

Opened 17 years ago
Closed 16 years ago
#2706 closed bug (fixed)
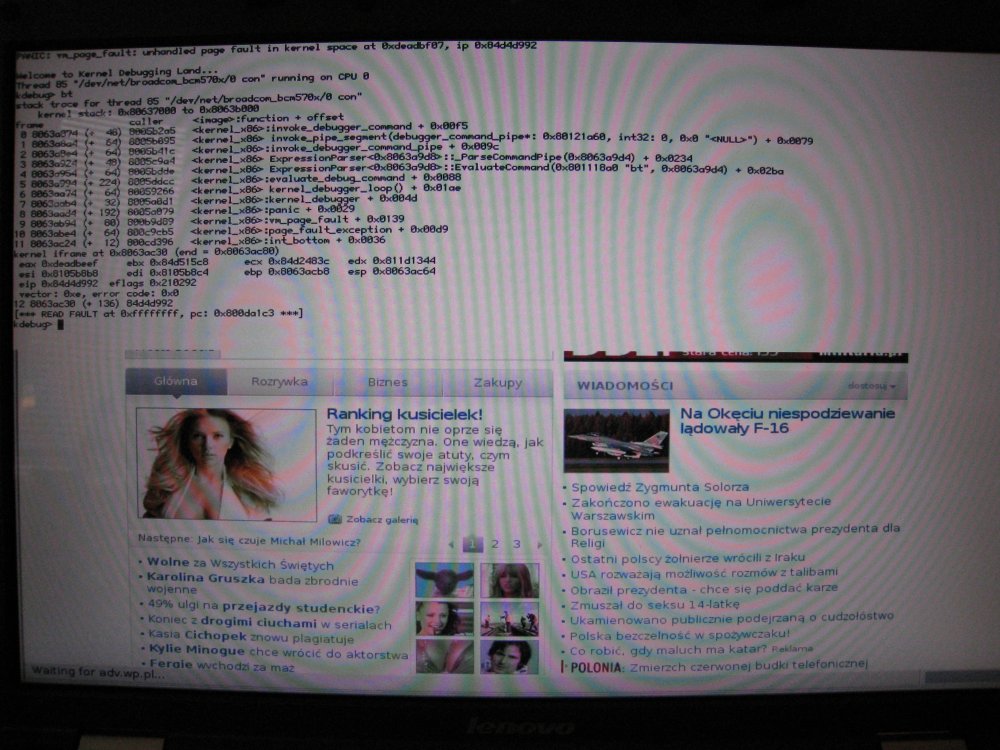
PANIC: vm_page_fault: unhandled page fault in kernel space at 0xdeadbf07, ip 0x9428897e
| Reported by: | stippi | Owned by: | axeld |
|---|---|---|---|
| Priority: | critical | Milestone: | R1/alpha1 |
| Component: | Network & Internet/TCP | Version: | R1/pre-alpha1 |
| Keywords: | Cc: | imker@…, adek336@… | |
| Blocked By: | Blocking: | #3392 | |
| Platform: | x86 |
Description (last modified by )
Happens to me when using Firefox on hrev27315. Here is the stack crawl:
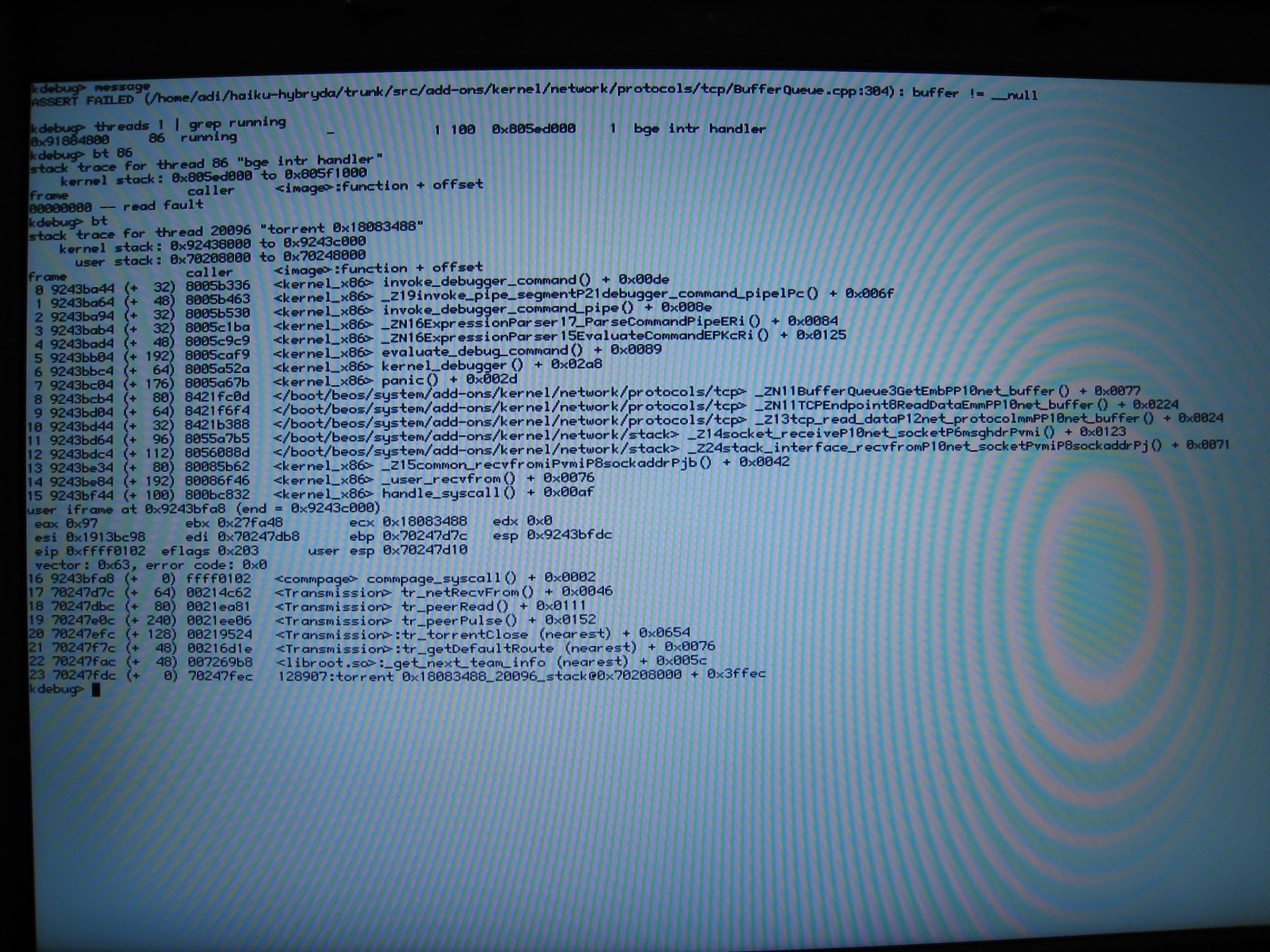
stack trace for thread 80 "/dev/net/ipro1000/0 consumer" <kernel>vm_page_fault <kernel>page_fault_exception <kernel>int_bottom kernel iframe <...network/protocols/tcp>Compare__C24ConnectionHashDefinitionRCt4pair2ZPC8sockaddrZPC8sockaddrP11TCPEndpoint + 0x0022 <...network/protocols/tcp>_LockupConnection__15EndpointManagerP8sockaddrT1 + 0x0066 <...network/protocols/tcp>FindConnection__15EndpointManagerP8sockaddrT1 + 0x0054 <...network/protocols/tcp>tcp_receive_data__FP10net_buffer + 0x02e9 <...network/protocols/ipv4>ipv4_receive_data__FP10net_buffer + 0x02ba <...network/stack>domain_receive_adapter__FPvP10net_deviceP10net_buffer + 0x003a <...network/stack>device_consumer_thread__FPv + 0x00c7 [...]
Attachments (15)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (41)
comment:1 by , 17 years ago
| Description: | modified (diff) |
|---|
comment:2 by , 17 years ago
| Cc: | added |
|---|
by , 16 years ago
| Attachment: | img_0974.0.jpg added |
|---|
by , 16 years ago
| Attachment: | img_0972.0.jpg added |
|---|
via rhine II: deadbeef in consumer thread (other computer)
comment:3 by , 16 years ago
All three of these adapters: Via rhine II, Broadcom Tigon3 and ipro100 use the FreeBSD compability layer.
comment:4 by , 16 years ago
| Cc: | added |
|---|
by , 16 years ago
ipro100: deadbeef in consumer thread (screenshot downloaded from somewhere)
comment:6 by , 16 years ago
| Platform: | All → x86 |
|---|
I reproduced this bug in hybrid gcc4 28810 on FF 2.0.0.12 (Realtek 8139), on gcc2 version work fine.
