

#5262 closed bug (fixed)
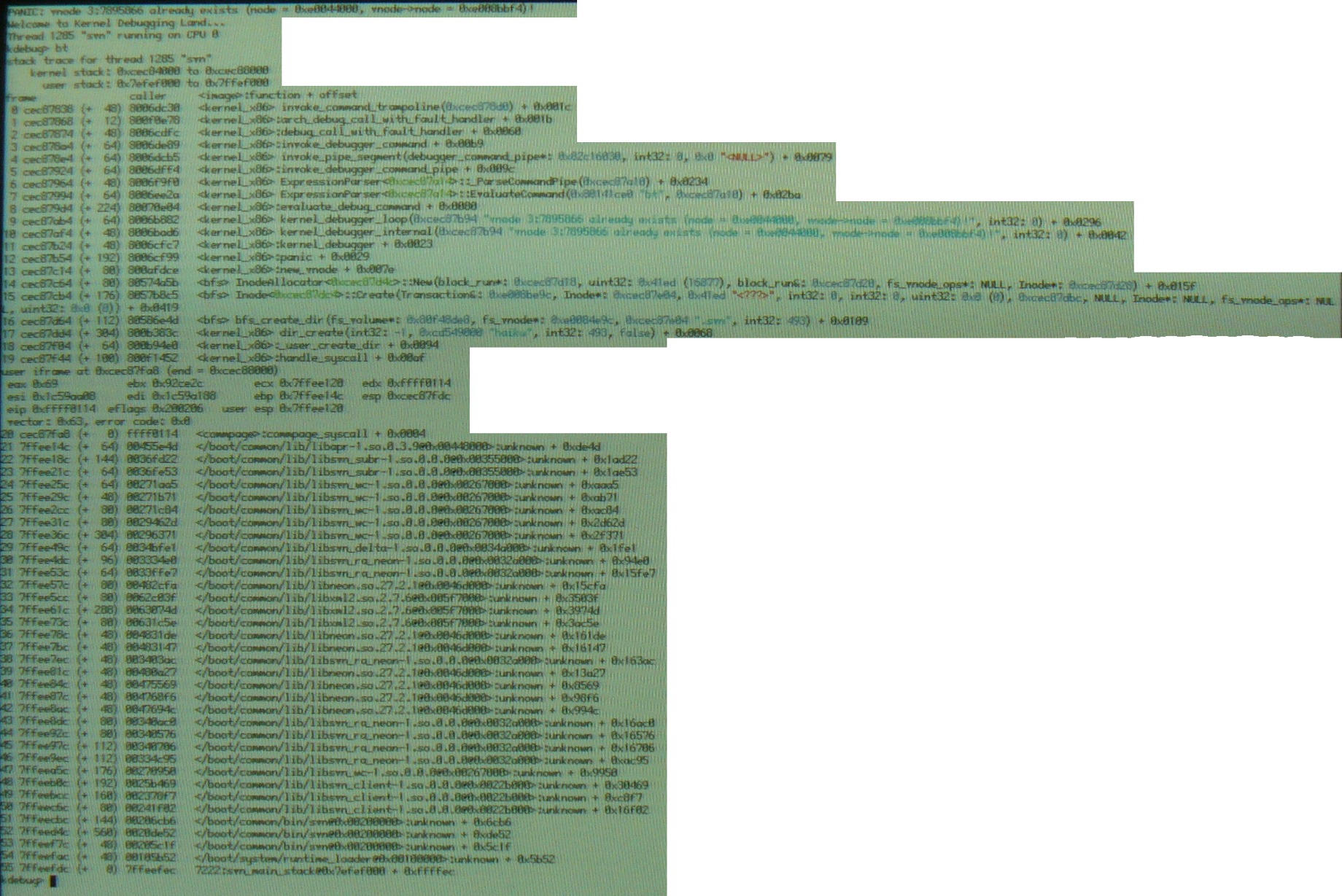
PANIC: vnode 3:7895866 already exists (node = 0xe0044000, vnode->node = 0xe008bbf4)!
| Reported by: | justeco | Owned by: | axeld |
|---|---|---|---|
| Priority: | critical | Milestone: | R1/beta1 |
| Component: | File Systems/BFS | Version: | R1/Development |
| Keywords: | Cc: | degea@… | |
| Blocked By: | Blocking: | #3685, #5753, #7608, #7865, #7952, #8989, #9123, #9730, #13051, #14297 | |
| Platform: | x86 |
Description
KDL while running svn checkout on hrev35025
Picture of bt is attached. Looks like a possible BFS bug(?)
