

#8345 closed bug (fixed)
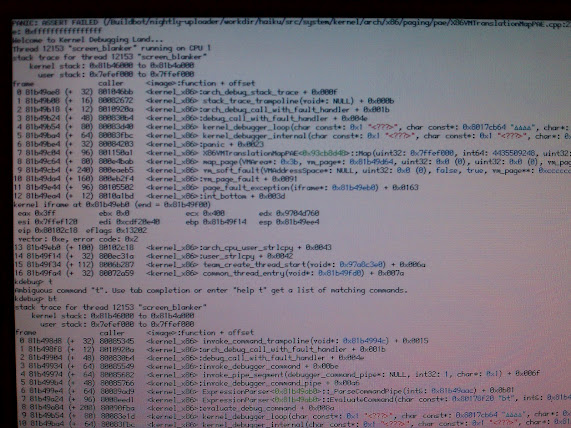
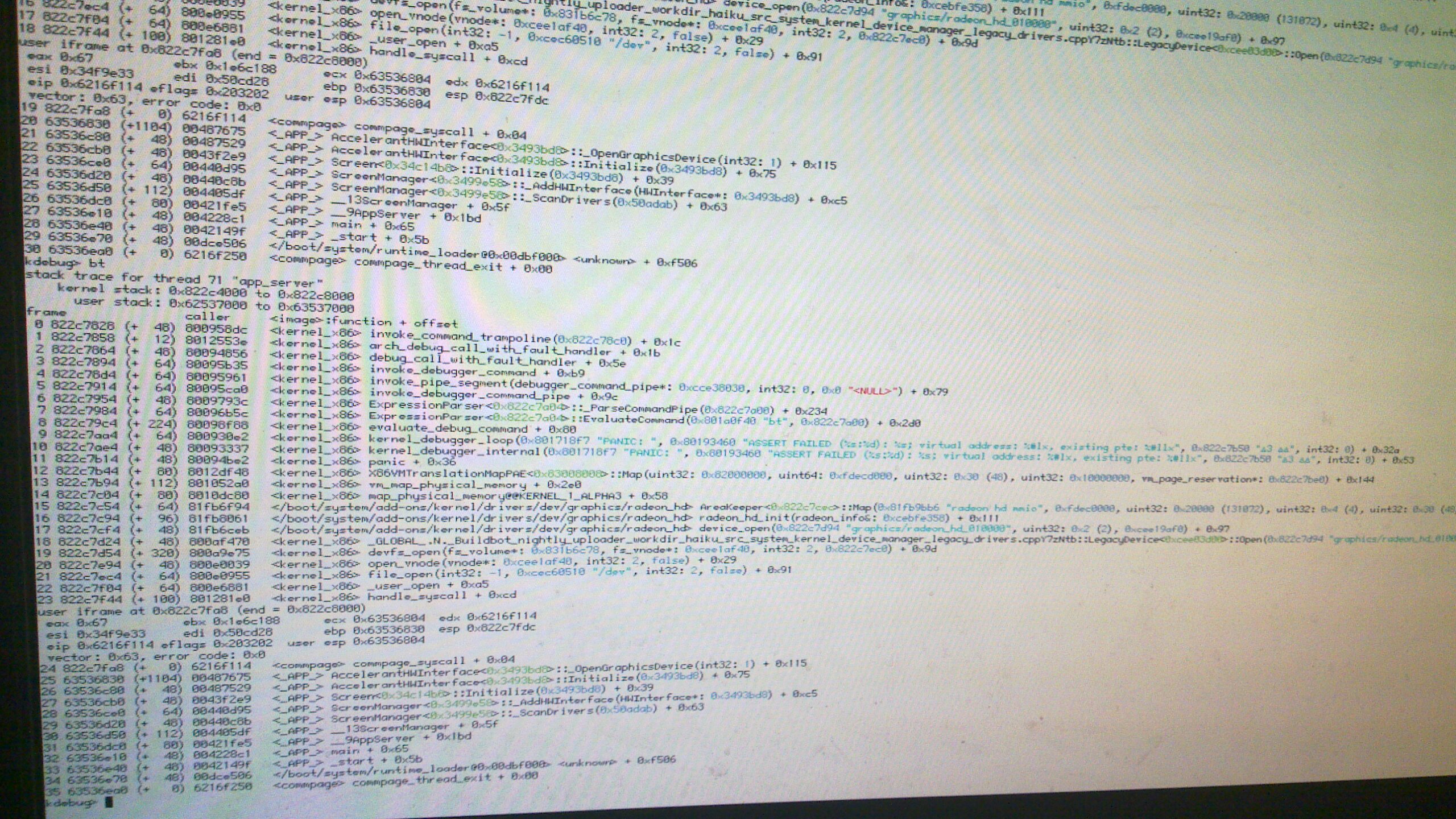
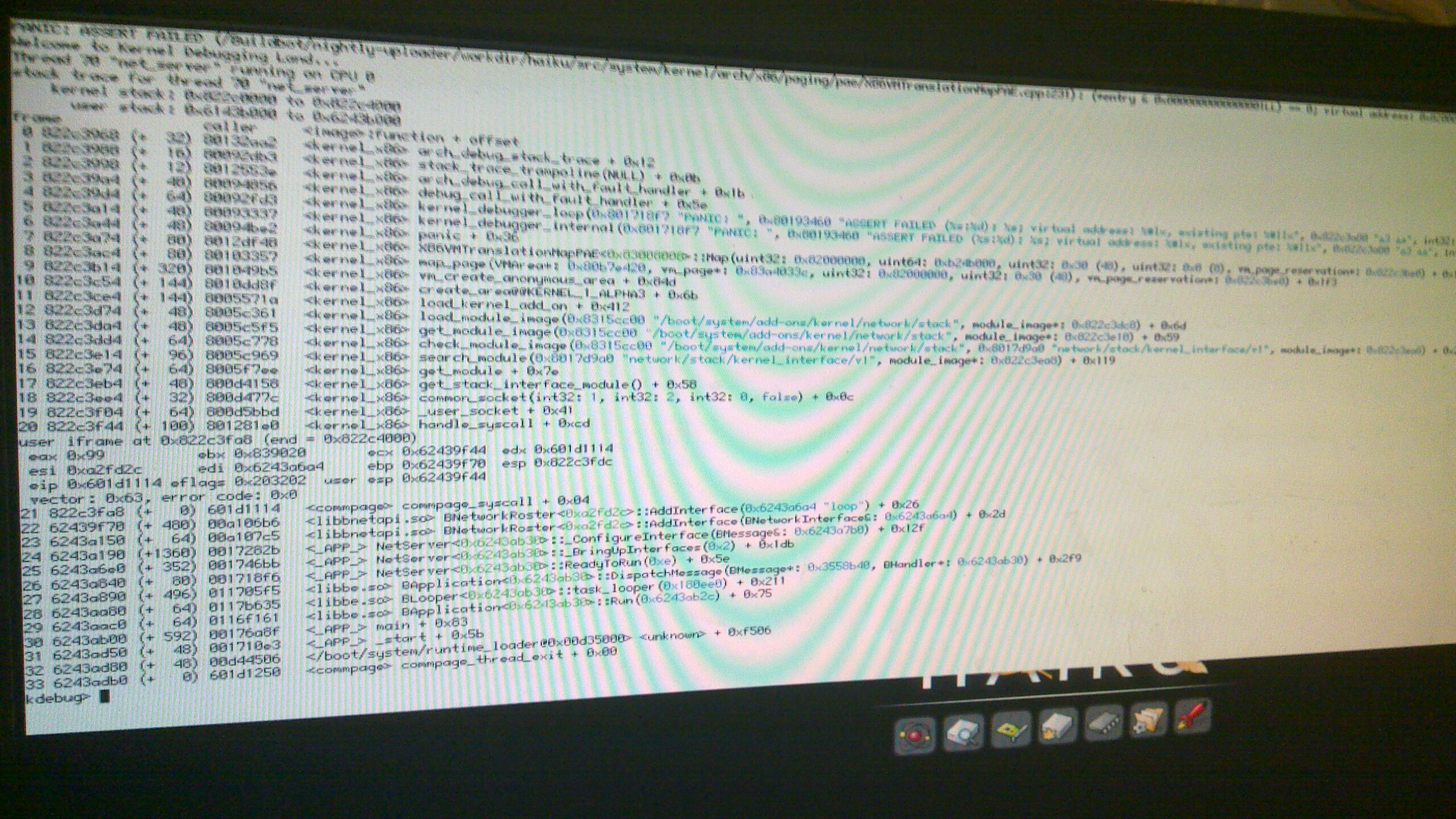
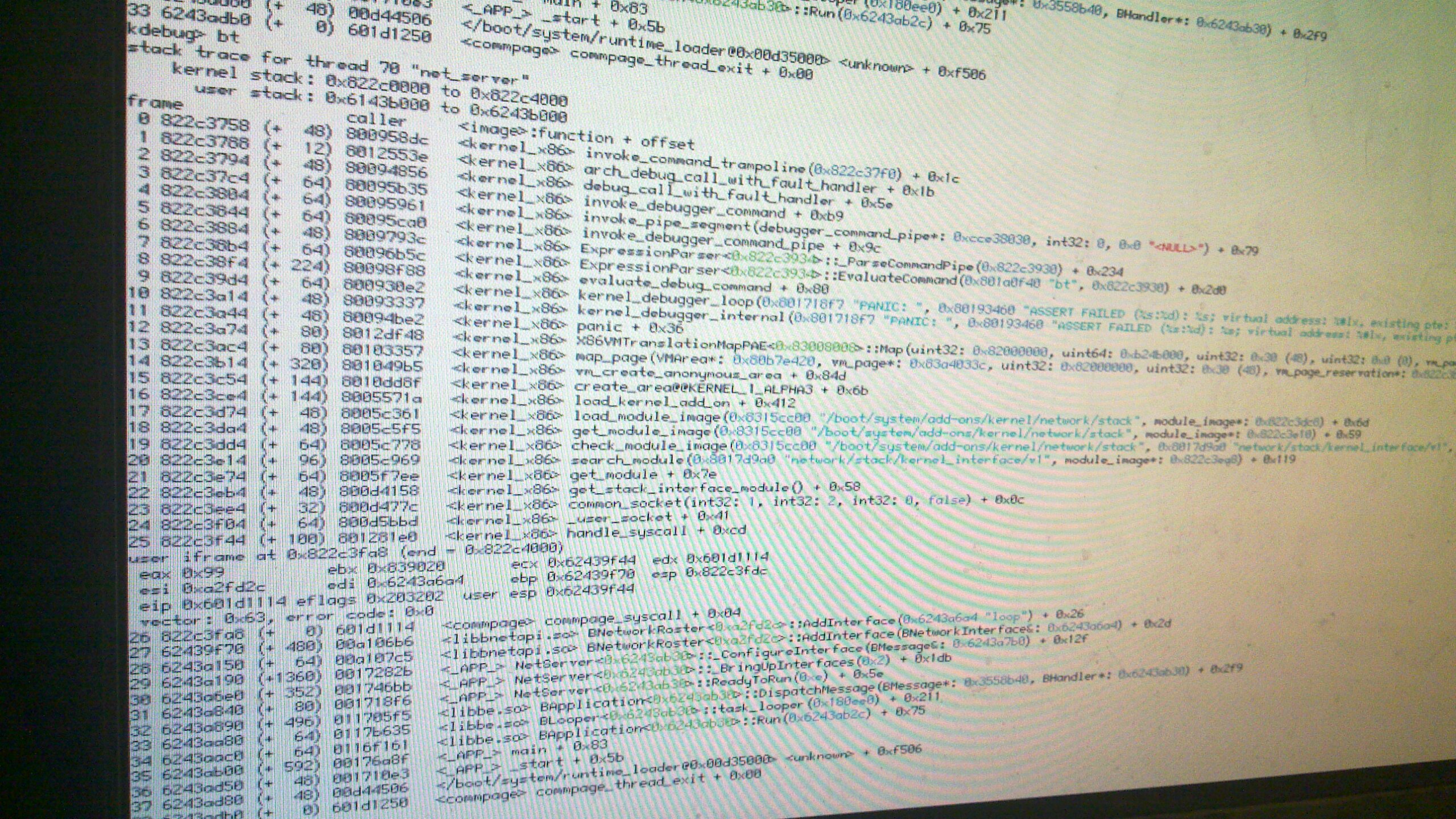
PANIC: ASSERT FAILED ... x86/paging/pae/x86VMTranslationMapPAE.cpp:231
| Reported by: | kallisti5 | Owned by: | bonefish |
|---|---|---|---|
| Priority: | high | Milestone: | R1/beta1 |
| Component: | System/Kernel | Version: | R1/Development |
| Keywords: | vm pae | Cc: | smc.collins@…, mdisreali@…, umccullough, degea@… |
| Blocked By: | Blocking: | #9435, #9520, #9677 | |
| Platform: | x86 |
Description (last modified by )
I've seen this a few times now randomly after doing lots of compiling under Haiku GCC4...