by , 16 years ago
| Attachment: | img_11410.jpg added |
|---|
bfe when opening lot of connections to self with netcat
by , 16 years ago
| Attachment: | img_11420.jpg added |
|---|
bge, hybrid, torrent, note that nic's interrupt handler is active
by , 16 years ago
| Attachment: | img_1022.jpg added |
|---|
bge,gcc2,ConnectionHashDefinition::Compare, EndpointManager::_LookupConnection
comment:9 by , 16 years ago
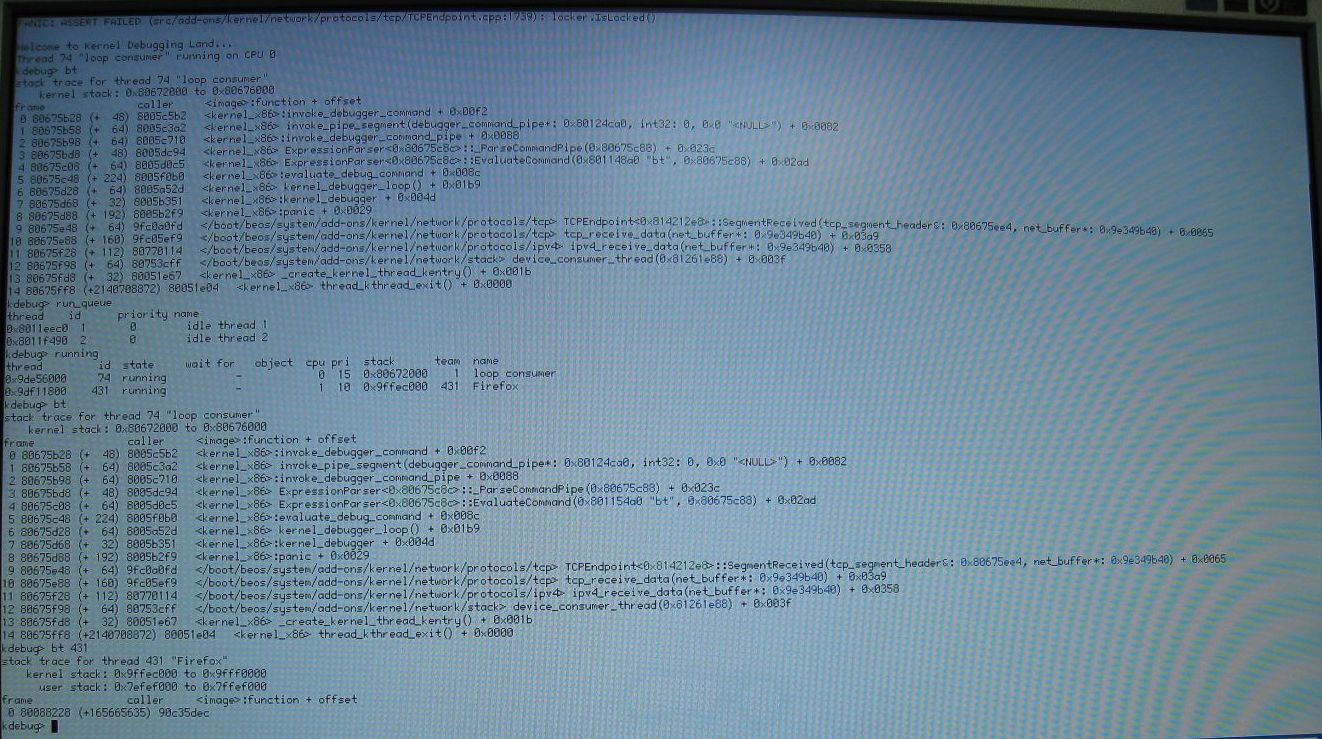
img_1309 SegmentReceived not locked Firefox.jpg: happens with modified code when I open up transmission with 30 torrents and after a few minutes try to open Firefox. Crashes before Firefox window opens. Continuing may but doesnt have to result in a deadbeef page fault in "loop consumer thread".
Modification:
int32
TCPEndpoint::SegmentReceived(tcp_segment_header& segment, net_buffer* buffer)
{
MutexLocker locker(fLock);
+ ASSERT(locker.IsLocked());
TRACE("SegmentReceived(): buffer %p (%lu bytes) address %s to %s\n"
There's lot more places with MutexLocker but they've been all properly locked as far as I checked.
