

Opened 15 years ago
Last modified 5 months ago
#4555 assigned bug
PANIC: Fatal Exception "NMI Interrupt" occured
| Reported by: | MasterNetra | Owned by: | mmlr |
|---|---|---|---|
| Priority: | normal | Milestone: | R1 |
| Component: | System/Kernel | Version: | R1/alpha1 |
| Keywords: | boot-failure | Cc: | |
| Blocked By: | Blocking: | #8097, #8741, #11684, #17271, #18506 | |
| Platform: | x86 |
Description
At bootup I get this after after dot load: Panic: Fatal Exception "NMI Interrupt" has occured. Error code: 0x0 (I think I got it as displayed, had to memorize it)
Attachments (6)
{kind=link}
{kind=link}
Change History (35)
comment:1 by , 15 years ago
| Component: | System → System/Kernel |
|---|
comment:3 by , 15 years ago
Cool. I am not sure, but IIRC, the NMI panic is kind of a warning, and we may be able to just ignore the NMI. But kernel devs would know this stuff much better than myself.
comment:4 by , 14 years ago
Hope I am not hijacking this ticket but I came to report the same 'PANIC: fatal exception "NMI Interrupt" occurred! Error code 0x0' error and did a search first.
This happened after I inserted the R1Alpha2 (not alpha1 as was the case for the original poster) CD in my laptop in order to install Haiku to a partition created with GParted. That same laptop which will also receive FreeBSD 8.1 and Ubuntu 10.10 in the coming days also features a freshly (re)installed Vista SP2.
Laptop: Fujitsu Siemens Amilo Xi2528, 2 Ghz Core 2 Duo, 2x250 GB HDD (freshly unRAIDed), 2 GB of RAM. This 2008 laptop can't boot any bootable CD from my external DVD drive although it boots from USB keys...
Anyway, I followed the 'press shift for fail-safe mode' tip but the message is the same. I also used "co[ntinue]" as offered by @stippi: command unknown. I ended up using "continue" but this got the PC locked: Ctrl+Alt+Del does nothing and doesn't reboot. Will wait for the next release.
follow-up: 6 comment:5 by , 13 years ago
I have this problem as well. I have an HP Pavilion dv6000 series (not sure the exact number) laptop with a Core2 Duo processor. This has been a problem for me as long as I've been booting on native hw. Pre-A3 the NMI occurred after the 3rd icon lit up on boot, post-A3 it now occurs before the first icon lights up. Typing 'es' works and the NMI only pops up once. I'll get a syslog posted up in a day or two and I'll try to hunt down the exact revision where the time the NMI happens changes.
comment:6 by , 13 years ago
Replying to Duggan:
Pre-A3 the NMI occurred after the 3rd icon lit up on boot, post-A3 it now occurs before the first icon lights up. ... and I'll try to hunt down the exact revision where the time the NMI happens changes.
Most probably due to the IO-APIC changes. The IO-APIC isn't causing it, but causes the PCI module to be loaded and initialized earlier in boot which probably triggers this. In either case a syslog would confirm.
comment:7 by , 13 years ago
| Keywords: | NMI added |
|---|---|
| Owner: | changed from to |
| Status: | new → assigned |
| Summary: | Unable Run on Dell Latitude D530 → PANIC: Fatal Exception "NMI Interrupt" has occured |
I'm going to generalize this ticket to NMI (presumably at PCI init time) so that it can more easily be found. I'll also try to look into it, but can't really promise anything as I can't reproduce the issue over here.
comment:8 by , 13 years ago
| Blocking: | 8097 added |
|---|
by , 13 years ago
| Attachment: | nmi_syslog added |
|---|
snippet of a syslog showing general area where NMI occurs as well as KDL output
follow-up: 10 comment:9 by , 13 years ago
Hey mmlr, I attached a small snipet of my syslog confirming that it's PCI related. If you want the entire syslog let me know and I'll try to get a clean one up soon.
comment:10 by , 13 years ago
Replying to Duggan:
Hey mmlr, I attached a small snipet of my syslog confirming that it's PCI related. If you want the entire syslog let me know and I'll try to get a clean one up soon.