PANIC: ASSERT FAILED ... x86/paging/pae/x86VMTranslationMapPAE.cpp:231 (*entry & 0x0000000000000001LL) == 0; virtual address: 0x7ffef000, existing pte: 0xffffffffffffffff
Attachments (20)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (106)
comment:1 by , 13 years ago
| Description: | modified (diff) |
|---|
by , 13 years ago
| Attachment: | IMG_20120220_131211.jpg added |
|---|
by , 13 years ago
| Attachment: | IMG_20120220_131211.2.jpg added |
|---|
by , 13 years ago
| Attachment: | IMG_20120220_131220.jpg added |
|---|
comment:2 by , 13 years ago
comment:3 by , 13 years ago
| Milestone: | R1 → R1/alpha4 |
|---|---|
| Priority: | normal → critical |
speaking to mmlr, he mentions also seeing this issue:
3:20 <@mmlr> kallisti5: I've seen that translationmap error as well 13:20 <@kallisti5> mmlr: thats good to hear :) 13:20 <@kallisti5> i've seen it quite a few times as of late 13:20 <@kallisti5> mmlr: you don't use radeon_hd do you? 13:20 <@mmlr> I don't 13:21 <@kallisti5> i'm just asking because it came from screen_blanker 13:21 <@kallisti5> ok 13:21 <@mmlr> I think it's some kind of edge case when nearly exhausting physical pages 13:21 <@kallisti5> mmlr: think it may be a blocker for a4? 13:21 <@mmlr> I've seen it last while stress testing things with the guard heap 13:21 <@mmlr> I originally thought it might be related to me manipulating the entries directly 13:22 <@mmlr> but that confirms it happens without guard heap as well 13:22 <@mmlr> well, technically it is kind of critical 13:23 <@mmlr> not sure if someone actually is going to have the time to look into it
Marking a critical bug for alpha4, the random system crash bugs are pretty annoying :)
comment:4 by , 13 years ago
| Owner: | changed from to |
|---|---|
| Status: | new → assigned |
comment:5 by , 13 years ago
Kallisti, I get this crash allot to, I can get around it by disablling all but one cpu core on my machine. Could you try that on your end as well ? I use pulse to disable all but one cpu core.
comment:6 by , 13 years ago
| Cc: | added |
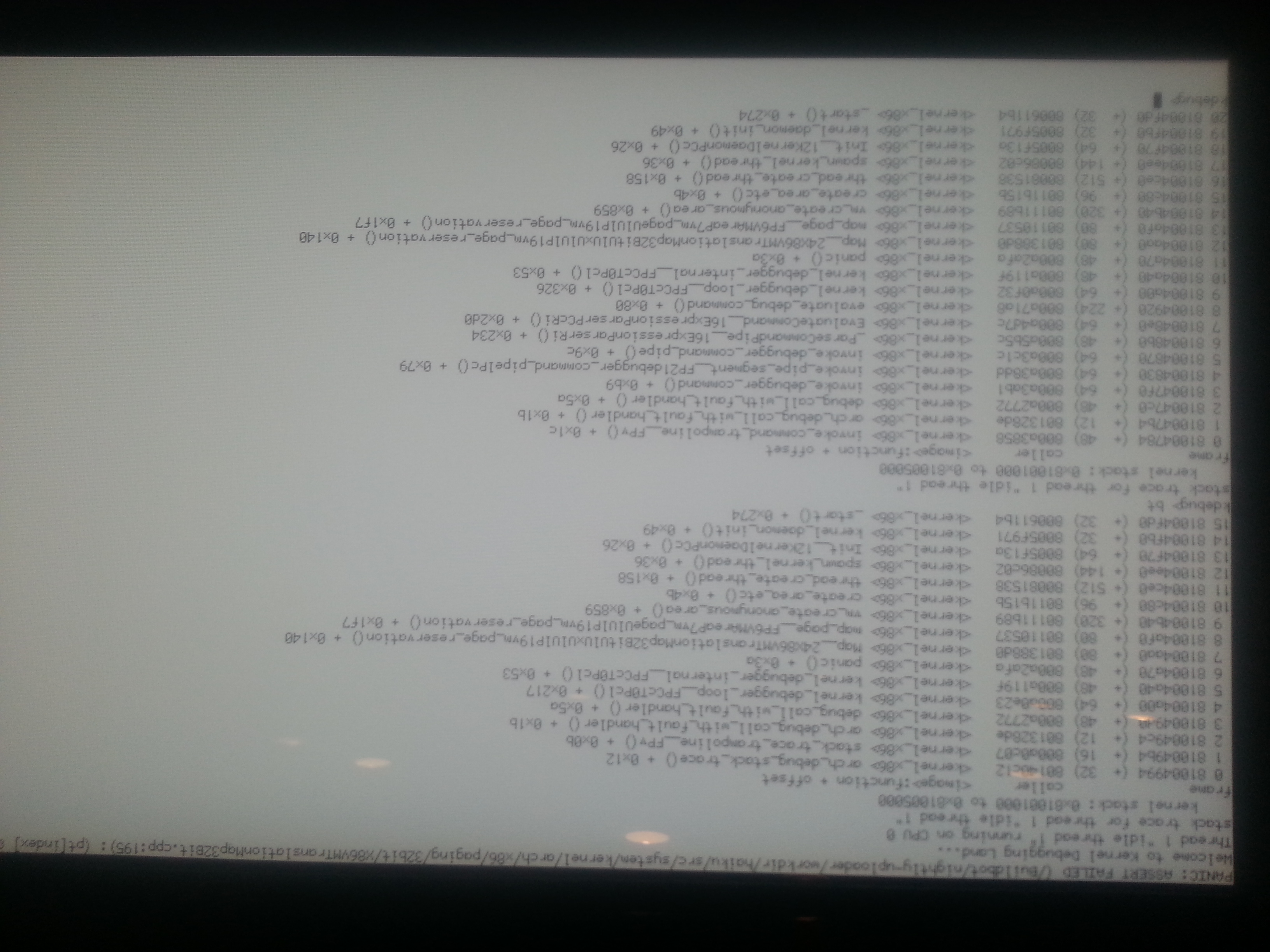
|---|
comment:7 by , 13 years ago
Still happens on hrev44242
I disabled hyper-threading which drops the cores to one vs two.. Will report back status after some testing.
comment:8 by , 13 years ago
| Description: | modified (diff) |
|---|
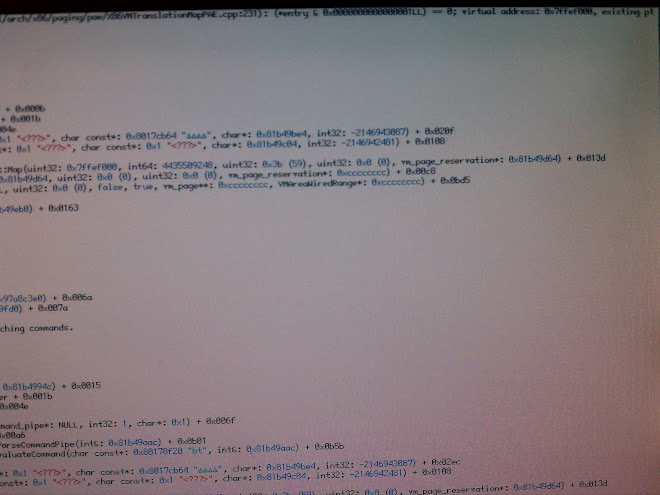
I just noticed I hadn't commented on that one yet. While the issue itself isn't all that critical the underlying cause possibly is. The Map() method of the translation map maps a virtual address to a physical page. That is achieved by writing a respectively composed value (the physical page address mixed with flags for the access permissions and other stuff) into a respective page table entry (PTE). It is expected that when Map() is invoked that the virtual address is not already mapped to a physical page. That's what the assert checks (the "page present" flag of the PTE).
Since the new value is written to the PTE, it will be OK afterwards -- the panic is continuable -- but that the previous value got there is worrisome. Even more so since in this case the value is ~0, something never written by the paging code. So someone else wrote into that page table. Not a comforting thought.
Michael mentioned that he thinks that this happens when nearly exhausting physical pages. When it happens next time, please run a page_stats so we can verify the theory. Also, it would be interesting in what situation the assert was triggered. Like how long the machine ran and what you did before. Obviously a reproducible test case would be perfect.
follow-up: 10 comment:9 by , 13 years ago
I've tried continuing on the panic, however it reoccurs over and over (same crash though)
I did disable hyperthreading in the bios (reducing the cpu count to 1 from 2) and the crash seems to be gone.
Is this a "multi-cpu-smp" issue or strictly a "hyperthreading cpu" issue? SeanCollins, do you have a Pentium 4 HT cpu, or a multi-core cpu?
Steps to reproduce for me...
- Multiple HT cores
- Disable screensaver and screen blanking
- Do some work, compile stuff
- *crash* after a few minutes to one hour.
comment:10 by , 13 years ago
Replying to kallisti5:
Is this a "multi-cpu-smp" issue or strictly a "hyperthreading cpu" issue? SeanCollins, do you have a Pentium 4 HT cpu, or a multi-core cpu?