by , 16 years ago
| Attachment: | img_1309 SegmentReceived not locked Firefox.jpg added |
|---|
by , 16 years ago
| Attachment: | img_1389.jpg added |
|---|
follow-up: 15 comment:10 by , 16 years ago
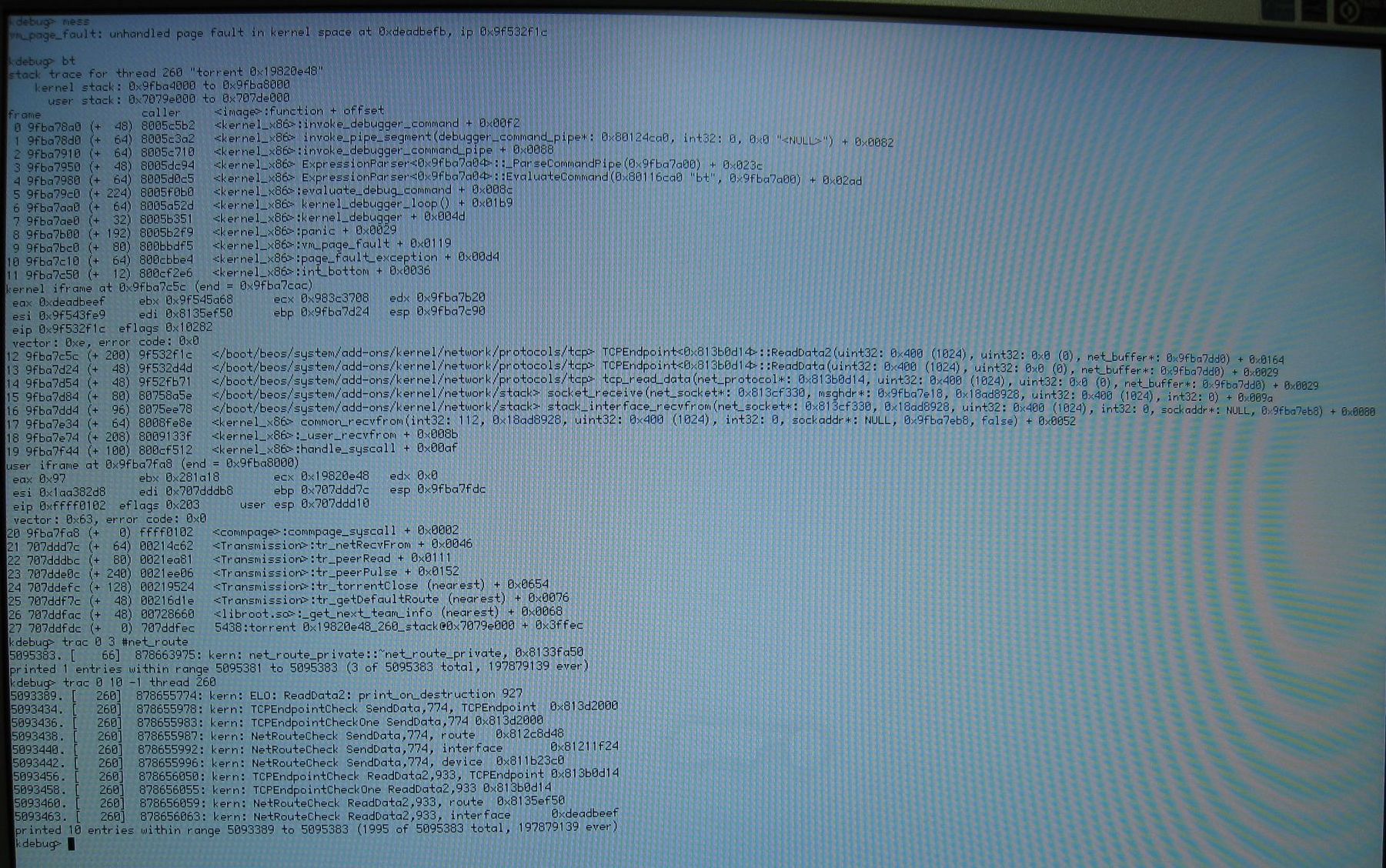
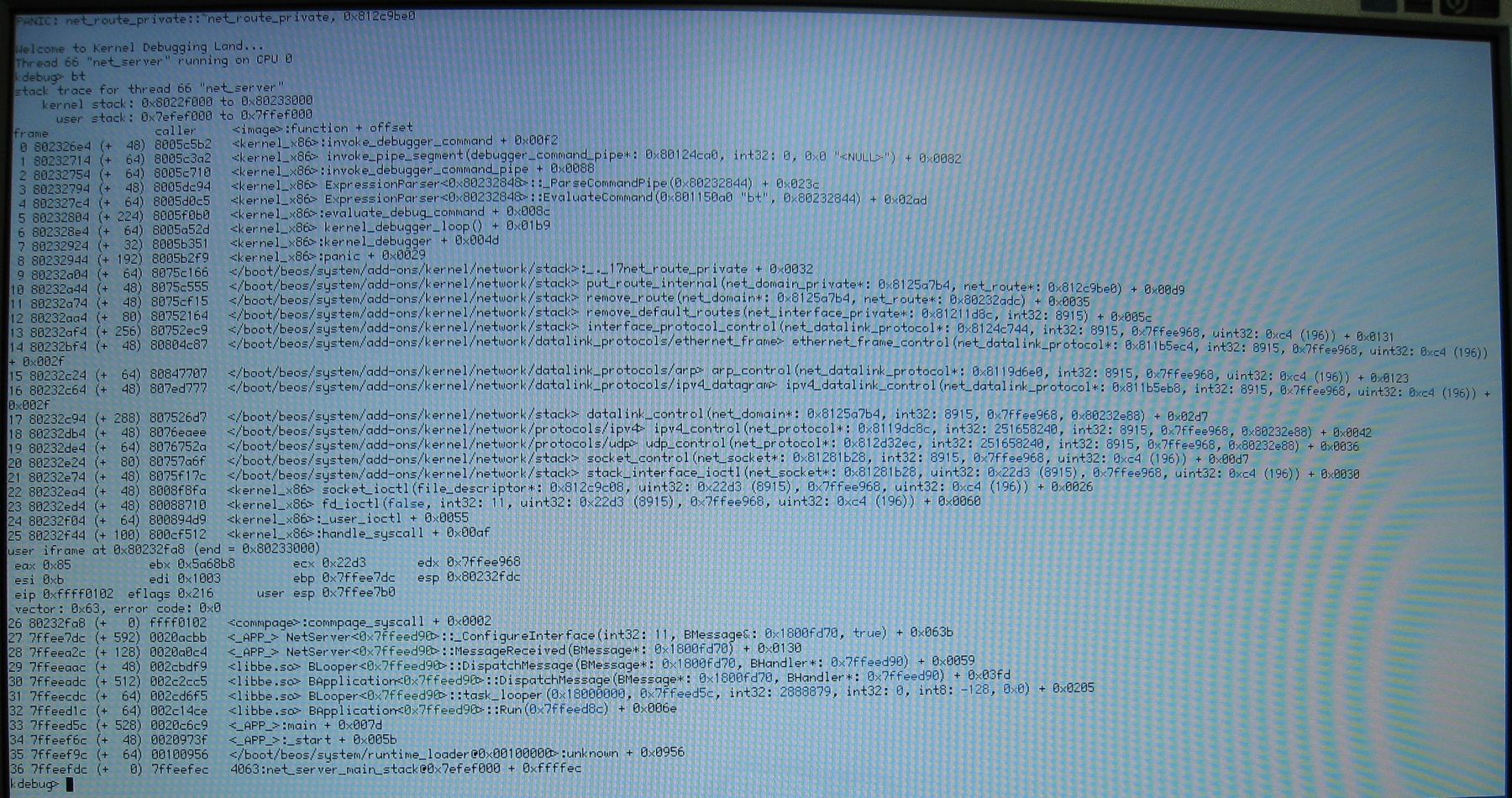
img_1389.jpg: photo of KDL. Diagnostic messages added to net_route_private constructor and destructor. Also added to TCPEndpoint::ReadData, where the value of this->fRoute and this->fRoute->interface is dumped to the trace buffer many times during the function.
We see from the backtrace that TCPEndpoint::ReadData is running. We see from the trace messages that it is running since at least the 5093389 trace message. We see from 5093438, that this->fRoute = 0x812c8d48. In 5095383 we see that net_route_private of that address is being destroyed.
It should not be destroyed; that causes TCPEndpoint::ReadData to eventually use pointers overwritten with other data and to page fault.