Attachments (4)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (44)
by , 15 years ago
| Attachment: | kdl1_r35025.jpg added |
|---|
comment:1 by , 15 years ago
| Component: | File Systems → File Systems/BFS |
|---|---|
| Owner: | changed from to |
Could be either BFS or kernel, I'll set it to BFS for now.
comment:2 by , 14 years ago
Still present in hrev39156. KDL when WebPositive loading page with the same back trace.
comment:3 by , 14 years ago
Still present in hrev41843 as well.. Got a KDL while browsing in W+ and launching BeShare. Tried to 'continue' out of KDL (sometimes works) but it just escalated into more panics/failed asserts. So I did a 'reboot', then did the exact same thing (launching W+/BeShare) with the same result.. At next reboot, the situation was different: the panic would occur just as the app_server started, making the system unbootable. After a few minutes of experimenting, I found that the "Safe Mode" checkbox in boot menu would get me back in Haiku again. At this point I opened a Terminal and did this:
~> checkfs /boot/
MediaFiles (inode = 2639785), some blocks weren't allocated
multi_audio_settings (inode = 2639784), some blocks weren't allocated
syslog (inode = 2097298), some blocks weren't allocated
syslog.old (inode = 2097362), some blocks weren't allocated, has blocks already set
sshd.pid (inode = 2097299), some blocks weren't allocated
42173 nodes checked,
46 blocks not allocated,
29 blocks already set,
17 blocks could be freed
files 38907
directories 2756
attributes 329
attr. dirs 155
indices 26
~>
Then I rebooted sans Safe Mode, and I did get the full-fledged Haiku this time, including network, allowing me to post this.
BFS is still cranky though:
~> checkfs /boot/
DriveSetup (inode = 2107402), some blocks weren't allocated
syslog.old (inode = 2097298), some blocks weren't allocated
42174 nodes checked,
29 blocks not allocated,
0 blocks already set,
0 blocks could be freed
files 38908
directories 2756
attributes 329
attr. dirs 155
indices 26
~>
I never get to the point of having a "100% clean" status...
I expect this will happen again, since I've had it for the last few days.. So now I use everything in a more 'relaxed' way (no multiples pages in W+ ..etc) so as to steer clear from this panic as much as possible.
follow-up: 6 comment:4 by , 14 years ago
Try this: checkfs -c /boot/.
Ouch, it seems that -c stands for check only and not for correct as I thought. Never mind then.
comment:5 by , 14 years ago
| Cc: | added |
|---|
comment:6 by , 14 years ago
Still present in hrev41843 as well.. Got a KDL while browsing in W+ and launching BeShare.
There were BFS issues while back ago but think they got worked out. Are you only upgrading that partition? Please re-initialize with DriveSetup and see if that fixes things. Make sure to boot off CD or other Haiku partition.
checkfs does a good job for repair but cannot always fix everything. You still have filesystem issues that only will get fixed with re-initialize (DriveSetup).
DriveSetup (inode = 2107402), some blocks weren't allocated
syslog.old (inode = 2097298), some blocks weren't allocated
29 blocks not allocated,
If you continue to use that partition then it will stay corrupt because checkfs is unable to fully fix it, and will only continue to cause filesystem errors. Re-initialize partition to fix it & then test with checkfs. When checkfs says Ok you can test with BeShare & WebPositive to see what happens.
follow-ups: 8 11 comment:7 by , 14 years ago
Thanks for feedback; some more input from me, in order of relevance: 1) I've found a sure-fire way to corrupt the FS! 2) checkfs seems to have restored stuff, oddly.
And 3) I'm definitely looking forward upgrading and doing an Initialize on that partition :-) .. Waiting for RAW images to be available again, so that I can upgrade to my spare Haiku partition "for free" (ISOs are for burning to a CD but I want to do this on the cheap *g*) (and VMWare and anyboot images cannot be double-clicked and mounted apparently).
Here's the odd "clean bill of health" I got after a few iterations over the last few days (I have a very solid and enjoyable system these days, so long as I remember to skip 1).. ):
~> checkfs /boot
44547 nodes checked,
0 blocks not allocated,
0 blocks already set,
0 blocks could be freed
files 40738
directories 3261
attributes 349
attr. dirs 173
indices 26
Not sure if this is reliable or if there could be nasties hidden in an inode somewhere though.