As another data point, quad core w/ hyperthreading here (ergo 8 CPUs visible to the OS), and I've never seen this under all kinds of punishing workloads. That having been said, 8GB of physical RAM is available, so if it's the low memory condition triggering it, then I'm not easily going to hit that. However, if Ingo's theory about something else overwriting the page tables is correct, then it seems plausible that a particular misbehaving driver in your case might be triggering it, else one would expect it to be much more widespread. The type of CPUs involved really doesn't have much to do with how the memory mapping's handled per se (excepting the obvious availability or absence of PAE), and from a multitasking standpoint, if anything HT should be less strenuous than true multicore since the circumstances under which it can multitask are more limited.
follow-up: 15 comment:11 by , 13 years ago
Yeah, I definitely think you're right here.
I have a similar Optiplex GX620 next to me with HT that I can't seem to reproduce the issue on.
SeanCollins, could you get a list of drivers on the your system? I'll do the same for mine and we can see what aligns.
listimage | grep drivers
comment:12 by , 13 years ago
here is the working Optiplex GX620 as a baseline:
~> listimage | grep drivers 54 /boot/system/add-ons/kernel/drivers/dev/console 0x8189c000 0x8189e000 0 0 55 /boot/system/add-ons/kernel/drivers/dev/dprintf 0x8176d000 0x8176e000 0 0 56 /boot/system/add-ons/kernel/drivers/dev/null 0x816d2000 0x816d3000 0 0 57 /boot/system/add-ons/kernel/drivers/dev/random 0x81666000 0x81669000 0 0 58 /boot/system/add-ons/kernel/drivers/dev/tty 0x81773000 0x8177b000 0 0 59 /boot/system/add-ons/kernel/drivers/dev/zero 0x8166a000 0x8166b000 0 0 964 /boot/system/add-ons/kernel/drivers/dev/graphics/radeon_hd 0x81126000 0x8112b000 0 0 985 /boot/system/add-ons/kernel/drivers/dev/graphics/vesa 0x81883000 0x81886000 0 0 991 /boot/system/add-ons/kernel/drivers/dev/net/3com 0xcd784000 0xcd79c000 0 0 1001 /boot/system/add-ons/kernel/drivers/dev/net/broadcom570x 0xcd79e000 0xcd7bb000 0 0 1157 /boot/system/add-ons/kernel/drivers/dev/input/usb_hid 0x81ab2000 0x81abe000 0 0 1183 /boot/system/add-ons/kernel/drivers/dev/input/wacom 0x81abf000 0x81ac1000 0 0 1630 /boot/system/add-ons/kernel/drivers/dev/power/acpi_button 0xcd7fe000 0xcd7ff000 0 0 1660 /boot/system/add-ons/kernel/drivers/dev/bus/usb_raw 0x81b63000 0x81b65000 0 0 1664 /boot/system/add-ons/kernel/drivers/dev/audio/hmulti/auich 0x81b8f000 0x81b99000 0 0 1684 /boot/system/add-ons/kernel/drivers/dev/audio/hmulti/hda 0x81bb2000 0x81bbc000 0 0
comment:13 by , 13 years ago
| Keywords: | vm pae added; x86VMTranslationMapPAE removed |
|---|
I wouldn't rule out a driver issue, but it might be a VM issue as well. There's ticket #2718 which hints at some page management problem. The ticket is rather old and might have been fixed in the meantime (e.g. when I did some extensive VM work two years ago).
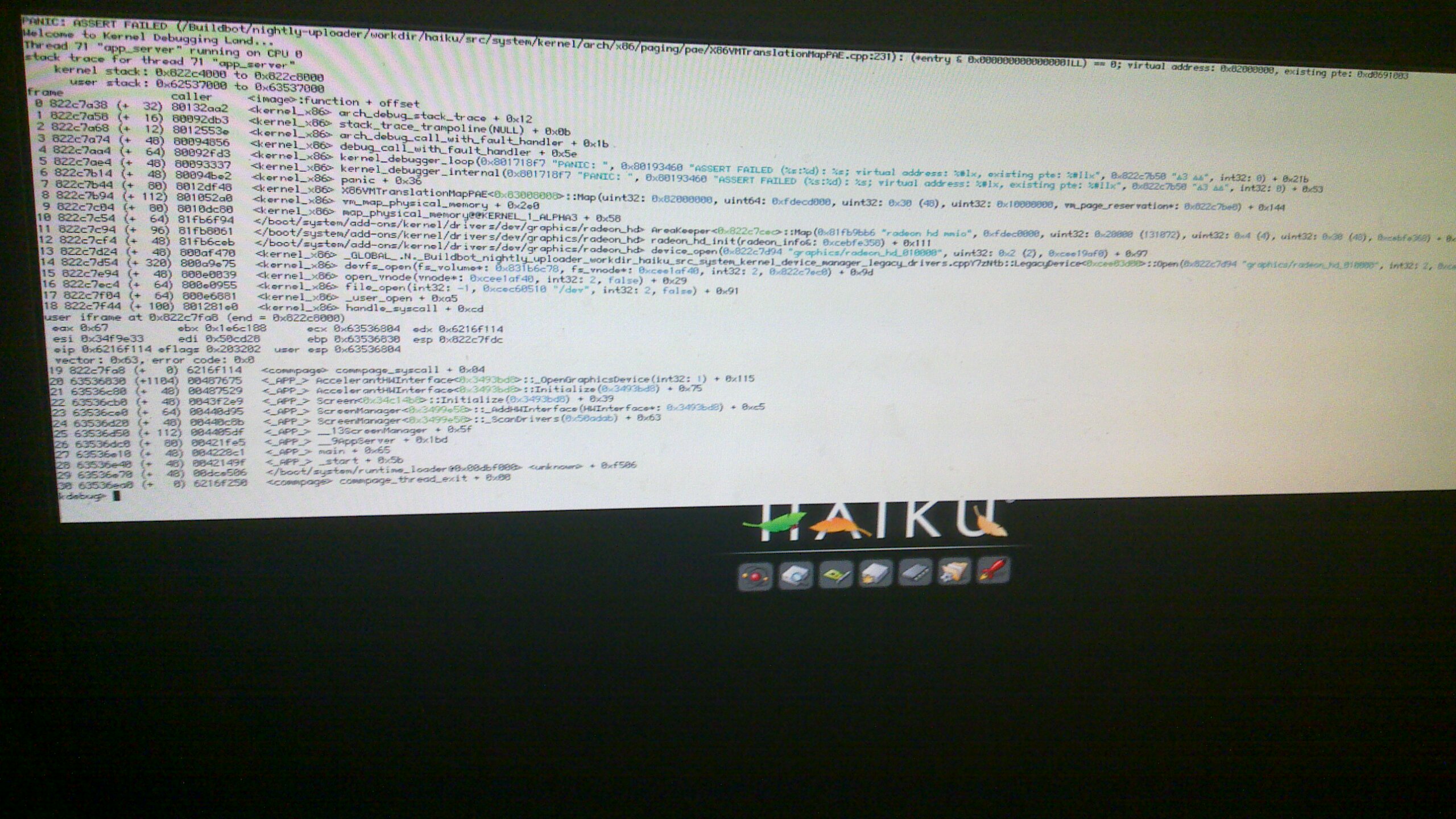
But very interesting is ticket #7904. There have been issues with VirtualBox for ages -- and IIRC at least initially VB indeed didn't emulate the architecture correctly -- so I was assuming this could just be some weird VB issue. However, the third KDL picture in that ticket shows the same assert that we see here, just in the 32-bit paging code. The other two KDL pictures show an assert in the higher-level page management code.
So it may not be a VB issue. It is possible that the way VB emulates multiple CPUs just triggers the Haiku bug more likely. It would also suggest that the bug is in the page management code. E.g. a free page being handed out twice would also easily explain overwritten memory. It's probably worth trying to track this down with VB.
@kallisti5: I assume you've got at least 4 GB RAM and from your description what you do it doesn't sound like you would have exhausted that much memory. A page_stats wouldn't harm anyway.
comment:14 by , 13 years ago
Yeah. the machine has 5.6GB ram installed and is a small form factor Optiplex GX620
Drivers on the failing system:
~> listimage | grep driver 54 /boot/system/add-ons/kernel/drivers/dev/console 0x8189a000 0x8189c000 0 0 55 /boot/system/add-ons/kernel/drivers/dev/dprintf 0x8176d000 0x8176e000 0 0 56 /boot/system/add-ons/kernel/drivers/dev/null 0x81665000 0x81666000 0 0 57 /boot/system/add-ons/kernel/drivers/dev/random 0x81667000 0x8166a000 0 0 58 /boot/system/add-ons/kernel/drivers/dev/tty 0x81773000 0x8177b000 0 0 59 /boot/system/add-ons/kernel/drivers/dev/zero 0x8166b000 0x8166c000 0 0 872 /boot/system/add-ons/kernel/drivers/dev/graphics/radeon_hd 0x81109000 0x8110e000 0 0 896 /boot/system/add-ons/kernel/drivers/dev/graphics/vesa 0x81138000 0x8113b000 0 0 908 /boot/system/add-ons/kernel/drivers/dev/net/broadcom570x 0xcd754000 0xcd771000 0 0 1104 /boot/system/add-ons/kernel/drivers/dev/input/usb_hid 0xde80c000 0xde818000 0 0 1130 /boot/system/add-ons/kernel/drivers/dev/input/wacom 0x81d3d000 0x81d3f000 0 0 1464 /boot/system/add-ons/kernel/drivers/dev/power/acpi_button 0xcd7ce000 0xcd7cf000 0 0 1566 /boot/system/add-ons/kernel/drivers/dev/bus/usb_raw 0x81919000 0x8191b000 0 0 1570 /boot/system/add-ons/kernel/drivers/dev/audio/hmulti/auich 0x81d85000 0x81d8f000 0 0
working on reproducing issue now for a page_stats output.
comment:15 by , 13 years ago
Replying to kallisti5:
Yeah, I definitely think you're right here.
I have a similar Optiplex GX620 next to me with HT that I can't seem to reproduce the issue on.