by , 16 years ago
| Attachment: | img_1391.jpg added |
|---|
by , 16 years ago
| Attachment: | img_1392.jpg added |
|---|
comment:11 by , 16 years ago
That lock that isn't always locked and the changing routing tables are two problems, a third one is with
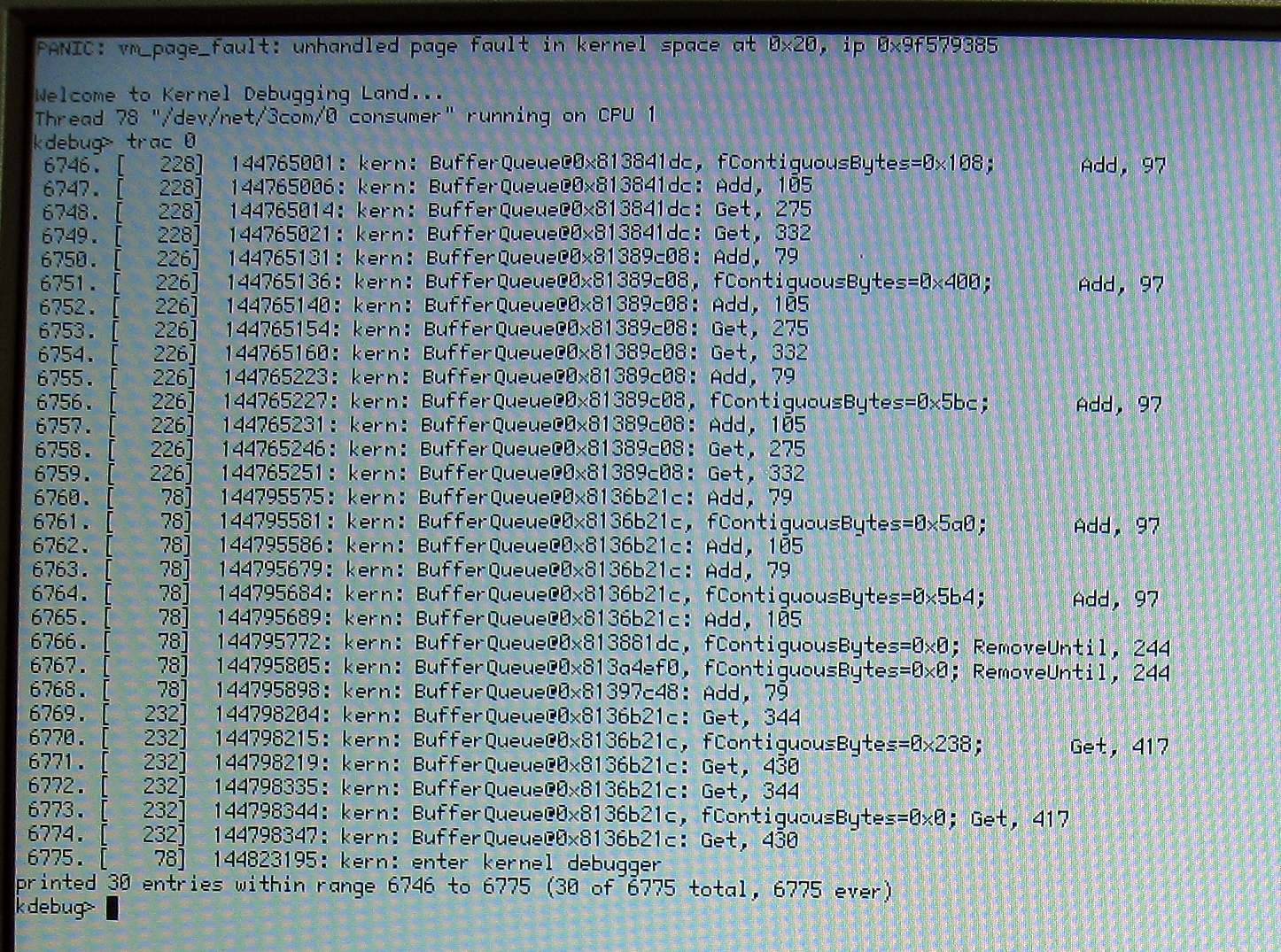
add-ons/kernel/network/protocols/tcp/BufferQueue.cpp
290 status_t
291 BufferQueue::Get(size_t bytes, bool remove, net_buffer **_buffer)
292 {
...
324 while (bytesLeft > 0 && (source = iterator.Next()) != NULL) {
325 size_t size = min_c(source->size, bytesLeft);
326 status = gBufferModule->append_cloned(buffer, source, 0, size);
327 if (status < B_OK)
328 break;
329
330 bytesLeft -= size;
331
332 if (!remove)
333 continue;
334
335 // remove either the whole buffer or only the part we cloned
336
337 fFirstSequence += size;
338
339 if (size == source->size) {
340 iterator.Remove();
341 gBufferModule->free(source);
342 } else {
343 gBufferModule->remove_header(source, size);
344 source->sequence += size;
345 }
346 }
347
348 if (status == B_OK) {
349 *_buffer = buffer;
350 if (remove) {
351 fNumBytes -= bytes;
352 fContiguousBytes -= bytes;
353 }
354 } else
355 gBufferModule->free(buffer);
356
357 return status;
358 }
in that the loop may remove buffers in line 340 and later the loop may be broken in line 328. Then, fNumBytes, fContiguos and etc. are not updated in spite of the fact that buffers have been removed. That leaves the buffer queue in an inconsistent state where it, for example, claims to have more data than it really has in its buffers.
comment:12 by , 16 years ago
The BufferQueue problem is a different one, though (ie. bug #2594). Thanks for looking into it, that pretty much explains the problem :-)
comment:13 by , 16 years ago
Actually I added code to panic if it breaks out of the loop after having removed buffers and yet managed to reproduce #2594.
comment:14 by , 16 years ago
I mean, it didn't trigger my panic, but it did trigger the one from #2594.
by , 16 years ago
| Attachment: | img_1426.jpg added |
|---|
comment:15 by , 16 years ago
Replying to Adek336:
In 5095383 we see that net_route_private of that address is being destroyed.