As to 1), I'll file a proper ticket after confirming (or maybe update this ticket, not sure whether the symptoms warrant a new ticket or not), but I'm 99% sure of the following:
- if I use the deskbar's Shutdown/Power off menu item, Haiku shuts down without doing a BFS 'sync' (or whatever it is called), resulting in trouble at next cold start: at a minimum I get checkfs shouting about TrackerSettings, tracker_shelf ..etc (i.e. the kind of things that are written to disk when you shutdown) but most times I get dropped to KDL with the 'vnode PANIC', and it takes 2 "continue" to resume bootup.
- if I use "Restart System" and THEN press the off switch on the tower (at e.g. BIOS POST time) then at next boot Haiku is 100% good.
I guess this occurs only on my PC, others would have caught this thing before if their system failed to "sync' at shutdown.. So gotta confirm first.
Also noted that several fixes to e.g. the VM system have been done since 41843, I'm eager to upgrade to them... (will keep watching haiku-files...)
P.S. This Haiku partition (and the spare one) were initialized before installing Haiku.. I did play with older builds of Haiku (396xx) but these were on a different hard-drive, not this one. This one is fresh 41843 and started misbehaving very quickly.. So confirming my theory about shutdown/sync is prioritary I guess.
comment:8 by , 14 years ago
Replying to ttcoder:
[...] Waiting for RAW images to be available again [...]
Alpha 3 raw images might not be advertised on Get Haiku! but can usually be found on the download servers (as haiku-r1alpha3-image.zip or haiku-r1alpha3-image.tar.xz):-)
comment:9 by , 14 years ago
Replying to ttcoder:
I guess this occurs only on my PC, others would have caught this thing before if their system failed to "sync' at shutdown.. So gotta confirm first.
I shut down via that power off item all the time and I haven't had any issues on either of my Haiku partitions (and they see a considerable amount of filesystem activity since they're often doing full OS builds). One possibility that comes to mind is that there are some hard disks out there which lie about when they've completed operations in order to look better on benchmarks, but those are thankfully uncommon.
comment:10 by , 14 years ago
if I use the deskbar's Shutdown/Power off menu item, Haiku shuts down without doing a BFS 'sync' (or whatever it is called), resulting in trouble at next cold start
Not BFS issue for you. A shutdown-disk sync issue which should go into another ticket. Initialize should fix filesystem for you and worth trying but if sync issue then good chance you will have corruption happening all the time. If you make another ticket then maybe will get fixed but in this ticket not likely to happen.
Something else that maybe affecting you. Seagate drives had faulty BIOSes with certain models. A firmware upgrade for your drive is a very good idea whether you have Seagate or other brand.
http://en.wikipedia.org/wiki/Seagate_Barracuda#7200.11
Try disk firmware upgrade & re-initialize partition and if those do not work then look at filing a disk-shutdown syncing ticket.
comment:11 by , 14 years ago
Replying to ttcoder:
As to 1), I'll file a proper ticket after confirming (or maybe update this ticket, not sure whether the symptoms warrant a new ticket or not), but I'm 99% sure of the following:
- if I use the deskbar's Shutdown/Power off menu item, Haiku shuts down without doing a BFS 'sync' (or whatever it is called), resulting in trouble at next cold start: at a minimum I get checkfs shouting about TrackerSettings, tracker_shelf ..etc (i.e. the kind of things that are written to disk when you shutdown) but most times I get dropped to KDL with the 'vnode PANIC', and it takes 2 "continue" to resume bootup.
- if I use "Restart System" and THEN press the off switch on the tower (at e.g. BIOS POST time) then at next boot Haiku is 100% good.
As mentioned above this is likely related to the specific hardware. It sounds a lot like a disk write-cache that is not flushed and lost when the power turns off, while it still manages to fully flush when rebooting and then turning off a bit later in the BIOS screen. I'm not sure how this flush can be enforced, but I faintly remember seeing some SCSI/ATA flags that can be set to enforce write synchronization that could help here (and might even already be employed when doing a sync).
Another thing that probably doesn't help in this case is that the sync operation that takes place on shutdown (the "Tidying things up a bit" part in the shutdown status window) is run at the very beginning, i.e. while all applications are still running. So apps that store their settings on quit (like Tracker) don't really get that into this sync. Unmounting the FS still triggers the syncing of course, it just makes it more likely that the sync happens "too late" in this case.
comment:13 by , 13 years ago
| patch: | 0 → 1 |
|---|
comment:15 by , 13 years ago
The only reason for the panic is that it is a situation that should not be possible to occur. I don't see what you patch is accomplishing besides hiding the actual bug.
comment:16 by , 13 years ago
| patch: | 1 → 0 |
|---|
comment:17 by , 13 years ago
| Blocking: | 8989 added |
|---|
comment:18 by , 12 years ago
| Blocking: | 9123 added |
|---|
comment:20 by , 12 years ago
I opened ticket 9730 which is closed as a dup of this one. This is consistently reproduceable on a Pentium 3 box I put R1 alpha 4.1 on, by running "installoptionalpackage sdllibs" in the terminal. It happens after it downloads, during the unzip operation.