SeanCollins, could you get a list of drivers on the your system? I'll do the same for mine and we can see what aligns.
listimage | grep drivers
Sure thing
54 /boot/system/add-ons/kernel/drivers/dev/console 0x819c3000 0x819c5000 0 0 55 /boot/system/add-ons/kernel/drivers/dev/dprintf 0x81a64000 0x81a65000 0 0 56 /boot/system/add-ons/kernel/drivers/dev/null 0x81a21000 0x81a22000 0 0 57 /boot/system/add-ons/kernel/drivers/dev/random 0x819c6000 0x819c9000 0 0 58 /boot/system/add-ons/kernel/drivers/dev/tty 0x81ece000 0x81ed7000 0 0 59 /boot/system/add-ons/kernel/drivers/dev/zero 0x819ca000 0x819cb000 0 0 1137 /boot/system/add-ons/kernel/drivers/dev/graphics/radeon_hd 0x81156000 0x8115c000 0 0 1139 /boot/system/add-ons/kernel/drivers/dev/graphics/vesa 0x81139000 0x8113d000 0 0 1167 /boot/system/add-ons/kernel/drivers/dev/net/rtl8139 0x816c0000 0x816d7000 0 0 1168 /boot/system/add-ons/kernel/drivers/dev/net/rtl81xx 0x816ea000 0x81704000 0 0 1289 /boot/system/add-ons/kernel/drivers/dev/input/usb_hid 0x8195d000 0x81969000 0 0 1290 /boot/system/add-ons/kernel/drivers/dev/input/wacom 0x8196a000 0x8196c000 0 0 1701 /boot/system/add-ons/kernel/drivers/dev/power/acpi_button 0x818f5000 0x818f6000 0 0 1723 /boot/system/add-ons/kernel/drivers/dev/midi/ice1712 0xcda22000 0xcda28000 0 0 1824 /boot/system/add-ons/kernel/drivers/dev/bus/fw_raw 0x8226c000 0x8226f000 0 0 1826 /boot/system/add-ons/kernel/drivers/dev/bus/usb_raw 0x822f5000 0x822f7000 0 0 1832 /boot/system/add-ons/kernel/drivers/dev/audio/hmulti/hda 0x82300000 0x8230a000 0 0 TEAM 642 (/bin/grep drivers): ~>
Some early pentium 4 chips with HT will not even boot without crashing the kernel at memory setup. I have a few of these cpu's, if someone wants one to test with. I have all AMD hardware in my machine. And this diffenitly only happens when using multiple cpu's during code compile. I can't reproduce it any other time. I will say that it does seem to happen more often when the cached memory gets full, IE when the cached memory useage gets close to the max physical memory, this seems to occur more often.so maybe its some goofy issue with multiple cpu cores acessing cached memory ?? or maybe things are being cached in the l2/l3 areas of the cpu ? But this definately occurs on my thuban 6 core cpu only when compiling with all 6 core enabled. I can disable 5 of these core, no problem, and its not a particular core, I tried that to as a way to rule out a bad cpu.
comment:16 by , 13 years ago
The page_stats show > 4GB of free pages. I guess this refutes the theory that it happens when free memory is nearly exhausted.
comment:17 by , 13 years ago
| Cc: | added |
|---|
comment:18 by , 13 years ago
I just realized my "working" GX620 only has 2GB ram in it.. so it may also suffer the same issue. I'm trying to find a few sticks to bump it it to 4GB+ now.
by , 13 years ago
| Attachment: | Haiku_8345_Ticket.patch added |
|---|
comment:19 by , 13 years ago
| patch: | 0 → 1 |
|---|
follow-up: 21 comment:20 by , 13 years ago
Added Haiku_8345_Ticket.patch
Sample code, think it is a presedence issue.
#include <stdio.h>
int main(void) {
int i = 0; int table[4096];
for (i = 0; i < 4096; i++) {
table[i] = i +2;
}
printf("Test One %d %d\n", table + 2048 / 1024 % 512, table[2048] / 1024 % 512);
exit(0);
}
follow-up: 39 comment:21 by , 13 years ago
Replying to haxworx:
Your test case doesn't actually match your patch ; the patch and the original code are logically equivalent ( / and % have higher precedence than +), but the expression that your sample code uses to calculate the second part isn't the same, and not correct for this case anyways.
follow-up: 24 comment:22 by , 12 years ago
I can confirm that this bug still exists on the latest R1A4 RC. (hrevr1alpha4-44608)
So far the following has been established:
- Occurs on gcc2 and gcc4 images
- Occurs with one or multiple cpu cores
- Only occurs when system memory is > 4GB (PAE active)
- Takes some time to occur. Generally if I boot the system, disable the screensaver, and let it sit overnight it:
- Crashes on its own.
- Crashes as soon as you move the mouse ~1 inch
comment:23 by , 12 years ago
I suggest due to the infrequency of this and the required memory to make it occur, that we not consider it an alpha4 blocker.
follow-ups: 26 52 comment:24 by , 12 years ago
Replying to kallisti5:
I can confirm that this bug still exists on the latest R1A4 RC. (hrevr1alpha4-44608)
So far the following has been established:
- Occurs on gcc2 and gcc4 images
- Occurs with one or multiple cpu cores
In your and Sean's comments above I actually read that it doesn't happen with only one CPU (one logical CPU). That would be consistent with the observations in #7904.
- Only occurs when system memory is > 4GB (PAE active)
AFAICT no one has confirmed yet that on the same machine the problem does cease to occur with PAE disabled. #7904 demonstrates that a KDL with the analogous stack trace is possible with 32 bit paging. I would consider it more likely that the issue occurs only on specific CPU architectures or models. It would be nice, if everyone who has tried to reproduce the issue could list their corresponding CPU models for positive and negative results.
I have a negative for Intel Core i7 860.
Also, it would be interesting to learn whether the machines that have the issue also test positive for #7904. Since that test is much quicker and more reliable, it would be more suitable for debugging.
Replying to leavengood:
I suggest due to the infrequency of this and the required memory to make it occur, that we not consider it an alpha4 blocker.
Sure. If #7904 refers to the same problem, the issue isn't new anyway.
follow-up: 27 comment:25 by , 12 years ago
Bonefish, I can't reproduce 7904, and I tried for a good 20 minutes, I have run out of things to install.
If its helpful, I have a p4 cpu that panics just like this, simply by booting it to userland. Maybe I should just chuck the CPU and MB in the mail to you and see if it helps find the issue. I can tell you its got something to do with hyperthreading, becuase if you turn off hyperthreading, the machine works fine. If you want it, I'll chuck it in a small box and send it across the pond. At this point its the best hope to discovering the problem imho and shipping ain't no big cost.
comment:26 by , 12 years ago
Replying to bonefish:
I have a negative for Intel Core i7 860.
Ditto negative on i7-2600k w/ 8GB of RAM.
follow-up: 29 comment:27 by , 12 years ago
Replying to SeanCollins:
Bonefish, I can't reproduce 7904, and I tried for a good 20 minutes, I have run out of things to install.
OK, thanks for trying!
If its helpful, I have a p4 cpu that panics just like this, simply by booting it to userland. Maybe I should just chuck the CPU and MB in the mail to you and see if it helps find the issue. I can tell you its got something to do with hyperthreading, becuase if you turn off hyperthreading, the machine works fine. If you want it, I'll chuck it in a small box and send it across the pond. At this point its the best hope to discovering the problem imho and shipping ain't no big cost.
I have an old unplugged P4 box sitting around myself. I guess I should try that one first. I don't quite recall how much memory it has, though. Might only be 2 GB.
comment:28 by , 12 years ago
Bonefish, I can't reproduce 7904, and I tried for a good 20 minutes, I have run out of things to install.
It generally takes a good hour or two to reproduce.
I should note that I've seen this bug on mostly p4 era Dell Optiplex machines such as the GX620.
I have the hardware available, if anyone can think of anything that may help us troubleshoot this let me know! I'll get it ASAP
comment:29 by , 12 years ago
Replying to bonefish:
Replying to SeanCollins:
Bonefish, I can't reproduce 7904, and I tried for a good 20 minutes, I have run out of things to install.
OK, thanks for trying!
If its helpful, I have a p4 cpu that panics just like this, simply by booting it to userland. Maybe I should just chuck the CPU and MB in the mail to you and see if it helps find the issue. I can tell you its got something to do with hyperthreading, becuase if you turn off hyperthreading, the machine works fine. If you want it, I'll chuck it in a small box and send it across the pond. At this point its the best hope to discovering the problem imho and shipping ain't no big cost.
I have an old unplugged P4 box sitting around myself. I guess I should try that one first. I don't quite recall how much memory it has, though. Might only be 2 GB.
Ram did not matter on the p4 machines I have seen,
comment:30 by , 12 years ago
I've also seen this one from time to time on a i7 3770s (4 cores + hyperthreading), 8 GB of RAM.
comment:31 by , 12 years ago
| patch: | 1 → 0 |
|---|
@bonefish other kernel experts
Disable the virtual memory on your machine, it seems to get mine to trip into this issue much easier with it off.
comment:32 by , 12 years ago
| patch: | 0 → 1 |
|---|
comment:34 by , 12 years ago
| Milestone: | R1/alpha4 → R1/beta1 |
|---|
No recent action has been taken on this one, so moving to the next milestone.
comment:35 by , 12 years ago
I just saw this issue on my new IvyBridge ultrabook while compiling clang. gcc4. 10GB DDR3 Ram.
comment:36 by , 12 years ago
I booted my IvyBridge laptop again and tried compiling clang. While compiling, I noticed my laptop had 100% memory usage. As this laptop has 10GB ram installed... it raised a few eyebrows. I entered the kdl by keystroke and took a screenshot of the page_stats.
EDIT: Nevermind. I think the clang bep is creating too many threads.
comment:37 by , 12 years ago
| Blocking: | 9435 added |
|---|
comment:38 by , 12 years ago
Same issue for me.
Ϟ 21:52:36 Ϟ ~ listimage | grep drivers 51 /boot/system/add-ons/kernel/drivers/dev/console 0x81706000 0x81708000 0 0 52 /boot/system/add-ons/kernel/drivers/dev/dprintf 0x8176b000 0x8176c000 0 0 53 /boot/system/add-ons/kernel/drivers/dev/null 0x8173e000 0x8173f000 0 0 54 /boot/system/add-ons/kernel/drivers/dev/random 0x81780000 0x81783000 0 0 55 /boot/system/add-ons/kernel/drivers/dev/tty 0x81788000 0x81791000 0 0 56 /boot/system/add-ons/kernel/drivers/dev/zero 0x81745000 0x81746000 0 0 905 /boot/system/add-ons/kernel/drivers/dev/graphics/intel_extreme 0x818be000 0x818c3000 0 0 913 /boot/system/add-ons/kernel/drivers/dev/graphics/vesa 0x81666000 0x8166a000 0 0 1097 /boot/system/add-ons/kernel/drivers/dev/net/ipro1000 0x81f36000 0x81f86000 0 0 1230 /boot/system/add-ons/kernel/drivers/dev/input/wacom 0x81fb4000 0x81fb6000 0 0 1754 /boot/system/add-ons/kernel/drivers/dev/power/acpi_button 0x8116c000 0x8116d000 0 0 1868 /boot/system/add-ons/kernel/drivers/dev/bus/usb_raw 0xcd782000 0xcd784000 0 0 1880 /boot/system/add-ons/kernel/drivers/dev/audio/hmulti/hda 0xcd785000 0xcd790000 0 0
comment:39 by , 12 years ago
Replying to anevilyak:
Replying to haxworx:
Your test case doesn't actually match your patch ; the patch and the original code are logically equivalent ( / and % have higher precedence than +), but the expression that your sample code uses to calculate the second part isn't the same, and not correct for this case anyways.
Should attachment:Haiku_8345_Ticket.patch be marked obsolete then?
comment:40 by , 12 years ago
| Blocking: | 9520 added |
|---|
comment:41 by , 12 years ago
| Blocking: | 9677 added |
|---|
follow-up: 43 comment:42 by , 12 years ago
Now that it seems more reproducible, may be interesting to trace pageTable value and pageTableEntry index in that table: is there a pattern regarding pageTable or PTE position or not.