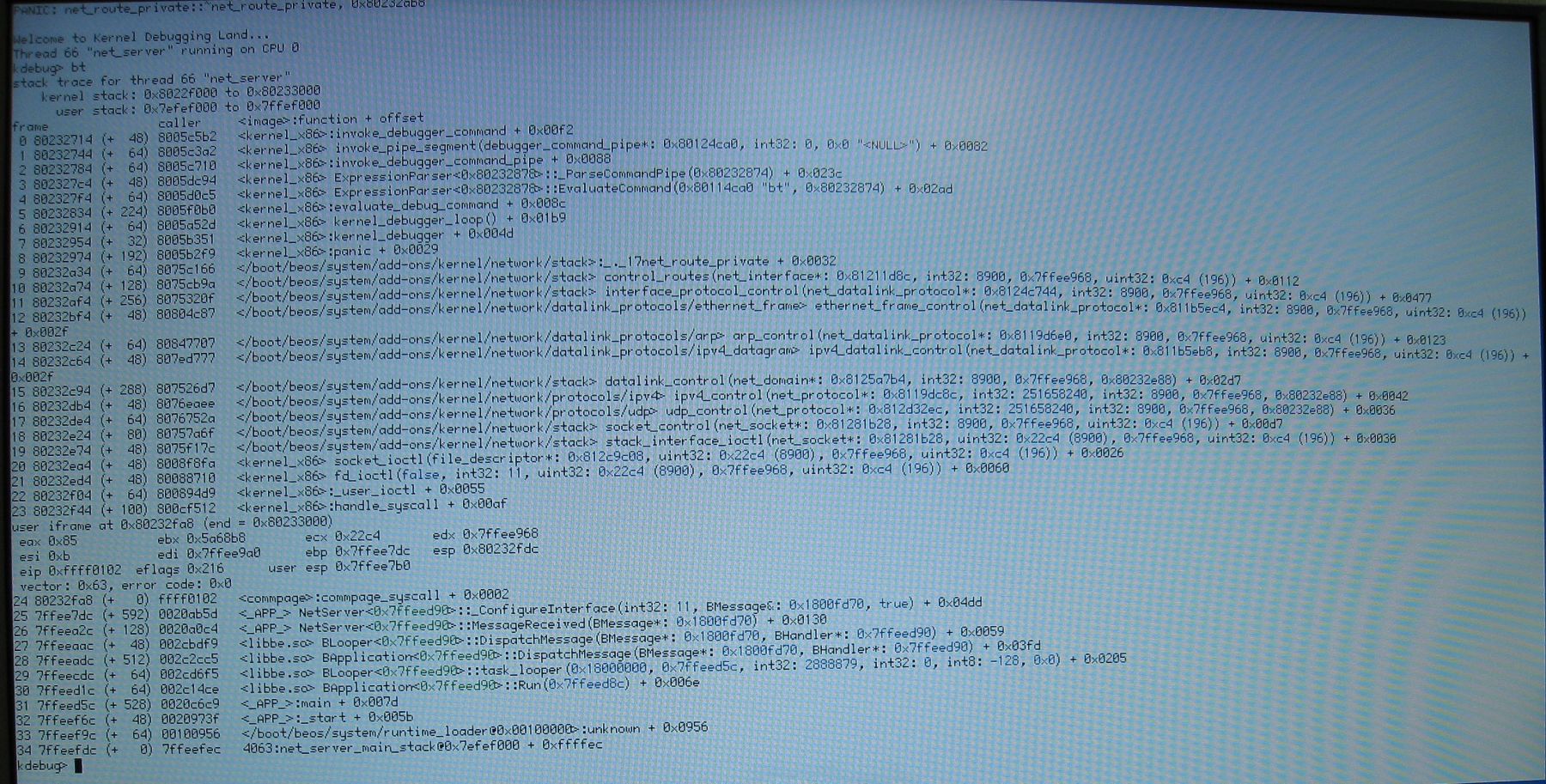
img_1389.jpg doesn't show that after all. Uploaded img_1426.jpg which shows what img_1389.jpg was supposed to.
comment:16 by , 16 years ago
This is not shown in the photo, but many net_route_private instances have absurd reference counts which often exceed fifty thousand.