It only has a 10 GB drive, so I imaged it over my LAN from a Linux live CD to my Win 7 system. When I boot the image in QEMU, it is still consistently reproduceable. If it would help, I will put the image on my web server for devs to download.
There is less than 1 GB of space used in the file system, so 7zip's ultra setting should get it down to a reasonable size. Let me know if it would be useful. I'll keep the image around for a while.
Screenshot from QEMU: http://i.imgur.com/F0z0GoF.png
{kind=link}
comment:21 by , 12 years ago
Does the issue tracked down by bonefish in ticket:3685#comment:3 sound related to this problem?
comment:22 by , 12 years ago
| Blocking: | 3685 added |
|---|
comment:23 by , 11 years ago
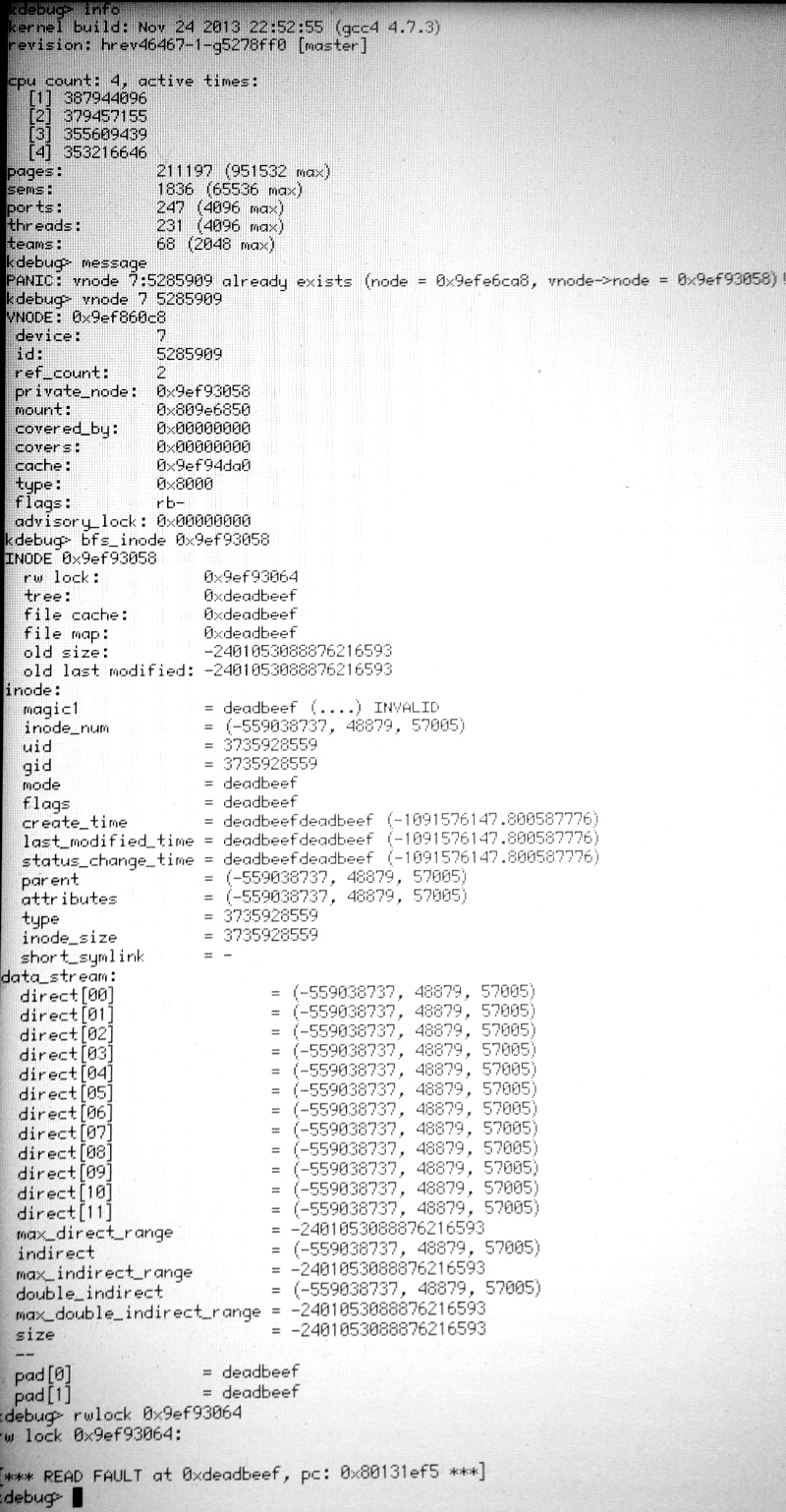
This one happened to me again last weekend while compiling GCC4 with -j8 as a dependency of a port. I've taken a couple of pictures of the KDL session, not sure if they are really relevant. I'm attaching the one where it can be seen that the vnode that already existed has the "removed" and "busy" flags set and that the bfs_inode it references has been freed. I also have pictures with backtraces of the other running threads and their io_contexts and the bfs_inode output for the duplicate vnode, just in case. I tried to follow the code somewhat but as of yet haven't found anything, pointers welcome.