AFAIK, only kernel land stuffs or DMA access could change these PAE tables content over VM shoulder, right?
comment:43 by , 12 years ago
Replying to phoudoin:
Now that it seems more reproducible, may be interesting to trace pageTable value and pageTableEntry index in that table: is there a pattern regarding pageTable or PTE position or not.
The page table is simply some physical page allocated for that purpose. There aren't any address restrictions, so it can be any page. The PTE's address depends on page table address and mapped virtual address. If you mean, whether there's a patter wrt. where the errors occur, I haven't seen any.
AFAIK, only kernel land stuffs or DMA access could change these PAE tables content over VM shoulder, right?
I think the most likely case is that somehow a physical page is doubly-used -- e.g. handed out twice by the page allocation code or not correctly unmapped by someone -- for a page table and at the same time by someone else.
by , 12 years ago
| Attachment: | 20130501_008.jpg added |
|---|
Haiku hrev45595 failing (VESA video, backtrace)
comment:44 by , 12 years ago
Can reproduce with Pentium D 925, 1 GB DDR2, Radeon HD 5450, and SiS 191 ethernet
Attached images are mine, here's Linux output for cpuinfo and lspci in case:
calvin@fulcrum:~$ lspci 00:00.0 Host bridge: Silicon Integrated Systems [SiS] 671MX 00:01.0 PCI bridge: Silicon Integrated Systems [SiS] PCI-to-PCI bridge 00:02.0 ISA bridge: Silicon Integrated Systems [SiS] SiS968 [MuTIOL Media IO] (rev 01) 00:02.5 IDE interface: Silicon Integrated Systems [SiS] 5513 [IDE] (rev 01) 00:03.0 USB Controller: Silicon Integrated Systems [SiS] USB 1.1 Controller (rev 0f) 00:03.1 USB Controller: Silicon Integrated Systems [SiS] USB 1.1 Controller (rev 0f) 00:03.3 USB Controller: Silicon Integrated Systems [SiS] USB 2.0 Controller 00:04.0 Ethernet controller: Silicon Integrated Systems [SiS] 191 Gigabit Ethernet Adapter (rev 02) 00:05.0 IDE interface: Silicon Integrated Systems [SiS] SATA Controller / IDE mode (rev 03) 00:06.0 PCI bridge: Silicon Integrated Systems [SiS] PCI-to-PCI bridge 00:0c.0 FireWire (IEEE 1394): Texas Instruments TSB43AB23 IEEE-1394a-2000 Controller (PHY/Link) 00:0f.0 Audio device: Silicon Integrated Systems [SiS] Azalia Audio Controller 01:00.0 VGA compatible controller: ATI Technologies Inc Cedar PRO [Radeon HD 5450] 01:00.1 Audio device: ATI Technologies Inc Manhattan HDMI Audio [Mobility Radeon HD 5000 Series] calvin@fulcrum:~$ cat /proc/cpuinfo processor : 0 vendor_id : GenuineIntel cpu family : 15 model : 6 model name : Intel(R) Pentium(R) D CPU 3.00GHz stepping : 5 microcode : 0xb cpu MHz : 2400.000 cache size : 2048 KB physical id : 0 siblings : 2 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 6 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx lm constant_tsc pebs bts nopl pni dtes64 monitor ds_cpl est cid cx16 xtpr pdcm lahf_lm bogomips : 5999.87 clflush size : 64 cache_alignment : 128 address sizes : 36 bits physical, 48 bits virtual power management: processor : 1 vendor_id : GenuineIntel cpu family : 15 model : 6 model name : Intel(R) Pentium(R) D CPU 3.00GHz stepping : 5 microcode : 0xb cpu MHz : 2400.000 cache size : 2048 KB physical id : 0 siblings : 2 core id : 1 cpu cores : 2 apicid : 1 initial apicid : 1 fpu : yes fpu_exception : yes cpuid level : 6 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx lm constant_tsc pebs bts nopl pni dtes64 monitor ds_cpl est cid cx16 xtpr pdcm lahf_lm bogomips : 6000.29 clflush size : 64 cache_alignment : 128 address sizes : 36 bits physical, 48 bits virtual power management:
comment:45 by , 12 years ago
| Cc: | added |
|---|
comment:46 by , 12 years ago
I hit this assertion each time I try to build Haiku now. I tried disabling SMP or limiting memory to 4GB in Haiku boot menu, with no success. The KDL happens near the end of Haiku build, usually when unzipping alternative-system-libs to the partition. This is rather annoying for me.
Haiku is installed on internal HD and building to internal HD, but the source is located on an USB-connected SSD. Not sure if that's of any help... lspci and lsusb output below.
00:00.0 Host bridge: Intel Corporation Mobile 4 Series Chipset Memory Controller Hub (rev 07) 00:02.0 VGA compatible controller: Intel Corporation Mobile 4 Series Chipset Integrated Graphics Controller (rev 07) 00:02.1 Display controller: Intel Corporation Mobile 4 Series Chipset Integrated Graphics Controller (rev 07) 00:03.0 Communication controller: Intel Corporation Mobile 4 Series Chipset MEI Controller (rev 07) 00:19.0 Ethernet controller: Intel Corporation 82567LM Gigabit Network Connection (rev 03) 00:1a.0 USB controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #4 (rev 03) 00:1a.1 USB controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #5 (rev 03) 00:1a.2 USB controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #6 (rev 03) 00:1a.7 USB controller: Intel Corporation 82801I (ICH9 Family) USB2 EHCI Controller #2 (rev 03) 00:1b.0 Audio device: Intel Corporation 82801I (ICH9 Family) HD Audio Controller (rev 03) 00:1c.0 PCI bridge: Intel Corporation 82801I (ICH9 Family) PCI Express Port 1 (rev 03) 00:1c.1 PCI bridge: Intel Corporation 82801I (ICH9 Family) PCI Express Port 2 (rev 03) 00:1c.3 PCI bridge: Intel Corporation 82801I (ICH9 Family) PCI Express Port 4 (rev 03) 00:1d.0 USB controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #1 (rev 03) 00:1d.1 USB controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #2 (rev 03) 00:1d.2 USB controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #3 (rev 03) 00:1d.7 USB controller: Intel Corporation 82801I (ICH9 Family) USB2 EHCI Controller #1 (rev 03) 00:1e.0 PCI bridge: Intel Corporation 82801 Mobile PCI Bridge (rev 93) 00:1f.0 ISA bridge: Intel Corporation ICH9M-E LPC Interface Controller (rev 03) 00:1f.2 SATA controller: Intel Corporation 82801IBM/IEM (ICH9M/ICH9M-E) 4 port SATA Controller [AHCI mode] (rev 03) 00:1f.3 SMBus: Intel Corporation 82801I (ICH9 Family) SMBus Controller (rev 03) 03:00.0 Network controller: Intel Corporation Ultimate N WiFi Link 5300
Bus 000 Device 001: ID 0000:0000 Bus 001 Device 001: ID 0000:0000 Bus 002 Device 001: ID 0000:0000 Bus 003 Device 001: ID 0000:0000 Bus 004 Device 001: ID 0000:0000 Bus 005 Device 001: ID 0000:0000 Bus 006 Device 001: ID 0000:0000 Bus 007 Device 001: ID 0000:0000 Bus 007 Device 002: ID 152d:0602 JMicron Technology Corp. / JMicron USA Technology Corp.
follow-up: 48 comment:47 by , 12 years ago
Ok. I've been writing a few quick and dirty stress test applications for Haiku. One of which is my memory exercising program. The memeater application has successfully triggered the PAE after only a few runs.
https://github.com/kallisti5/haikuStress
Code should be mostly self-exclamatory
comment:48 by , 12 years ago
Replying to kallisti5:
Ok. I've been writing a few quick and dirty stress test applications for Haiku. One of which is my memory exercising program. The memeater application has successfully triggered the PAE after only a few runs.
With which parameters did you run the test and on which hardware configuration?
comment:49 by , 12 years ago
When I generated the PAE exception I was doing 100 10 (create an area 100MB, write a small amount of data to it, delete it, 10 times) I also ran the test a few times before hand as well while testing the code.
The memory test could exercise the memory a lot more than it does already (maybe writing random data or something, I just ran out of time last night :)
I am 100% sure the application caused it. About mid-way through testing it KDL'ed
comment:50 by , 12 years ago
An interesting note.. I was hoping to reproduce this in qemu so I could grab the serial output when the kdl occured.. however this bug doesn't seem to affect qemu.
- qemu-system-i386 -m 6144 -hda haiku-nightly.image --enable-kvm -usbdevice tablet -smp 2
- ran 6 instances of memeater 1000 10
- watched memory usage go over 4GB and drop below it repeatedly for ~5 minutes.
No PAE crashes. This issue oddly seems tightly tied to real hardware.
comment:51 by , 12 years ago
7 concurrent terminals each running memeater 1024 100 in a loop fails to reproduce it on my i7 8GB system here. Bringing it up to 8 concurrent instances results in them randomly crashing due to failing to allocate the area, but no KDL after an hour of doing this continuously.
comment:52 by , 12 years ago
Replying to bonefish:
In your and Sean's comments above I actually read that it doesn't happen with only one CPU (one logical CPU). That would be consistent with the observations in #7904.
- Only occurs when system memory is > 4GB (PAE active)
AFAICT no one has confirmed yet that on the same machine the problem does cease to occur with PAE disabled. #7904 demonstrates that a KDL with the analogous stack trace is possible with 32 bit paging. I would consider it more likely that the issue occurs only on specific CPU architectures or models. It would be nice, if everyone who has tried to reproduce the issue could list their corresponding CPU models for positive and negative results.
Positive on dsuden's Asus F2A55M system:
CPU(s): 2x AMD A4 5300 Memory: 3.45 GiB total, 270.04 MiB used Haiku revision: hrev45824 Jul 5 2013 00:39:46 (BePC)
Not yet positive on my old thinkpad (Core2 Duo, 2 GB RAM); in my tests so far I always got the 'other' one, the messed-up slab allocator panic in #9858.
Also, it would be interesting to learn whether the machines that have the issue also test positive for #7904. Since that test is much quicker and more reliable, it would be more suitable for debugging.
Gotta try that, as well as disabling all CPUs but one.
comment:53 by , 12 years ago
| Cc: | added |
|---|
comment:54 by , 12 years ago
I'm still not sure how that could be related, but here the crash doesn't happen (or at least, not in noticeable amounts) when I'm not using my usb-attached SSD. I've been building webkit from the internal hard disk and everything is going fine, while trying to just git checkout it to the SSD will reliably trigger the panic.
Doing a checkout from the SSD to the internal drive also leads to a crash (this is writinto HD, reading from USB/SSD). Maybe the different I/O speed just triggers the bug more easily ? (either the slower transfer rate of USB, or the faster seek time of SSD).
comment:55 by , 11 years ago
| patch: | 1 → 0 |
|---|
comment:56 by , 11 years ago
6dee6653c26736f534abdda6886219ab56503533 of the PM branch addresses one cause. There may be others. Please test and report whether this fix helps in your case.
comment:57 by , 11 years ago
Just a reminder: In hrev46113 the PM branch was merged into the master. So that and any later revision contains the change referred to in the previous comment. Everyone who could fairly easily reproduce the problem, please report whether you still can. Thanks!
comment:59 by , 11 years ago
Regarding dsuden and I, being stuck on all my leads I've asked him to use the nuclear option and outright send me a video of him ripping CDs (!) so that I see exactly what he does to trigger this KDL (and sometimes the corrupted slab KDL too) since he has a knack for triggering them quick. When all else fails, try brute force, right ??