That's fine, the attached one is great, no need to dig further for now. I've browsed through the PCI specs to see if there was anything obvious and saw that the parity error handling might be to blame, as that one can be configured to trigger an SERR assert that'd lead to the NMIs. Though even if that was the case we'd still need to investigate/fix the reason for the parity error in the first place. Also SERR may be asserted in other situations, like incompatible transactions (as in lower bit width busses that can't complete input addressing) or other errors. We might not account for things like that, but I haven't yet looked into our code to check.
by , 13 years ago
| Attachment: | nmi_syslog_2 added |
|---|
Here's a much larger chunk of syslog that should cover the info you need... Thanks, mmlr!
by , 13 years ago
| Attachment: | change_pci_bridge_config_order.diff added |
|---|
Change the order of error clearing and enabling error reporting.
comment:11 by , 13 years ago
Can you please try the attached patch and see if that gets things going? Basically it causes error conditions to be cleared first and only then enables error reporting on the PCI bridges. This may avoid reporting for still pending errors at configuration time that could lead to the NMIs.
comment:12 by , 13 years ago
Sure :) I'll do that a little later today. Is that a proper fix? I don't know alot about this stuff, but should those errors be handled? Anyway, I'll let you know how it works. Thanks!
comment:14 by , 13 years ago
Replying to Duggan:
Nope, that didn't do it :/
Ah well, at least that means it's not just some lingering error condition that triggers as soon as error reporting is enabled (or that our error reset doesn't actually work). I guess some more debug output is needed to determine what's going on exactly.
In either case the error condition seems to come from the PCIe port that has the wired ethernet controller attached (PCI device 28 function 5 with secondary bus 8). From the data available alone it doesn't really look any different from the other PCIe ports...
That reminds me though that the error condition clearing only every uses kprintf to output the data to the kernel debugger. What you could do when the NMI kicks in is execute the "pcistatus" KDL command, which should then list any present error conditions before trying to clear them. If you could attach that output (you can simply continue after executing that command) as well, that might give some clue.