by , 11 years ago
| Attachment: | duplicate_removed_busy_freed.jpeg added |
|---|
KDL screenshot showing the existing vnode to be removed and busy and the bfs_inode behind it to be freed.
comment:24 by , 11 years ago
AFAICT a BFS Inode is deleted only in bfs_get_vnode() (error case and irrelevant here), in bfs_put_vnode(), and in bfs_remove_vnode(). From the VFS point of view which of the latter two is called doesn't really matter. Given that the "removed" flag is set it should be bfs_remove_vnode(). Both are called only from free_vnode(), and bfs_get_vnode() potentially also in get_vnode() in case of an error creating a special subnode. Since I doubt that GCC's build system creates a FIFO or socket file, I think it is safe to assume that free_vnode() has been called. Given that the vnode structure itself has not been overwritten with 0xdeadbeef yet, I would assume that free_vnode() has not finished yet.
The problem is that when create_new_vnode_and_lock() finds a preexisting vnode, it doesn't check its "busy" flag. So it may return a vnode that is doomed and doesn't already exist anymore in the FS. Just like get_vnode() it should check the busy flag and wait for the vnode to become unbusy or disappear.
That change would also fix #9839 (new_vnode() and publish_vnode() use create_new_vnode_and_lock()), but as mentioned there, it would also introduce a potential deadlock.
comment:25 by , 10 years ago
Daoick (from IRC) has this bug, and says it happens about twice per day for him. (He can't comment here due to #12030). He's got a Haiku install on real hardware, a Lenovo laptop with 8GB of RAM and a SSD. He says Linux works very reliably on it.
He says that this happens when the system is under heavy load (e.g. compiling GCC), and afterwards, the partition is corrupted and Haiku just endlessly reboots trying to boot from it, and that checkfs is totally useless in attempting to repair the partition.
My vote is to elevate this to a blocker -- at least for R1 anyway.
comment:27 by , 10 years ago
At least he hasn't changed his story much. I'd say just leave the ticket here. I haven't seen this bug for years now, and I do quite some stuff with Haiku.
comment:28 by , 10 years ago
Just for the record, I did see it myself once a few weeks ago, though it was the first time in years.
comment:29 by , 10 years ago
The bug is still there, no question about that; bonefish nicely investigated it. However, I question that he manages to reproduce it that often. Even twice a day. Ever asked yourself what he could do so important that he goes trough all the hassle to install Haiku twice a day? :-)
comment:30 by , 10 years ago
Not disagreeing about the troll, just misinterpreted your comment about never seeing it as possibly implying it had already been fixed.
comment:31 by , 8 years ago
| Blocking: | 13051 added |
|---|
comment:32 by , 8 years ago
| Blocking: | 7865 added |
|---|
comment:33 by , 8 years ago
| Milestone: | R1 → R1/beta1 |
|---|
I'm bumping this to beta1, because it is rather easy to trigger on the package build slaves, often in mktemp family of APIs. Either bash or gcc creating a temp file while building something will panic the machine. This is a problem when we need reliable package builder machines. It is hard to recover them from KDL remotely.
comment:34 by , 8 years ago
| Status: | new → in-progress |
|---|
comment:36 by , 8 years ago
| Resolution: | → fixed |
|---|---|
| Status: | in-progress → closed |
For the first time tonight, my build slave got through a complete build of the release branch without hitting this even once (there were other problems, but it's getting better). Thanks for working on this!
comment:38 by , 7 years ago
| Blocking: | 14297 added |
|---|
comment:39 by , 6 years ago
| Blocking: | 7952 added |
|---|
comment:40 by , 6 years ago
| Blocking: | 7608 added |
|---|
KDL of crash running svn