by , 16 years ago
| Attachment: | img_1440.jpg added |
|---|
by , 16 years ago
| Attachment: | img_1441.jpg added |
|---|
comment:17 by , 16 years ago
Index: src/add-ons/kernel/network/protocols/tcp/TCPEndpoint.cpp
===================================================================
--- src/add-ons/kernel/network/protocols/tcp/TCPEndpoint.cpp (wersja 28891)
+++ src/add-ons/kernel/network/protocols/tcp/TCPEndpoint.cpp (kopia robocza)
@@ -430,6 +430,8 @@
gStackModule->wait_for_timer(&fPersistTimer);
gStackModule->wait_for_timer(&fDelayedAcknowledgeTimer);
gStackModule->wait_for_timer(&fTimeWaitTimer);
+
+ gDatalinkModule->put_route(Domain(), fRoute);
}
to avoid absurd reference counts in routes.
comment:18 by , 16 years ago
The crash (a default route being deleted while still being referenced after somebody does put_route() without prior get_route()) can be reproduced very fast if a command like this runs while starting Transmission with many torrents:
while true; do ifconfig /dev/net/3com/0 192.168.1.101 up; done
comment:19 by , 16 years ago
I think there are two problems: 1) TCP is not using net_route_infos but net_routes directly, and 2) some route locking in the stack has apparently been removed some time ago - it doesn't look very good as it is now.
follow-up: 23 comment:20 by , 16 years ago
With net_route_infos, to use the route, one has to read net_route_info::route, and then increase it's reference count. But the route may be destroyed in between! Clearly a function to do it atomically is needed. There also seem to be no users of net_route_info atm :-))
Apart from locking, there might be a problem with deleting a default route and setting up a new one. The current code would put the route and try to setup a new one. However, only one default route may exist, so if the action of removing the old route was delayed (because, for example, some small helper function like ipv4_get_mtu got the route and it's thread lost the cpu before putting the route) then the new route won't be set up. Also the old route is going to be removed shortly, so no default routes remain!
One solution is to drop the route from the route list when removing the route. That lets the new route be created and the old route used. If also everybody except the small helper functions use net_route_info than they would soon update and put the old route.
Another solution is, when servicing SIOCDELR, to block servicing SIOCDELR until everyone puts the old route. Again, this requires that everybody use net_route_info and if net_timer would want to remove the route, it might deadlock (but I think only user apps would ever want to remove routes and that net_timer doesn't try to remove routes).
As for why the page fault happens: when net_server tries to reconfigure the default route, the stack puts the route to tell the world that it no longer references it, that it gives up it's ownership of the route. The route still has a positive reference count due to TCP endpoints, so it is not really removed and the new default route isn't installed when another default route exists. Soon net_server wants to reconfigure the default route and the stack puts the route again... so it gives up ownership of a route whom it does not possess ! Possibly net_route_private could remember how many times it was supposed to be removed so that remove_route would panic or return error on second and later tries.
comment:21 by , 16 years ago
Note that changeset:28892 will expose the fact that TCP doesn't use net_route_info as page faults in TCP destructor.
comment:23 by , 16 years ago
Replying to Adek336:
One solution is to drop the route from the route list when removing the route. That lets the new route be created and the old route used. If also everybody except the small helper functions use net_route_info than they would soon update and put the old route.
That was actually the basic idea behind the route info. I hope to be able to solve this soon, and hopefully finally, unless you want to ;-)
And thanks a lot for your investigations!
comment:24 by , 16 years ago
| Blocking: | 3392 added |
|---|
comment:25 by , 16 years ago
| Blocking: | 3465 removed |
|---|---|
| Resolution: | → fixed |
| Status: | new → closed |
Fixed in hrev29386. TCP is still using net_routes directly, but this doesn't cause any crashes anymore.
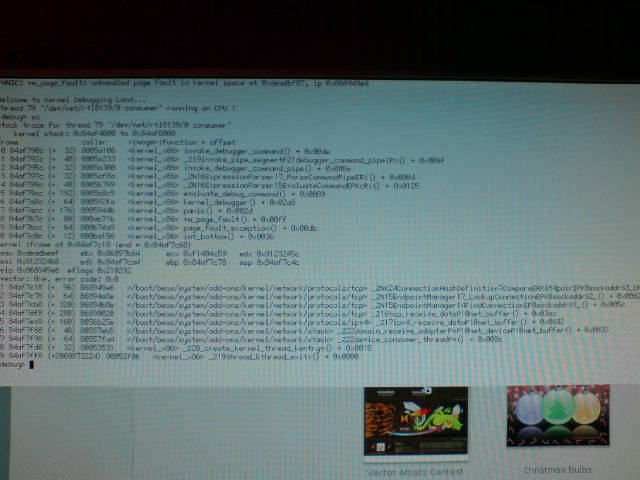
broadcom tigon3: deadbeef in consumer thread