comment:15 by , 13 years ago
| Summary: | PANIC: Fatal Exception "NMI Interrupt" has occured → PANIC: Fatal Exception "NMI Interrupt" occured |
|---|
by , 11 years ago
| Attachment: | syslog_lenovo added |
|---|
comment:16 by , 11 years ago
I have the same problem on 2 Lenovo desktop PC at my workplace. I have attached the syslog.
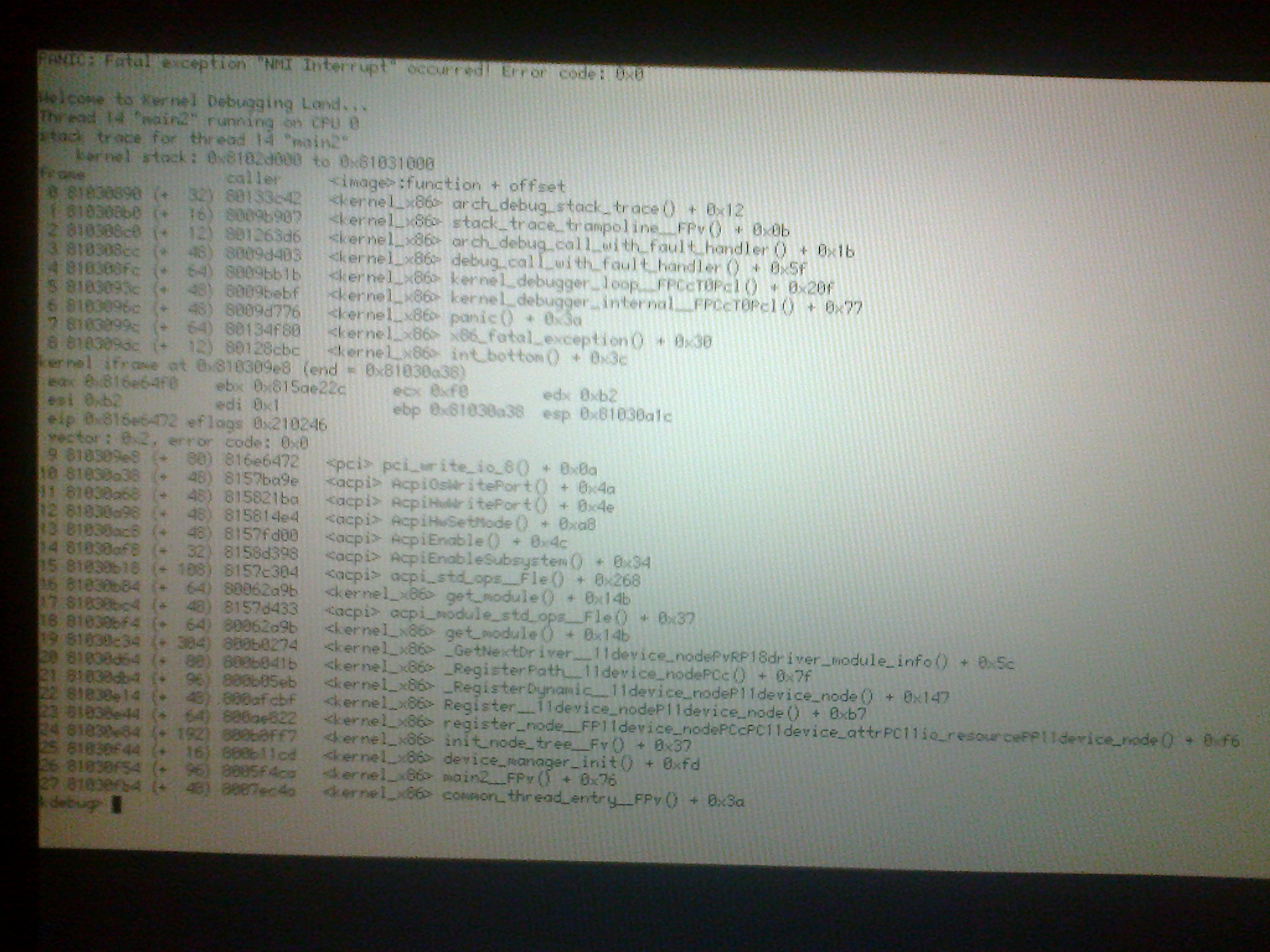
KERN: PANIC: Fatal exception "NMI Interrupt" occurred! Error code: 0x0 KERN: KERN: Welcome to Kernel Debugging Land... KERN: Thread 1 "idle thread 1" running on CPU 0 KERN: stack trace for thread 1 "idle thread 1" KERN: kernel stack: 0x81001000 to 0x81005000 KERN: frame caller <image>:function + offset KERN: 0 81004be8 (+ 32) 8013313e <kernel_x86> arch_debug_stack_trace() + 0x12 KERN: 1 81004c08 (+ 16) 80093353 <kernel_x86> stack_trace_trampoline__FPv() + 0x0b KERN: 2 81004c18 (+ 12) 80125bd2 <kernel_x86> arch_debug_call_with_fault_handler() + 0x1b KERN: 3 81004c24 (+ 48) 80094df6 <kernel_x86> debug_call_with_fault_handler() + 0x5e KERN: 4 81004c54 (+ 64) 80093573 <kernel_x86> kernel_debugger_loop__FPCcT0Pcl() + 0x21b KERN: 5 81004c94 (+ 48) 800938d7 <kernel_x86> kernel_debugger_internal__FPCcT0Pcl() + 0x53 KERN: 6 81004cc4 (+ 48) 80095182 <kernel_x86> panic() + 0x36 KERN: 7 81004cf4 (+ 64) 801344c8 <kernel_x86> x86_fatal_exception() + 0x30 KERN: 8 81004d34 (+ 12) 80128680 <kernel_x86> int_bottom() + 0x30 KERN: kernel iframe at 0x81004d40 (end = 0x81004d90) KERN: eax 0x817e86f0 ebx 0x816ec434 ecx 0xf0 edx 0xb2 KERN: esi 0xb2 edi 0x8 ebp 0x81004d90 esp 0x81004d74 KERN: eip 0x817e864a eflags 0x210046 KERN: vector: 0x2, error code: 0x0 KERN: 9 81004d40 (+ 80) 817e864a <pci> pci_write_io_8() + 0x0a KERN: 10 81004d90 (+ 48) 816bf252 <acpi> AcpiOsWritePort() + 0x4a KERN: 11 81004dc0 (+ 48) 816c4f31 <acpi> AcpiHwWritePort() + 0x3d KERN: 12 81004df0 (+ 48) 816c44e0 <acpi> AcpiHwSetMode() + 0x8c KERN: 13 81004e20 (+ 48) 816c30b0 <acpi> AcpiEnable() + 0x30 KERN: 14 81004e50 (+ 32) 816cebe2 <acpi> AcpiEnableSubsystem() + 0x22 KERN: 15 81004e70 (+ 96) 816bf8e8 <acpi> acpi_std_ops__Fle() + 0x278 KERN: 16 81004ed0 (+ 64) 8005fc3b <kernel_x86> get_module() + 0x15b KERN: 17 81004f10 (+ 80) 80139649 <kernel_x86> ioapic_init__FP11kernel_args() + 0x71 KERN: 18 81004f60 (+ 64) 80134a6c <kernel_x86> arch_int_init_io() + 0x1c KERN: 19 81004fa0 (+ 32) 80059a96 <kernel_x86> int_init_io() + 0x12 KERN: 20 81004fc0 (+ 48) 8005c239 <kernel_x86> _start() + 0x279
Using hrev46023 nightly anyboot.