We'll use the same Asus motherboard, the same haiku hrev (the buildbot resumed working so we'll probably use hrev46425), the same version of lame, same version of the ripping app, and -- hopefully -- I'll replicate his every mouse moves and clicks from observing his video footage. We won't have the same audio CDs to rip, but if the bug depends on THAT I'm ready to throw my keyboard through the window and follow it afterwards :o)
I'll ask him to start his video after a fresh warm boot, to ensure consistency and ease of replicability. Any other procedural suggestions, post them here to me...
If we are successful we might finally get a reproducible case in the greedy hands of you haiku devs (fingers crossed.. again)
Edit to add: No objection from me on closing this until proven otherwise; also, I should have mentionned http://dev.haiku-os.org/ticket/9858#comment:9 and comment:52 to make my comment clearer.
comment:60 by , 11 years ago
@ttcoder: Please note that this is not #9858 (your CD ripping page fault(s)). It's about an assert being triggered, for which a fix has been in master since hrev46113. The fix is at least good for one of the causes (the one I encountered). There may be others and I'd like to know, if anyone has encountered this KDL in the meantime, or if this ticket can be closed.
follow-up: 62 comment:61 by , 11 years ago
I get this on every boot (well, 3 out of 3 tries) from the latest gcc2h hrev46452 Haiku ISO image. I can provide a screenshot if needed
comment:62 by , 11 years ago
Replying to kallisti5:
I get this on every boot (well, 3 out of 3 tries) from the latest gcc2h hrev46452 Haiku ISO image. I can provide a screenshot if needed
Yes, please. It might also be helpful to know whether it's always the same virtual address and/or pte address.
Reproducibility is awesome. If you're willing to work on tracking this down, I could prepare some kernel tracing. Will probably take several iterations.
comment:63 by , 11 years ago
Sorry for the delay, just saw this note. I'll boot from a recent CD some time this evening and get a screenshot of the kdl.
There is good news however! I haven't seen these PAE crashes lately (other than while booting from the ISO). All of the PAE crashes during os use have been replaced by the crashes in #10279 I guess application crashes are better than kernel crashes :-)
comment:64 by , 11 years ago
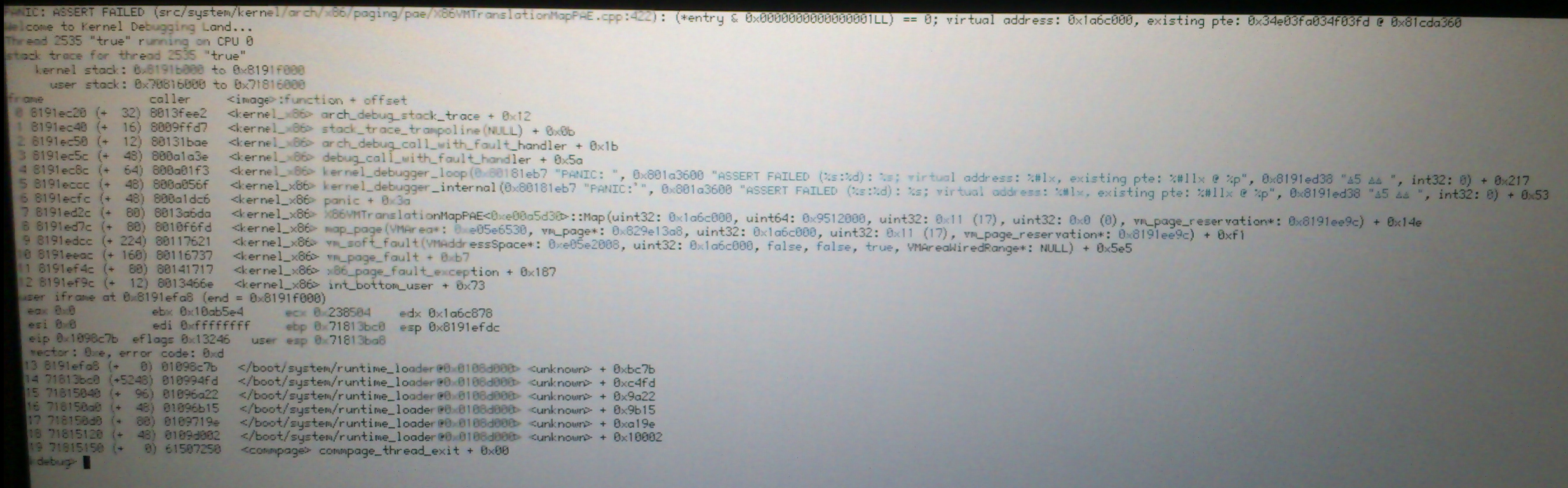
I'll join the KDL club with:
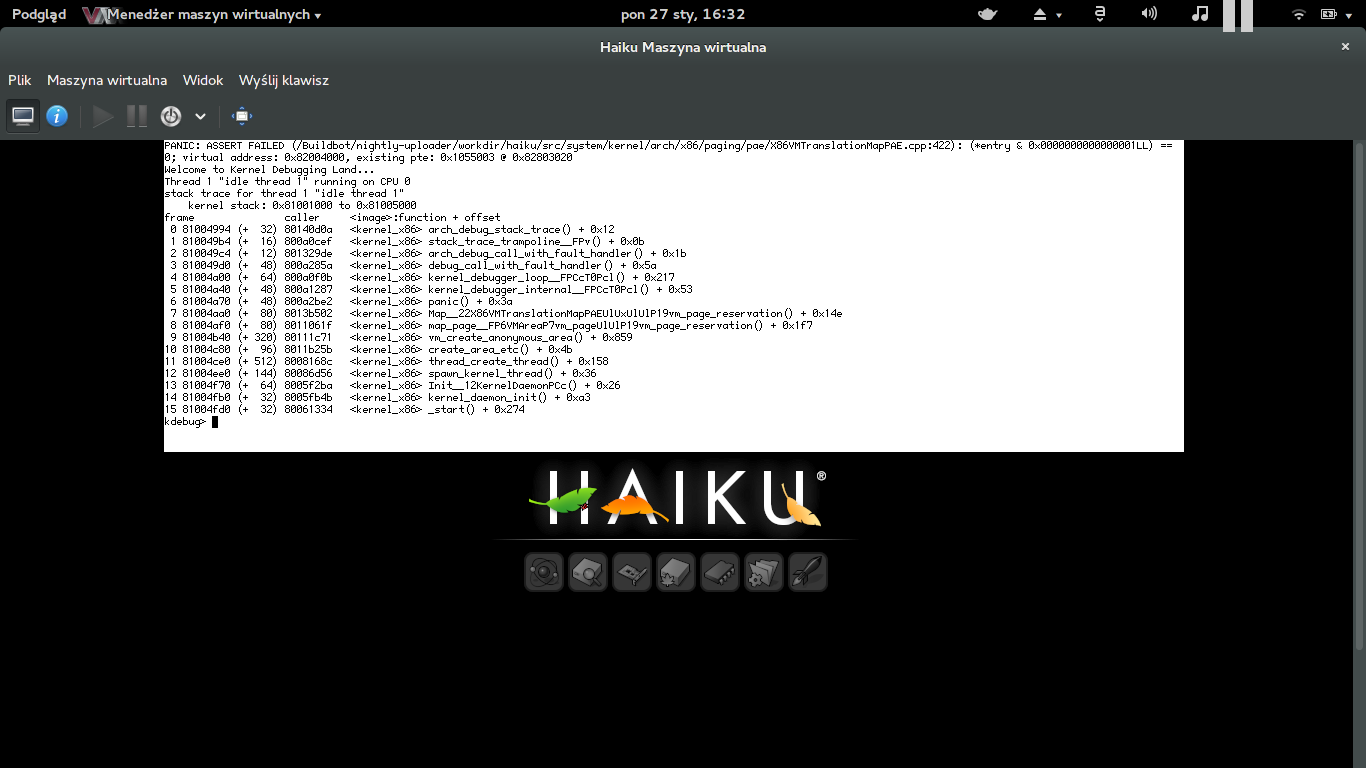
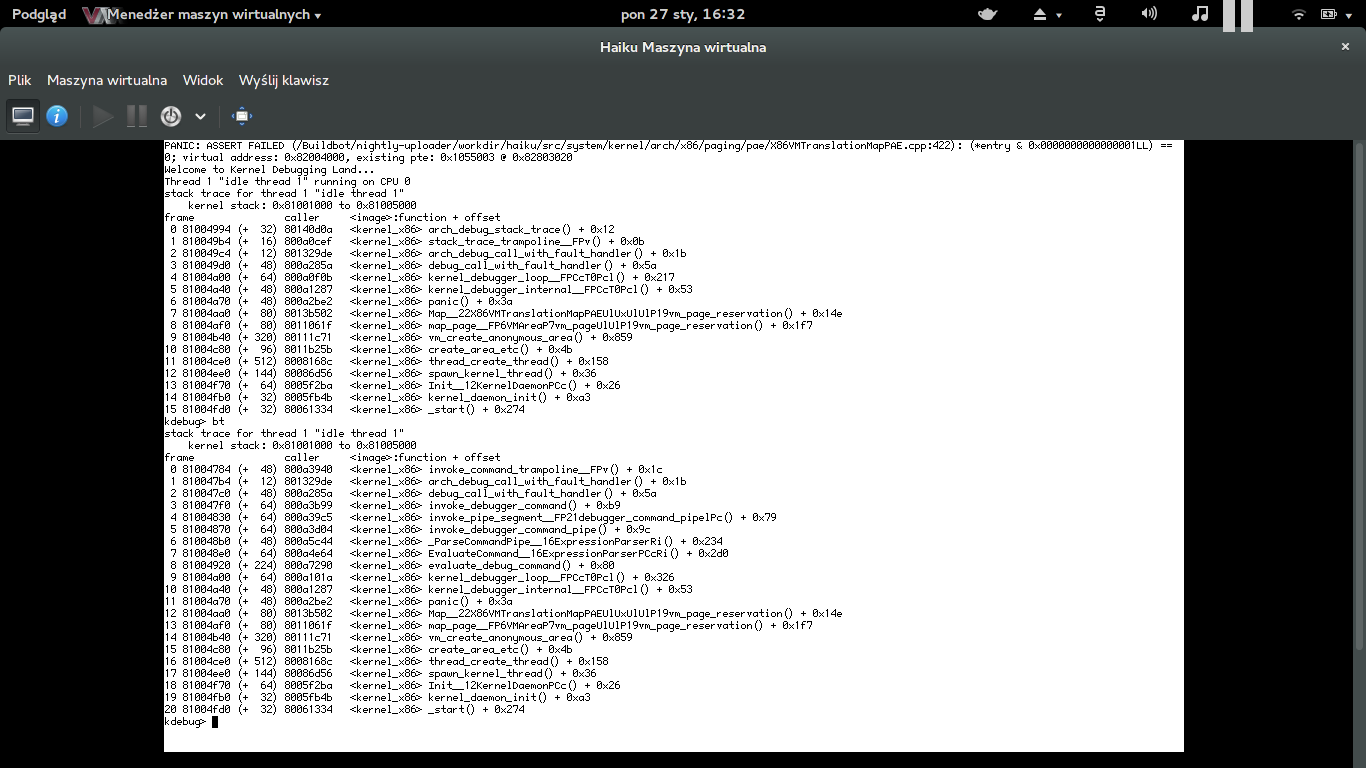
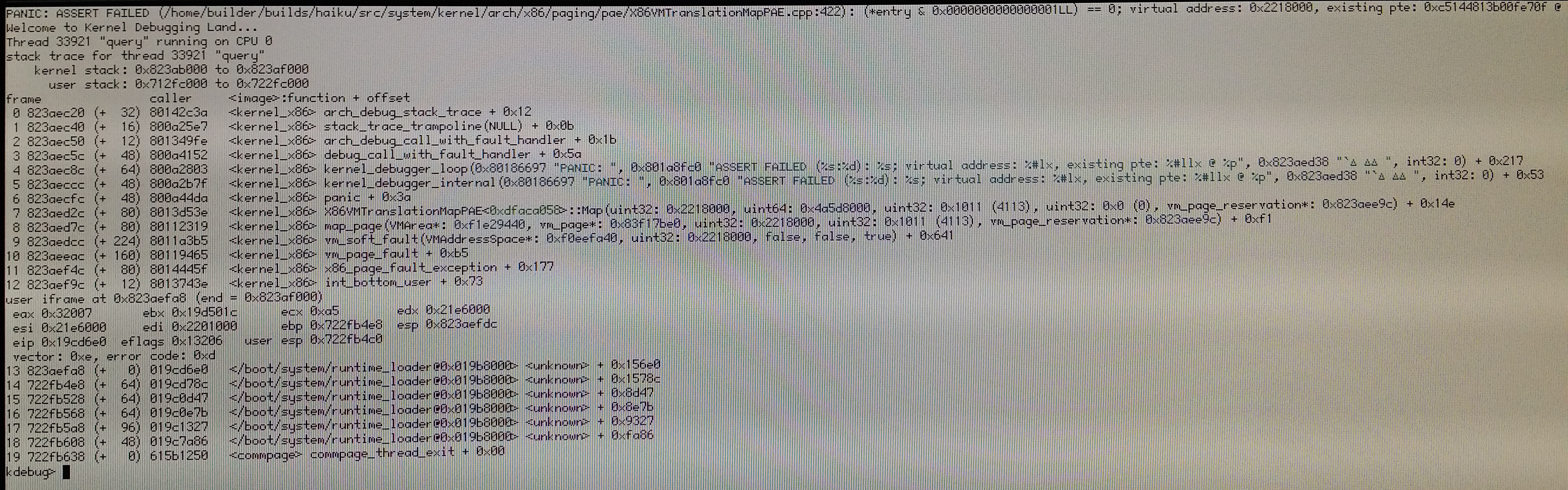
PANIC: ASSERT FAILED (src/system/kernel/arch/x86/paging/pae/X86VMTranslationMapPAE.cpp:422: (*entry & 0x0000000000000001LL) == 0; virtual address: 0x1a6c000, existing pte: 0x34e03fa034f03fd @ 0x81cda360
This is with hrev46690 after restarting the media services from the Media preferences a few times. Core2Duo, 2gb ram. pretty un-stressed system. Attached the KDL screenshot.
