't have the register specs I can only guess however.
In any case I've made two patches that may help here. The first patch ifdefs the duplicate code out but carries over the status value from check/disable to the interrupt handler as is done in other drivers.
The second patch is inspired by the FreeBSD workaround Jerome point to, but does the check and acknowledge of the possible spurious interrupt at a different place that should actually be reached in the interrupt storm case.
by , 12 years ago
| Attachment: | 0001-Disable-duplicated-interrupt-disable-code.patch added |
|---|
comment:44 by , 12 years ago
| patch: | 0 → 1 |
|---|
by , 12 years ago
| Attachment: | 0002-Workaround-possible-spurious-interrupts-in-marvell-y.patch added |
|---|
follow-up: 46 comment:45 by , 12 years ago
Thanks mmlr, I'll give these a go tomorrow. Should each patch be tested separately and/or combined?
comment:46 by , 12 years ago
Replying to luroh:
Thanks mmlr, I'll give these a go tomorrow. Should each patch be tested separately and/or combined?
Both should be applied combined. I just separated them to make the changes more easy to see.
comment:47 by , 12 years ago
Let us know how it goes luroh. If they solve the issue (or make it better) they will get a quick pass into R1A4.
Thanks mmlr!
comment:48 by , 12 years ago
I and oco tried both patches on oco's sony laptop, and it seems they don't help at solving the current problem, sorry.
We managed to narrow the high CPU load to an interrupt looping in msk_handle_events(). The driver is supposed to have some events to process (line 3510, test is false) but the first event at the current position is still hardware owned (line 3523, test is true). Thus msk_handle_events() returns with still some work to do, this triggers an interrupt which in turn calls msk_handle_events() again.
Tests so far give a value for sc->msk_stat_cons of 512 or 1024, when the high CPU load is triggered. It seems to be linked with a crossed page boundary (the size of an event is 8 bytes).
comment:49 by , 12 years ago
Wow, these patches really worked wonders for my box. My yukon went from completely hanging the system to working just as well as it did a year ago. I'm seeing no CPU load and am downloading at full throttle. Couldn't be happier here!
Edit: for reference, my device is [11ab:4362]
comment:50 by , 12 years ago
luroh, nice! Did you test after a few reboots? I know oco checked at least five or six times successfully until it fails again. Aligned page allocation should be ok in hrev44773. oco tested a test build of marvell_yukon with sc->msk_stat_cons aligned on 16k and it seems successful on his hardware. I'll gather an updated patch for marvell_yukon tonight.
comment:51 by , 12 years ago
Ah, I see. Well, I have just rebuilt and tested again, ten warm reboots and three cold ones, still works fine here. hrev44780, gcc2, both patches applied.
comment:52 by , 12 years ago
Lets get these into the master branch asap so they can be picked for R1A4! :D
comment:53 by , 12 years ago
Mine still does not work except with one of the many proposed by Korli since saturday which contains some debug output and the alignment fix.
This evening, korli send me different combinations of committable fixs, all without debug output. None of them have work without problems so far. Maybe remaining problems are linked to this specific device ([11ab:4354]).
comment:54 by , 12 years ago
kallisti5, I would suggest you go with mmlr's patches on trunk then alpha4. I suppose oco can live a bit longer with a custom driver (be sure to keep a copy around).
Sorry I couldn't find out what we miss, even if we spend a lot of time on it at BG with oco. We'll probably revisit this with upcoming 9.2 release of FreeBSD anyway ;)
@oco I would have suggested to check the behavior with a FreeBSD live CD but couldn't find one for 9.1
comment:55 by , 12 years ago
If we get down to the wire and mmlr hasn't commited the fixes yet i'll commit to mainline + pick for R1A4.
This will most likely be the last accepted pick :)
comment:56 by , 12 years ago
I've just pushed both of these in hrev44793 with slightly reworded commit messages. Please pick for alpha4, thanks.
comment:57 by , 12 years ago
| Summary: | Very low network performance with a Marvell Yukon card. → Very low network performance on some Marvell Yukon cards. |
|---|
picked.
Renaming issue.
comment:58 by , 12 years ago
| patch: | 1 → 0 |
|---|
comment:59 by , 11 years ago
| Milestone: | R1/beta1 → Unscheduled |
|---|
Moving out of beta1 milestone. This now only affects a single machine, meaning the core bug in FreeBSD layer has been fixed.
comment:61 by , 10 years ago
| Priority: | high → normal |
|---|
oco: Any improvement? I believe our marvell_yukon driver has been updated twice since R1A4.
comment:63 by , 6 years ago
As far as I know the problem is still around. I still have a machine usig that chip, but it's now my server serving the beosarchive and my mailbox, so I need to take these offline while I test. Will report when I can, if oco doesn't get to it.
comment:64 by , 6 years ago
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
I found another machine with that chip, and it seems to be working all fine now. I assume it's safe to close this then.
comment:65 by , 6 years ago
Finally found some time to check this on my old laptop (the Sony referenced earlier in this ticket) while my WIFI was not yet connected : it just works out of the box with Haiku Beta 1. Thank you everybody !
comment:66 by , 5 years ago
| Milestone: | Unscheduled → R1/beta2 |
|---|
Assign tickets with status=closed and resolution=fixed within the R1/beta2 development window to the R1/beta2 Milestone
see also #4239