comment:17 by , 11 years ago
KERN: Welcome to Kernel Debugging Land... KERN: Thread 3518 "kernel_debugger" running on CPU 0 KERN: kdebug> pcistatusdomain 0, bus 0, dev 0, func 0, PCI device status 0x3090 KERN: Received Master-Abort KERN: Received Target-Abort KERN: domain 0, bus 0, dev 2, func 0, PCI device status 0x0090 KERN: domain 0, bus 0, dev 2, func 1, PCI device status 0x0090 KERN: domain 0, bus 0, dev 27, func 0, PCI device status 0x0018 KERN: domain 0, bus 0, dev 28, func 0, PCI device status 0x0010 KERN: domain 0, bus 0, dev 28, func 0, PCI bridge secondary status 0x2000 KERN: Received Master-Abort KERN: domain 0, bus 0, dev 28, func 0, PCI bridge control 0x0003 KERN: domain 0, bus 0, dev 28, func 1, PCI device status 0x0010 KERN: domain 0, bus 0, dev 28, func 1, PCI bridge secondary status 0x0000 KERN: domain 0, bus 0, dev 28, func 1, PCI bridge control 0x0003 KERN: domain 0, bus 12, dev 0, func 0, PCI device status 0x0018 KERN: domain 0, bus 0, dev 29, func 0, PCI device status 0x0280 KERN: domain 0, bus 0, dev 29, func 1, PCI device status 0x0280 KERN: domain 0, bus 0, dev 29, func 2, PCI device status 0x0280 KERN: domain 0, bus 0, dev 29, func 3, PCI device status 0x0280 KERN: domain 0, bus 0, dev 29, func 7, PCI device status 0x0290 KERN: domain 0, bus 0, dev 30, func 0, PCI device status 0x4810 KERN: Signalled System Error KERN: Signalled Target-Abort KERN: domain 0, bus 0, dev 30, func 0, PCI bridge secondary status 0xb380 KERN: Detected Parity Error KERN: Received Master-Abort KERN: Received Target-Abort KERN: Data Parity Reported KERN: domain 0, bus 0, dev 30, func 0, PCI bridge control 0x0823 KERN: domain 0, bus 2, dev 0, func 0, PCI device status 0x0810 KERN: Signalled Target-Abort KERN: domain 0, bus 2, dev 1, func 0, PCI device status 0x0410 KERN: domain 0, bus 2, dev 1, func 4, PCI device status 0x0218 KERN: domain 0, bus 0, dev 31, func 0, PCI device status 0x0210 KERN: domain 0, bus 0, dev 31, func 2, PCI device status 0x02b8 KERN: domain 0, bus 0, dev 31, func 3, PCI device status 0x0280 KERN: kdebug> es
the following machine does the same nmi interrupt error on boot and goes into kdl.
comment:18 by , 10 years ago
This seems to happen on my IBM T42, hrev47815. This laptop could be shipped if someone is curious to have a look at it.
comment:19 by , 7 years ago
| Keywords: | boot-failure added; NMI removed |
|---|
comment:20 by , 7 years ago
| Blocking: | 8741 added |
|---|
comment:22 by , 6 years ago
| Blocking: | 11684 added |
|---|
comment:23 by , 3 years ago
| Blocking: | 17271 added |
|---|
comment:24 by , 3 years ago
Yes, still an issue, either a regression or another instance on different hardware.
This is a fresh install from haiku-r1beta3-x86_64-anyboot.iso , and the machine is a Lenovo ThinkCentre 7360 whp. I can provide logs and other information as required.
Typing "co" or disabling ACPI in the boot options allows the boot to complete.
comment:25 by , 21 months ago
Update, I booted R1/beta4 from a USB drive and got the same exception.
comment:26 by , 21 months ago
yes, a syslog would be helpful to see where this is happening. You can find it in /var/log/syslog once the system is booted
by , 21 months ago
| Attachment: | syslog.txt added |
|---|
comment:28 by , 19 months ago
| Blocking: | 18506 added |
|---|
comment:29 by , 5 months ago
Several of these syslogs seem to be during ACPI tables access.
In the last syslog attached, it is in AcpiHwSetMode, which does a PCI IO on an address computed from the FADT table. So, if the table is invalid or mis-parsed, it could end up accessing an invalid address.
I'm not sure if we can sanitize this by checking if the IO access is in a valid range at the PCI level? And ignore it (with a syslog message) instead of doing a panic?
These "should" not happen. That's a so called non-maskable interrupt. You should be able to type co[ntinue] at the KDL prompt. Does that work?