by , 11 years ago
comment:65 by , 11 years ago
I got the same error as humdinger using a 4 CPUs virtual box machine with nightly ISO image hrev46706. The problem is always reproducible.
PANIC: ASSERT FAILED (/Buildbot/nightly-uploader/workdir/haiku/src/system/kernel/arch/x86/paging/pae/X86VMTranslationMapPAE.cpp:422): (*entry & 0x0000000000000001LL) == 0; virtual address: 0x82009000, existing pte: 0x105c003 @ 0x82801048
Configuring the same virtual machine with 2 CPUs give me a different error, at a later boot stage :
PANIC: ASSERT FAILED (/Buildbot/nightly-uploader/workdir/haiku/src/system/kernel/scheduler/scheduler_thread.h:397): system_time() - fWentSleep >= 0
See attached serial trace from the virtual machine
comment:66 by , 11 years ago
When you say the issue is always reproducible with 4 CPUs, what's your exact VM configuration (RAM mainly) and what do you have to do exactly?
The latter seems to be a newly introduced scheduler issue and I suspect that's what 59b9b52 (part of hrev46718) addresses.
comment:67 by , 11 years ago
The VM is configured with standard parameters (see attached .vbox file for details). I have tested different RAM setup from 512 Mo to 8192 Mo with the same result. I have the same problem with 3 or more CPUs in the VM.
There is a 10 Go empty disk file attached to the machine and the nightly ISO from which i boot.
The machine is hosted on a linux host (ubuntu) on a core i7 (4 CPUs / 8 threads).
For the second problem, i have already linked the corresponding trace to the other bug (#8345). I will test it later with hrev46720.
by , 11 years ago
| Attachment: | Haiku_r46706_janvier_2014.vbox added |
|---|
comment:68 by , 11 years ago
And what do you have to do to reproduce the issue? Just boot or anything else?
comment:70 by , 11 years ago
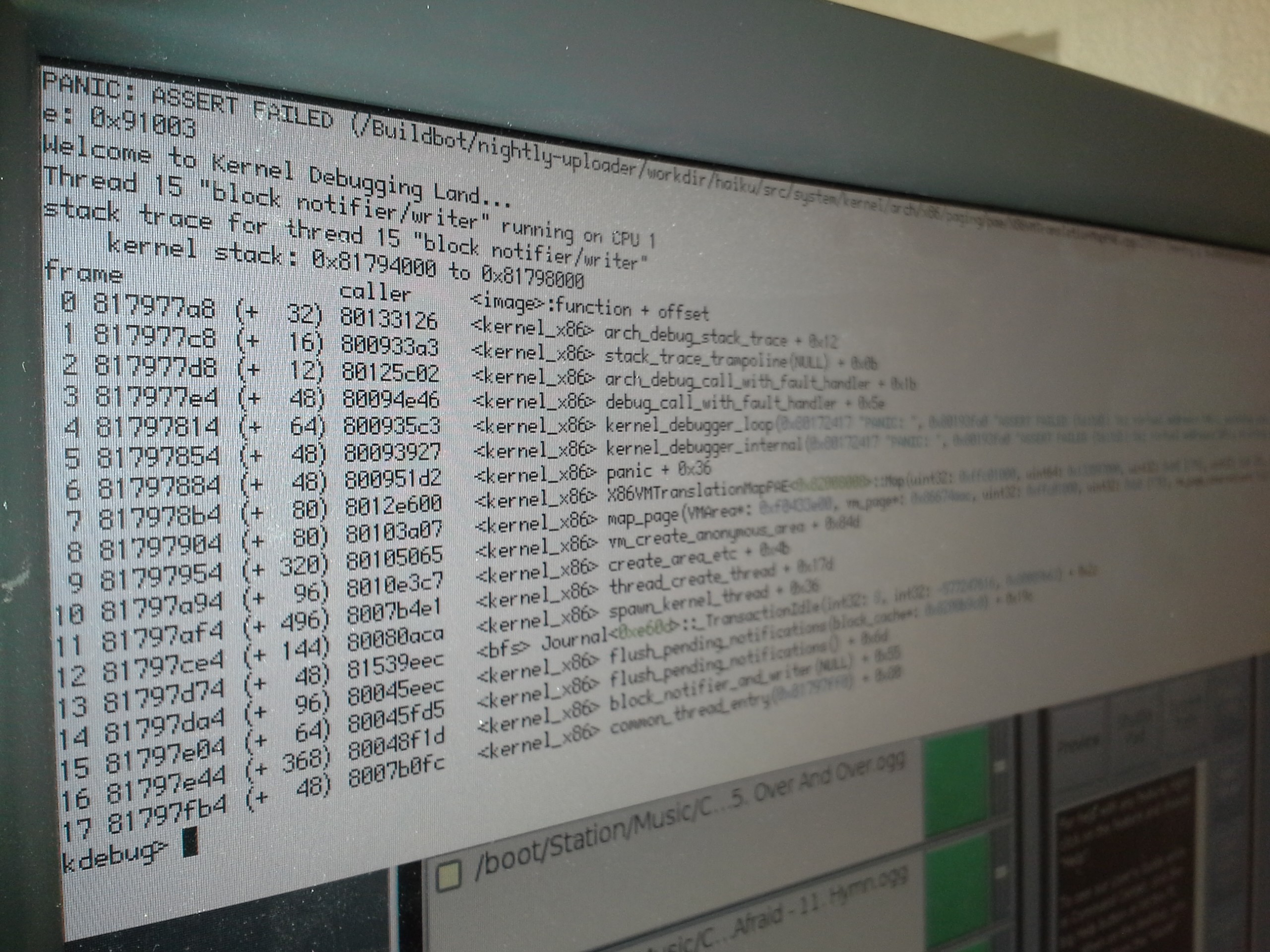
I can reproduce this issue simply by booting from a usb stick on my AMD hardware. attached screen shot attachment, its the best I could do with my crappy camera phone.
by , 11 years ago
| Attachment: | xaxes_2014-01-27_16_32_05.png added |
|---|
by , 11 years ago
| Attachment: | xaxes_2014-01-27_16_32_16.png added |
|---|
by , 11 years ago
| Attachment: | kvm_setup.txt added |
|---|
comment:71 by , 11 years ago
Reported to me by user xaxes, because registering on Trac don't work. hrev46767
This bug occurs, when is more than one processor.
comment:72 by , 11 years ago
The scheduler merge indeed introduced a problem that resulted in an assertion fail just as described in this ticket early at boot. This should be fixed in hrev46779.
follow-up: 74 comment:73 by , 11 years ago
This bug did exist pre-scheduler. Would be interesting to see if it still occurs on the pre-scheduler hardware.
I haven't seen it on recent AMD hardware, but I originally saw it on a Pentium 4 Dell Optiplex. (I can't really smp load test though due to #10279)
comment:74 by , 11 years ago
Replying to kallisti5:
This bug did exist pre-scheduler.
Note that this isn't/hasn't been just one bug. The assertion is triggered on an inconsistency in the page tables, which can have different causes. I fixed one five months ago, with at least another one remaining, and apparently the scheduler branch merge introduced a new one. Unfortunately we can't discriminate the causes just from the assertion message.
comment:75 by , 11 years ago
| Milestone: | R1/beta1 → R1/alpha5 |
|---|---|
| Priority: | critical → high |
by , 11 years ago
| Attachment: | IMG_20140605_164833.jpg added |
|---|
Customer report from earlier this week, he's still running hrev46104 so might be a symptom already fixed by bonefish in PM or otherwise not relevant
comment:76 by , 11 years ago
I just saw this on a VM running on Intel hardware. (x86 gcc4, hrev47380)
kdebug> message
PANIC: ASSERT FAILED (/Buildbot/nightly-uploader/workdir/haiku/src/system/kernel/arch/x86/paging/pae/X86VMTranslationMapPAE.cpp:422): (*entry & 0x0000000000000001LL) == 0; virtual address: 0xb63000, existing pte: 0xe5bb6465c880ba3 @ 0x82153b18
kdebug> bt
stack trace for thread 10063 "bash"
kernel stack: 0xcdeec000 to 0xcdef0000
user stack: 0x70dcd000 to 0x71dcd000
frame caller <image>:function + offset
0 cdeef9f0 (+ 32) 80093763 <kernel_x86> invoke_command_trampoline(void*: 0xcdeefa64) + 0x15
1 cdeefa10 (+ 12) 80115b9e <kernel_x86> arch_debug_call_with_fault_handler + 0x1b
2 cdeefa1c (+ 48) 800913f3 <kernel_x86> debug_call_with_fault_handler + 0x4e
3 cdeefa4c (+ 64) 8009391d <kernel_x86> invoke_debugger_command + 0xc8
4 cdeefa8c (+ 64) 80093a36 <kernel_x86> invoke_pipe_segment(debugger_command_pipe*: 0x37, int32: 8132, char*: NULL) + 0x71
5 cdeefacc (+ 48) 80093afd <kernel_x86> invoke_debugger_command_pipe + 0x89
6 cdeefafc (+ 64) 8009787b <kernel_x86> ExpressionParser<0xcdeefbb8>::_ParseCommandPipe(int&: 0xcdeefbb4) + 0xc9f
7 cdeefb3c (+ 80) 8009d761 <kernel_x86> ExpressionParser<0xcdeefbb8>::EvaluateCommand(char const*: 0x801aa020 "bt", int&: 0xcdeefbb4) + 0xc09
8 cdeefb8c (+ 208) 8009e7d1 <kernel_x86> evaluate_debug_command + 0x8a
9 cdeefc5c (+ 80) 80092281 <kernel_x86> kernel_debugger_loop(char const*: 0x2 "<???>", char const*: 0x801aeca8 "����h�~�", char*: 0xcdeefcec, int32: -2146884601) + 0x2e7
10 cdeefcac (+ 64) 80092432 <kernel_x86> kernel_debugger_internal(char const*: 0x2 "<???>", char const*: 0x2 "<???>", char*: 0xcdeefd0c, int32: -2146884101) + 0x11e
11 cdeefcec (+ 32) 80092616 <kernel_x86> panic + 0x3a
12 cdeefd0c (+ 96) 8011f14c <kernel_x86> X86VMTranslationMapPAE<0xcf61caa8>::Map(uint32: 0xb63000, int64: 187289600, uint32: 0x55 (85), uint32: 0x0 (0), vm_page_reservation*: 0xcdeefe38) + 0x134
13 cdeefd6c (+ 80) 800f7472 <kernel_x86> map_page(VMArea*: 0x55, vm_page*: 0xcdeefe38, uint32: 0x0 (0), uint32: 0x0 (0), vm_page_reservation*: 0xcccccccc) + 0xd0
14 cdeefdbc (+ 224) 800fdb1f <kernel_x86> vm_soft_fault(VMAddressSpace*: 0x1, uint32: 0x1 (1), false, false, true, vm_page**: 0x8, VMAreaWiredRange*: 0x1) + 0xbf3
15 cdeefe9c (+ 160) 8010233e <kernel_x86> vm_page_fault + 0x2ab
16 cdeeff3c (+ 96) 801245ee <kernel_x86> x86_page_fault_exception + 0x163
17 cdeeff9c (+ 12) 801181de <kernel_x86> int_bottom_user + 0x73
user iframe at 0xcdeeffa8 (end = 0xcdef0000)
eax 0x0 ebx 0xc1cd6c ecx 0x71dcb1ac edx 0x61ad2114
esi 0x0 edi 0x71dcb1e0 ebp 0x71dcb1b8 esp 0xcdeeffdc
eip 0xb63980 eflags 0x13212 user esp 0x71dcb19c
vector: 0xe, error code: 0x1d
18 cdeeffa8 (+ 0) 00b63980 <libroot.so> _init (nearest) + 0x1734
19 71dcb1b8 (+ 80) 024c051e <_APP_> make_child + 0xaa
20 71dcb208 (+ 256) 0249f495 <_APP_> command_substitute + 0x126
21 71dcb308 (+ 192) 024a39ed <_APP_> expand_string (nearest) + 0x2af4
22 71dcb3c8 (+3472) 024a4b6a <_APP_> expand_string (nearest) + 0x3c71
23 71dcc158 (+ 32) 024a5a79 <_APP_> expand_string (nearest) + 0x4b80
24 71dcc178 (+ 64) 024a5db1 <_APP_> expand_string_assignment + 0x70
25 71dcc1b8 (+2288) 024a080e <_APP_> string_quote_removal (nearest) + 0x4ee
26 71dccaa8 (+ 96) 024a097c <_APP_> string_quote_removal (nearest) + 0x65c
27 71dccb08 (+ 16) 024a0c89 <_APP_> do_word_assignment + 0x13
28 71dccb18 (+ 112) 024a6604 <_APP_> expand_word (nearest) + 0x168
29 71dccb88 (+ 16) 024a6d77 <_APP_> expand_words + 0x13
30 71dccb98 (+ 320) 0248d108 <_APP_> execute_command_internal + 0x11c9
31 71dcccd8 (+ 96) 024e4c35 <_APP_> parse_and_execute + 0x446
32 71dccd38 (+ 64) 02483cd0 <_APP_> xparse_dolparen (nearest) + 0x6b0
33 71dccd78 (+ 304) 0248559d <_APP_> main + 0x1216
34 71dccea8 (+ 64) 024799eb <_APP_> _start + 0x50
35 71dccee8 (+ 48) 00e7b630 </boot/system/runtime_loader@0x00e6a000> <unknown> + 0x11630
36 71dccf18 (+ 0) 61ad2250 <commpage> commpage_thread_exit + 0x00
comment:77 by , 11 years ago
Environment: 4GB of RAM, running in kvm (libvirt) on a Intel i5
kdebug> in_context 10063 dis -b 10 0x00b6394b: e920e9ffff jmp 0xb62270 0x00b63950: ffa3c0050000 jmp 0x5c0(%ebx) 0x00b63956: 68680b0000 push $0xb68 0x00b6395b: e910e9ffff jmp 0xb62270 0x00b63960: ffa3c4050000 jmp 0x5c4(%ebx) 0x00b63966: 68700b0000 push $0xb70 0x00b6396b: e900e9ffff jmp 0xb62270 0x00b63970: ffa3c8050000 jmp 0x5c8(%ebx) 0x00b63976: 68780b0000 push $0xb78 0x00b6397b: e9f0e8ffff jmp 0xb62270 0x00b63980: ffa3cc050000 jmp 0x5cc(%ebx) <<< 0x00b63986: 68800b0000 push $0xb80 0x00b6398b: e9e0e8ffff jmp 0xb62270 0x00b63990: ffa3d0050000 jmp 0x5d0(%ebx) 0x00b63996: 68880b0000 push $0xb88 0x00b6399b: e9d0e8ffff jmp 0xb62270 0x00b639a0: ffa3d4050000 jmp 0x5d4(%ebx) 0x00b639a6: 68900b0000 push $0xb90 0x00b639ab: e9c0e8ffff jmp 0xb62270 0x00b639b0: ffa3d8050000 jmp 0x5d8(%ebx) kdebug> kdebug> mapping 0x00b63980 10063 page directory: 0xe454e000 (PDPT[0]) page directory entry 5 (0xe454e028): 0x19a4f027 access: present writable user executable caching: flags: accessed page table: 0x19a4f000 page table entry 355 (phys: 0x19a4fb18): 0xe5bb6465c880ba3 access: present writable executable caching: PAT flags: accessed address: 0xbb6465c880000 kdebug> mapping 0xb63000 page directory: 0xe454e000 (PDPT[0]) page directory entry 5 (0xe454e028): 0x19a4f027 access: present writable user executable caching: flags: accessed page table: 0x19a4f000 page table entry 355 (phys: 0x19a4fb18): 0xe5bb6465c880ba3 access: present writable executable caching: PAT flags: accessed address: 0xbb6465c880000 kdebug> page_stats page stats: total: 1179392 active: 5183 (busy: 0) inactive: 16059 (busy: 0) cached: 273643 (busy: 0) unused: 131162 (busy: 0) wired: 110978 (busy: 0) modified: 20 (busy: 0) free: 634253 clear: 8094 unreserved free pages: 642344 unsatisfied page reservations: 0 mapped pages: 111433 longest free pages run: 5080 pages (at 637167) longest free/cached pages run: 5080 pages (at 637167) waiting threads: free queue: 0x801b6b00, count = 634253 clear queue: 0x801b6b18, count = 8094 modified queue: 0x801b6ad0, count = 20 (0 temporary, 0 swappable, inactive: 0) active queue: 0x801b6aa0, count = 5183 inactive queue: 0x801b6ab8, count = 16059 cached queue: 0x801b6ae8, count = 273643
comment:78 by , 10 years ago
There is a certain chance that hrev48117 improves the situation. Before hrev48108 the pgtables array in the x86 kernel_archs structure would overflow, when the boot loader needed more than 4 page tables. Ticket #11377 shows that this can actually happen. The field after pgtables is virtual_end which is used (among other things) for unmapping address ranges used in the boot loader but no longer needed in the kernel. Overwriting this field could therefore cause some of those page table entries to be left over and later trigger the assert this ticket is about.
Long story short, if you could reproduce the assert, please leave a comment, whether you still can.
comment:79 by , 10 years ago
comment:80 by , 10 years ago
I still have the virtual machine that trigger my test case. I just checked that i am still able to reproduce the initial problem. I will check again when the nightly ISO including this change will be available.
comment:81 by , 10 years ago
comment:82 by , 10 years ago
Finally checked with hrev48123 ISO : it does not crash anymore.
Well done !
comment:83 by , 10 years ago
| Resolution: | → fixed |
|---|---|
| Status: | assigned → closed |
Thanks! Closing. I have the feeling that we might see this ASSERT again. After all, it catches inconsistencies in the page tables which can (and did) have different causes. Since this ticket has become awfully long, I'd prefer a new ticket to keep track of remaining bugs should any still remain.
comment:84 by , 10 years ago
| Milestone: | R1/alpha5 → R1/beta1 |
|---|
by , 10 years ago
| Attachment: | 20150109_135535.jpg added |
|---|
Still seeing that KDL in Haiku shredder 1 hrev48411 Dec 1 2014 14:26:35 BePC x86 Haiku
comment:85 by , 10 years ago
Quoting bonefish:
Since this ticket has become awfully long, I'd prefer a new ticket to keep track of remaining bugs should any still remain.
Please do this and open a new ticket. While the assertion you hit is the same, the root cause is likely different, and it's better to start fresh on investigating it.
Haiku: hrev43717 gcc4 hybrid not dirty.